不理解Zookeeper一致性原理,谈何异地多活改造

作者介绍
陈东明,饿了么北京技术中心架构组负责人,负责饿了么的产品线架构设计及基础架构研发工作。曾任百度架构师,负责百度即时通讯产品的架构设计。具有丰富的大规模系统构建和基础架构的研发经验,善于复杂业务需求下的大并发、分布式系统设计和持续优化。
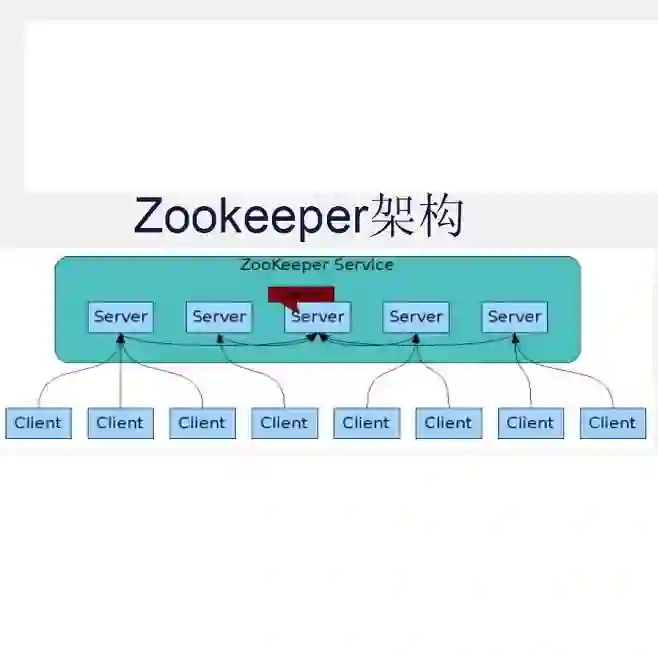
在2017年饿了么做异地多活建设之时,我的团队承担了Zookeeper的异地多活改造。在此期间,我听到了关于Zookeeper一致性的两种不同说法:
一种说法是Zookeeper是最终一致性,由于多副本,以及保证大多数成功的Zab协议,当一个客户端进程写入一个新值,另一个客户端进程不能保证马上就会读到,但能保证最终会读到这个值;
另一种说法是Zookeeper的Zab协议类似于Paxos协议,并且提供了强一致性。
每当听到这两种说法,我都想纠正一下——不对,Zookeeper是顺序一致性(sequential consistency)。但解释起来比较复杂,需要一篇长文来说明,于是就有了本文,下面就和大家一起讨论下我的看法。
什么是sequetial consistency
从Zookeeper的文档中我们可以看到,里面明确写出它的一致性是sequential consistency。(详细参见Zookeeper官方文档[1])
那么,什么是sequential consistency呢?
sequential consistency是Lamport在1979年首次提出的。(详细参见他的这篇论文:How to make a multiprocessor computer that correctly executes multiprocess programs)
论文中定义,当满足下面这个条件时就是sequential consistency:
the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program.
这段英文定义很晦涩(这是Lamport大神的一贯风格,严谨但晦涩,Paxos协议也是如此),我第一次看到时的感觉是:“这是什么鬼?”为啥每个英文单词我都认识,但就是不知道他在说什么?第一次看到这句话和我有同感的小伙伴留个言吧~
后文我再把这段英文定义翻译成中文,现在我们先看看这篇论文的标题和定义中出现的一个关键词,来说明一下sequential consistency的应用范围。
论文的标题和定义中包含“multiprocessor”这个词,multiprocessor是多核处理器的意思。从这个关键字来看,sequential consistency是用来定义多核处理器和跑在多核处理器上的程序的一个特性。Lamport这篇论文的标题可以翻译成:“如何让具有多核处理器的计算机正确执行多进程程序”,也就是说如果一个多核处理器具有sequential consistency的特性,这个多核处理器就可以正确运行,后面我会解释这个正确运行是什么意思(也就是本文后面讲到的sequential consistency的作用)。
从这个标题我们还可以看出,sequential consistency应该是个并发编程(concurrent programming)领域的概念。但我们现在常常在分布式系统领域讨论sequential consistency,比如本文主要讨论的Zookeeper(Zookeeper很明显是一个分布式系统)的一致性。实际上,多核处理器上运行的多个程序,其实也是一种分布式系统(Lamport在他的这篇 Time, Clocks, and the Ordering of Events in a Distributed System 分布式系统的开山之作中也阐述了这个观点)。所以虽然sequential consistency最早在并发编程中提出,但是它可以应用在分布式系统中,比如本文讨论的Zookeeper这种分布式存储系统。另外一个比较重要的Linearizability(线性一致性),也是在并发编程中最早提出的,目前也被广泛应用在分布式系统领域中。
接下来我们尝试翻译一下上文那段晦涩的定义。做这段翻译让我找到了上学时做阅读理解的感觉,我先不直接翻译,因为就算我把它翻译成中文,估计很多人还是会有“为啥每个中文字我都懂,还是不知道在说什么”的感觉。
首先,我来解释一下个别的词。首先,“any execution”是什么意思?你有多个程序(program)在多核处理器上运行,例如你有两个程序,第一个程序叫P1,它的代码如下:
P1_write(x);
P1_read(y);
第二个程序叫P2,代码如下:
P2_write(u);
P2_read(v);
从理论上来讲,两个程序运行在两个独立处理器的核上,有多少种执行的可能?我列举其中几种来举例说明。
第一种:
P1---write(x)--------read(y)--------
P2-----------write(u)-------read(v)-
第二种:
P1----------write(x)-read(y)--------
P2--write(u)----------------read(v)-
第三种:
P1---read(y)----------write(x)------
P2-----------write(u)---------read(v)-
我们有24种可能的执行顺序,也就是这四个操作任意的排列组合,也就是4!=24。类似第一种和第二种这样的可能性很好理解。为什么会出现像第三种这样的可能的执行呢?那是因为就算在同一个程序中,由于处理会有多级的缓存,以及处理器中coherence的存在,虽然你的程序中是先write后read,在内存中真正生效的顺序,也有可能是先read后write。
其实还会出现类似下面这样的执行,两个操作在两个处理器上同时执行。
P1--write(x)-read(y)--------
P2--write(u)--------read(v)-
如果加上同时运行的这种情况,那就有更多种可能性。我的算数不太好,这里就不继续算下去了,因为到底有多少个不重要,重要的是要知道有很多种可能性。那么定义中的“any execution”,就是指任意一种可能的执行,在定义中也可以理解为所有的这些可能的执行。
接着我们再来解释一个词——“sequential order”。什么叫sequential order?我们来翻一下英语词典(感觉更像在做阅读理解了)。
sequential:连续的;相继的;有顺序的
order:命令;顺序;规则;[贸易] 定单
sequential order——有顺序的顺序,这又是什么鬼?
其实sequential是有一个接一个的意思,在处理器的这种上下文中,sequential就是指操作(operartion)一个接一个地执行,也就是顺序执行,并且没有重叠。order是指经过一定的调整,让某样东西按照一定的规则变得有序。比如,在算法中的排序算法就是ordering,就是让数组这个东西按照从大到小或从小到大的规则变得有序。那么sequential order就是指让操作(operation)按照一个接一个这样的规则排列,并且没有重叠。
再说回上文的例子,如果把四个操作,按一个接一个的规则排列,这时就可以得到4!的排列组合个可能的排列(order),同样的,有多少个不重要。
比如:
P1_write(x);P1_read(y);P2_write(u);P2_read(v);
P1_read(y);P1_write(x);P2_write(u);P2:read(v);
P2_write(u);P2_read(v);P1_read(y);P1:write(x);
我这里只列举其中三个,其他的大家可以自己排一下。
重点来了,其实sequential order就是让这四个操作按照一个接一个的顺序执行,并且没有重叠。注意这个排列不是真实的执行,真实的执行是any execution,这里说的是逻辑上的假设,也就是为什么定义有一个as if。
做了这么多的铺垫,下面我们开始翻译定义中的第一句话:
任意一种可能的执行效果,与所有的处理器上的某一种操作按照顺序排列执行的效果是一样的。
注意,some在这里是指“某一种”的意思,不是一些,因为order是单数(真的是在做阅读理解)。
这句话的意思就是说,一个处理器要满足这个条件,就只能允许满足这个条件的那些可能的执行存在,其他不满足的可能的执行都不会出现。
从第一句话中我们可以看出,一种多核处理器要想满足sequential consistency,那么多个程序在多个核运行效果“等同”于在一个核上顺序执行所有操作的效果是差不多的。如果这样的话,其实多核的威力基本就消失了。所以无论是从Lamport写这篇论文的1979年,还是现在,没有任何一个现实的多核处理器实现了sequential consistency。
那么,为什么Lamport大神提出这样一个不现实的概念呢?(要注意Lamport写这篇论文时,并没有把它引申到分布式系统领域,就是针对多核处理器、并发编程领域提出的)我们稍后再论述。
这里还要注意的一点是,在我的翻译里用了“效果”一词,但实际上英文原文中用的是“result(结果)”一词。那效果和结果有什么区别吗?我们解释一下什么叫执行结果。
不管是任何真实的执行,还是某种经过顺序排序后的假设执行,程序会产生一定的结果,比如print出来的结果(result)。实际上定义中说的是结果一样。如果定义中用“效果”的话,那这个定义就只是一个定性的定义,如果用“结果”的话,那这个定义就是一个定量的定义。定量的,也就是说可以通过数学证明的。从这点我们可以看出,大神就是不一样,任何理论都是可以通过数学证明为正确的。本文后面还会提到证明的事情,我们这里再卖个关子。
到这里,关于定义的第一句,更准确的翻译就是:
任意一种可能的执行的结果,与某一种所有的处理器上的操作按照顺序排列执行的结果是一样的。
这里我们还要注意一点,结果一样就意味着,如果有人真的要实现一种sequential consistency的多核处理器的话,因为要保证结果一样,所以他是有一定的空间来优化,而不会完全是一个核顺序执行的效果。但是估计这种优化也是非常有限的。
好了,终于把最难的第一句话解释完了,大家可以松口气,第二句就非常简单了。我们还是先解释第二句种出现的一个词——“sequence”。刚刚解释过的sequential order是顺序排序(就是按一个接一个排序),其实这是一个动作,动作会产生结果,它的结果产生了一个操作(operation)的队列。第二句中出现的sequence就是指这个操作(operation)的队列。
好,那第二句的翻译就是:
并且每个独立的处理器的操作,都会按照程序指定的顺序出现在操作队列中。
也就是说如果程序里是先write(x);后read(y);,那么只有满足这个顺序的操作队列是符合条件的。这样,我们刚刚说的很多可能的执行就少了很多,这里我也就不计算少了多少,还是那句话,数量不重要,反正是有,而且变少了。
那么第二句话意味着什么?意味着如果一个多核处理器实现了sequential consistency,那这种多核处理器基本上就告别自(缓)行(存)车了。这里我还要继续卖关子,连缓存这种最有效提高处理器性能的优化都没了,大神为什么要提出这个概念?
好了,到这里我们可以把两句翻译合起来,完整看一下:
任意一种可能的执行的结果,与某一种所有的处理器上的操作按照顺序排列执行的结果是一样的,并且每个独立的处理器的操作,都会按照程序指定的顺序出现在操作队列中。
从这个定义中,我们可以看出,此概念的核心就是sequential order,这也就是为什么Lamport老爷子把这种一致性模型称之为sequential consistency。可以说这个命名是非常贴切的,不知道这种贴切对于以英语为母语的人来说是不是更好理解一些,应该不会出现“顺序的顺序是什么鬼”这种情况。如果你看完本文,也觉得sequential很贴切的话,那就说明我讲清楚了。
接下来我们举个具体的例子,再来说明一下:
execution A
P0 writex=1-------------------------------
P1 -------write x=2----------------------
P2 -----------------read x==1--read x==2
P3 -----------------read x==1--read x==2
sequetial order: P0_write x=1,P3_read x==1,P4_read x==1,P1_write x=2,P3_read x==2,P4_read x==2
execution B
P0 write=1-------------------------------
P1 -------write x=2----------------------
P2 -----------------read x==2--read x==1
P3 -----------------read x==2--read x==1
sequetial order: P1_write x=2,P3_read x==2,P4_read x==2,P0_write x=1,P3_read x==1,P4_read x==1
execution C
P0 write=1-------------------------------
P1 -------write x=2----------------------
P2 -----------------read x==1--read x==2
P3 -----------------read x==2--read x==1
sequetial order: 你找不出一个符合定义中2个条件的一种order。
所以说如果一个多核处理器只允许execution A和B出现,不允许C出现,那么这个多核处理器就是sequetial consistency的。如果它允许C出现,那它就不是sequetial consistency。
到这里,我们已经完整地解释完什么是sequetial consistency。但是,细心的朋友可能会问,如果你的program是多线程的程序怎么办?那我们再把定义中最后的一个细节解释一下:program这个词。
program是指可以直接运行在处理器上的指令序列。这个并不是program的严格定义,但是我要指出的是这个program是在操作系统都没有的远古时代就存在的概念,在上文的定义中prgram就是指那个时代的program。
这个program里没有进程、线程的概念,这些概念都是在有了操作系统之后才出现的。因为没有操作系统,也没有内存空间的概念。不像我们现在所说的程序(program),不同的程序有自己独立的内存地址空间。我们这里,内存(memory)对于不同的program来说是shared。另外,需要注意的是program可以用来说明各种程序,不管你是操作系统内核,还是应用程序,都适用。
sequential consistency
是分布式领域的概念
刚刚我们说了,sequential consistency虽然是针对并发编程领域提出的,但实际上它是分布式领域的概念,特别是分布式存储系统。在 Distributed system: Principles and Paradigms (作者Andrew S.Tanenbaum, Maarten Van Steen),作者稍微修改了一下Lamport的定义,让这个定义更贴近分布式领域中的概念,我们来看一下作者是怎么改的:
The result of any execution is the same as if the (read and write) operations by all processes on the data store were executed in some sequential order and the operations of-each individual process appear in this sequence in the order specified by its program.
作者把processor换成了process,并且加了on the data store这个限定,在Lamport的定义里没有这个限定,其实默认指的是memory(内存)。process就是指进程,以Zookeeper为例,就是指访问Zookeeper的应用进程。program也不是那么底层概念,也是基于操作系统的应用程序了。
sequential consistency的作用
好了,下面该揭晓我上面卖的两个关子了。在Lamport的论文中,给出了一个小例子,如下:
process 1
a := 1;
if b = 0 then critical section:
a := 0
else ... fi
process 2
b := 1;
if a = 0 then critical section:
b := 0
else ... fi
Lamport在论文中说,如果一种多核处理满足sequential consistency的条件,那么最多只有一个程序能够进入critical section。在论文中,Lamport老爷子并没有解释为什么最多只有一个程序能够进入critical section。而是把这个证明留给了论文的读者,就像我们常见的教科书中的课后习题一样。
Lamport老爷子应该是认为这个证明太简单了,不需要花费笔墨来证明它。sequential consistency这篇论文只有不到两页A4纸,是我见过的最短的论文。这是Lamport一贯的做事风格,他的Paxos论文中,有很多细节都是一笔带过的,给读者留下无尽的遐想(瞎想)。
假设现在我们已经证明这个是正确的(虽然我也没去证明,论文给出了两个参考文献用于证明),那这个例子说明了什么呢?
大家也许注意到了,这个例子没有用到任何锁,但它实现了critical section,critical section是一种多线程synchronization 机制。如果多核处理器是sequential consistency的,那么你写的并发程序“天然就是正确的”。
但是处理器的设计者为了追求性能,将保证程序正确的任务丢给程序开发者。只在硬件级别提供了一些fence、cas等指令,基于这些指令操作内核和语言基础库实现了各种synchronization机制,用来保证操作系统的正确性和应用程序的正确性。程序员必须小心谨慎地使用线程和这些synchronization机制,否则就会出各种意想不到的问题。如果你没有debug一个多线程bug连续加班两天,那说明你是大神。
这些指令都是具有更高一致性级别,也就是linearizability,(关于linearizability可以参见我的另外一篇文章《线性一致性(Linearizability)是并发控制的基础》[2]),虽然一致性级别高,但只是个别指令的,处理器整体只是实现了比sequential consistency低很多的一致性级别。所以实现难度大大降低了。
虽然Lamport老爷子的sequential consistency概念在concurrent programming领域中还没有实际意义,但却给我们指出了程序员的天堂在哪里。在程序员的天堂里,没有多(车)线(来)程(车)编(往)程,只要写程序就行。你面试的时候不会再有人问你多线程编程,不会再问你各种锁。
在分布式领域中,sequential consistency更实际一些。Zookeeper就实现了sequential consistency。同理,这应该也是可以证明的,但目前还没发现有Zookeeper社区有任何论文来证明这个。如果你已经明白上面解释的定义,就可以想清楚Zookeeper是sequential consistency。欢迎大家一起来探讨。
为何Zookeeper要实现
sequential consistency
实际上,Zookeeper的一致性更复杂一些,Zookeeper的读操作是sequential consistency的,Zookeeper的写操作是linearizability的。关于这个说法,Zookeeper的官方文档中没有写出来,但在社区的邮件组有详细的讨论(邮件组的讨论参见[3])。
另外,在 Modular Composition of Coordination Services 这篇关于Zookeeper的论文中也有提到这个观点(这篇论文不是Zookeeper的主流论文,但全面分析了Zookeeper的特性,以及Zookeeper跨机房方案,饿了么的Zookeeper异地多活改造也参考了这篇论文中的一些观点),我们可以这么理解Zookeeper,从整体(read操作+write操作)上来说是sequential consistency,写操作实现了linearizability。
通过简单的推理,我们可以得出Lamport论文中的小例子,在Zookeeper中也是成立的。我们可以这样实现分布式锁。但Zookeeper官方推荐的分布式实现方法并没有采用这个方式,而是利用了Zookeeper的linearizability特性实现了分布式锁(关于Zookeeper官方是如何实现分布式锁的,请参见我这篇文章《Zookeeper实现分布式锁和选主》[4])。
为什么Zookeeper要实现sequential consistency?Zookeeper最核心的功能是用来做coordination service,也就是用来做分布式锁服务,在分布式的环境下,Zookeeper本身怎么做到“天然正确”?没有其他的synchronization机制保证Zookeeper是正确的,所以只要Zookeeper实现了sequential consistency,那它自身就可以保证正确性,从而对外提供锁服务。
参考文章:
[1]http://zookeeper.apache.org/doc/r3.4.9/zookeeperProgrammers.html#ch_zkGuarantees
[2]https://blog.csdn.net/cadem/article/details/79932574
[3]http://comments.gmane.org/gmane.comp.java.hadoop.zookeeper.user/5221
[4]https://blog.csdn.net/cadem/article/details/56289825

近期热文
近期活动