重回榜首的BERT改进版开源了,千块V100、160GB纯文本的大模型
选自 arXiv
作者:Yinhan Liu、Myle Ott、Naman Goyal等
机器之心编译
参与:思、路、张倩
前段时间 Facebook 创建的改进版 BERT——RoBERTa,打败 XLNet 登上了 GLUE 排行榜榜首。近日,Facebook 公开了该模型的研究细节,并开源了模型代码。
BERT 自诞生以来就展现出了卓越的性能,GLUE 排行榜上前几名的模型一度也大多使用 BERT。然而,XLNet 的横空出世,打破了 BERT 的纪录。不过,不久之后,剧情再次出现反转,Facebook 创建的改进版 BERT——RoBERTa,登上了 GLUE 排行榜榜首。
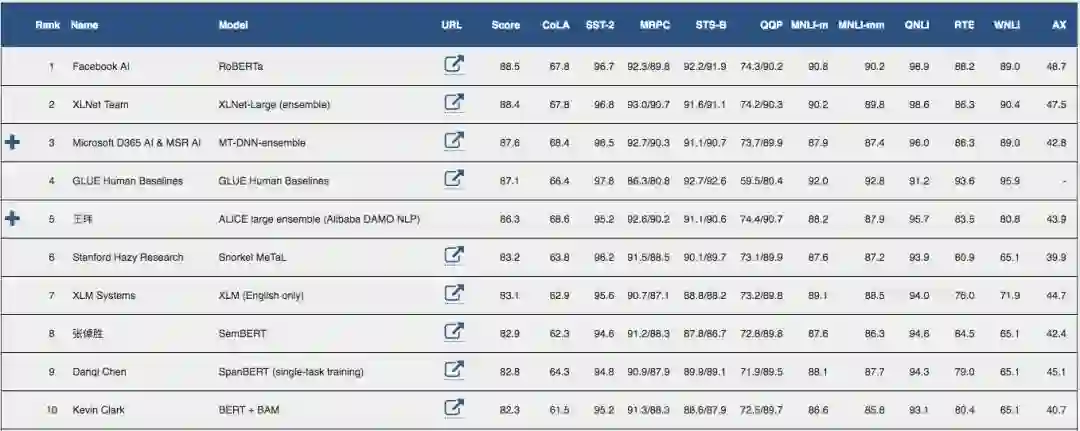
图源:https://gluebenchmark.com/leaderboard/
Facebook 的研究人员表示,如果训练得更久一点、数据再大一点,BERT 就能重返SOTA。
那么 RoBERTa 到底训练了多长时间,使用了多少数据呢?近日,Facebook 研究人员公开了研究细节。
论文地址:https://arxiv.org/pdf/1907.11692.pdf
GitHub 地址:https://github.com/pytorch/fairseq/tree/master/examples/roberta
RoBERTa 到底有多大
之前 XLNet 团队就对标准的 BERT 和 XLNet 做过一次公平的对比,他们测试了在相同参数水平、预训练数据、超参配置等情况下两者的效果。当然,XLNet 通过修改架构与任务,它的效果是全面超过标准 BERT 的。但如果 BERT 要再次超越 XLNet,那么数据和算力都需要更多。
算力
据介绍,Facebook 研究人员在多台 DGX-1 计算机上使用混合精度浮点运算,每台计算机具备 8 个 32GB Nvidia V100 GPU,这些 GPU 通过 Infiniband 连接。
但研究者并没有具体说 RoBERTa 使用了多少张 V100 GPU 训练了多长时间,我们只能了解到他们训练 Large 模型用 1024 块 V100 训练了一天,这样以谷歌云的价格来算需要 6.094 万美元。如下是原论文所述:
We pretrain for 100K steps over a comparable BOOKCORPUS plus WIKIPEDIA dataset as was used in Devlin et al. (2019). We pretrain our model using 1024 V100 GPUs for approximately one day.
数据
BERT 模型预训练的关键是大量文本数据。Facebook 研究人员收集了大量数据集,他们考虑了五个不同大小、不同领域的英语语料库,共有 160GB 纯文本,而 XLNet 使用的数据量是 126GB。这些语料库分别是:
BOOKCORPUS (Zhu et al., 2015) 和英语维基百科:这是 BERT 训练时所用的原始数据 (16GB);
CC-NEWS:Facebook 研究人员从 CommonCrawl News 数据集的英语部分收集到的数据,包含 2016 年 9 月到 2019 年 2 月的 6300 万英语新闻文章(过滤后有 76GB 大小);
OPENWEBTEXT (Gokaslan and Cohen, 2019):Radford et al. (2019) 中介绍的 WebText 语料库的开源克隆版本。其中包含爬取自 Reddit 网站共享链接的网页内容 (38GB);
STORIES:Trinh and Le (2018) 中提到的数据集,包含 CommonCrawl 数据的子集,该数据集经过过滤以匹配 Winograd schemas 的故事性风格 (31GB)。
这样的数据量已经非常大了,它是原来 BERT 数据量的十多倍。但正如 XLNet 作者杨植麟所言,数据量大并不一定能带来好处,我们还需要在数量与质量之间做权衡。也许十倍量级的数据增加,可能还不如几倍高质量数据带来的提升大。
RoBERTa 到底是什么
Facebook 对 BERT 预训练模型进行了复现研究,对调参和训练数据规模的影响进行了评估,发现 BERT 训练严重不足。于是他们提出了 BERT 的改进版——RoBERTa,它可以匹敌甚至超过所有 post-BERT 方法的性能。
这些改进包括:
模型训练时间更长,batch 规模更大,数据更多;
移除「下一句预测」这一训练目标;
在更长的序列上训练;
动态改变应用于训练数据上的掩码模式。
Facebook 研究人员还收集了一个新型大数据集 CC-NEWS,以更好地控制训练数据集规模的影响。CC-NEWS 数据集的规模与其他私人使用数据集差不多。
总之,Facebook 研究人员关于 RoBERTa 的研究贡献可以总结如下:
展示了一组重要的 BERT 设计选择、训练策略,介绍了一些可使下游任务性能更优的替代方法;
使用新型数据集 CCNEWS,并确认使用更多数据进行预训练可以进一步提升模型在下游任务上的性能;
训练方面的改进证明,在正确的设计选择下,掩码语言模型预训练的性能堪比其他近期方法。
RoBERTa 都改了些啥
对于原版 BERT,直接用它来做极大数据的预训练并不能 Work,我们还需要一些特殊的技巧来提升模型的鲁棒性,这也就是 Facebook 研究者主要尝试的。如下研究人员在论文中揭示并量化了 BERT 要进行哪些改进才能真正变得稳健。
1. 静态 vs. 动态掩码
BERT 依赖随机掩码和预测 token。原版的 BERT 实现在数据预处理期间执行一次掩码,得到一个静态掩码。Facebook 研究者将该策略与动态掩码进行比较,动态掩码即,每次向模型输入一个序列时都会生成掩码模式。在预训练进行更多步或使用更大的数据集时,这点变得尤其重要。
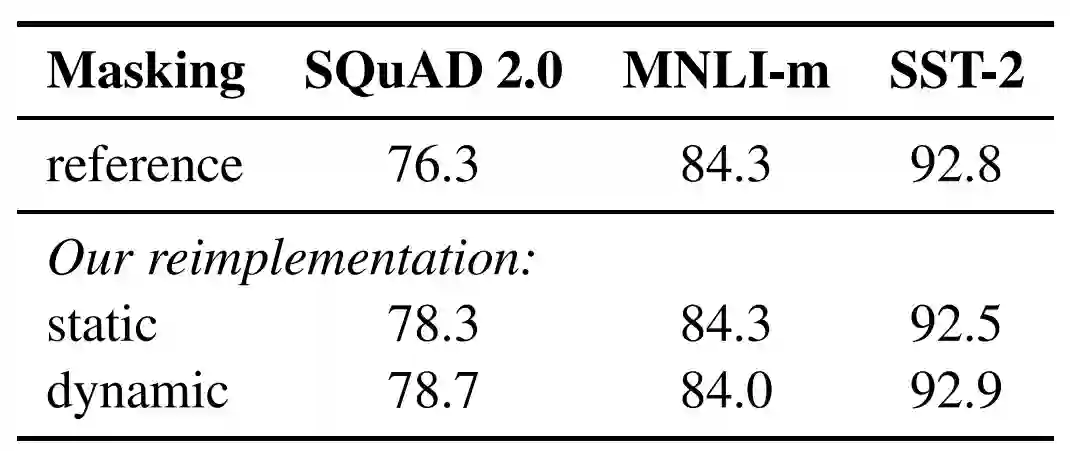
表 1: BERT_BASE 的静态和动态掩码比较。
2. 模型输入格式和下一句预测
在原版的 BERT 预训练步骤中,模型观察到两个连接在一起的文档片段,这两个片段要么是从相同的文档中连续采样,要么采样自一个文档的连续部分或不同文档。为了更好地理解这种结构,研究者比较了几种训练格式:
SEGMENT-PAIR+NSP:这种方式和 BERT 中用到的原始输入格式相同,NSP 是 Next Sentence Prediction(下一句预测)结构的缩写。
SENTENCE-PAIR+NSP:每个输入包含一对自然语言句子,采样自一个文档的连续部分或不同文档。
FULL-SENTENCES:每个输入都包含从一或多个文档中连续采样的完整句子,以保证总长度至多 512 token。
DOC-SENTENCES:这种输入的构造与 FULL-SENTENCES 类似,只是它们可能不会跨过文档边界。
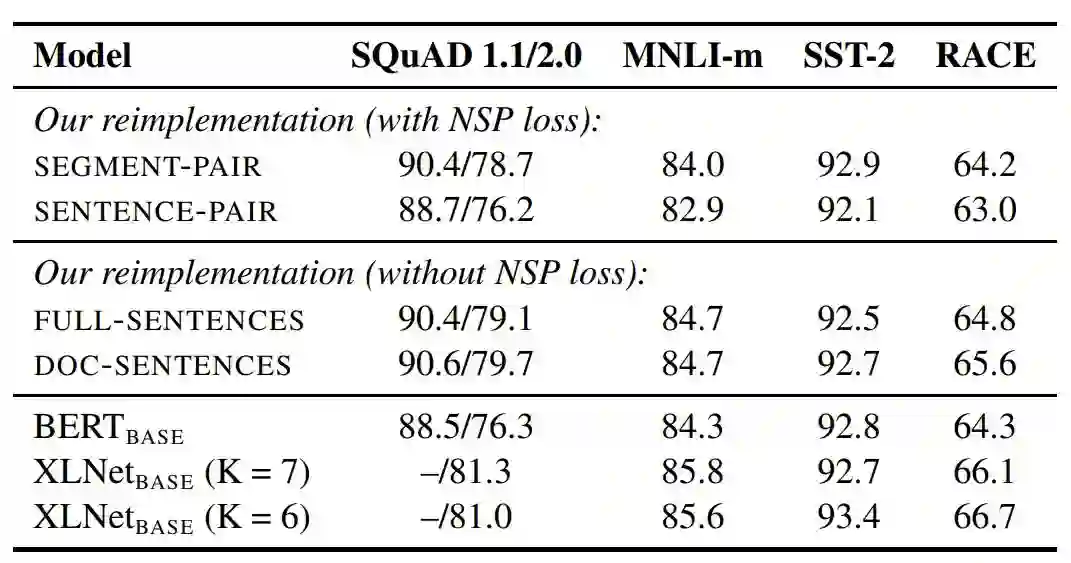
表 2:在 BOOKCORPUS 和 WIKIPEDIA 上预训练的基础模型的开发集结果。所有的模型都训练 1M 步,batch 大小为 256 个序列。
3. 大批量训练
神经机器翻译领域之前的工作表明,在学习率适当提高时,以非常大的 mini-batch 进行训练可以同时提升优化速度和终端任务性能。最近的研究表明,BERT 也能适应大批量训练。
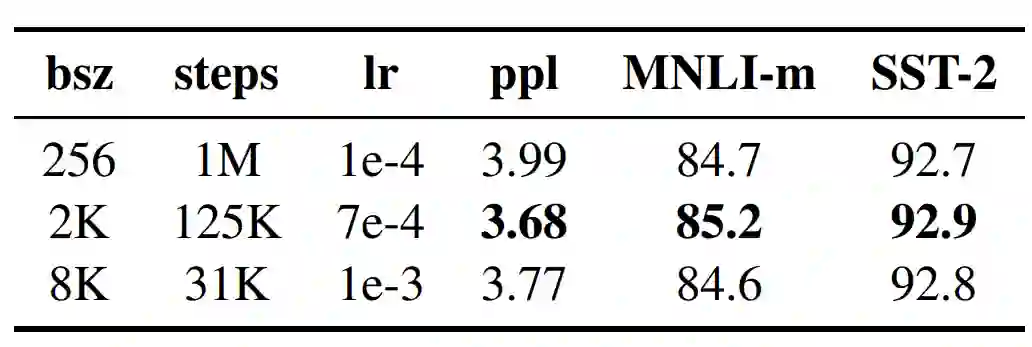
表 3:在 BOOKCORPUS 和 WIKIPEDIA 上用不同的 batch 大小(bsz)训练的基础模型在留出训练数据(ppl)和开发集上的困惑度。
4. 文本编码
Byte-Pair Encoding(BPE)是字符级和词级别表征的混合,支持处理自然语言语料库中的众多常见词汇。
原版的 BERT 实现使用字符级别的 BPE 词汇,大小为 30K,是在利用启发式分词规则对输入进行预处理之后学得的。Facebook 研究者没有采用这种方式,而是考虑用更大的 byte 级别 BPE 词汇表来训练 BERT,这一词汇表包含 50K 的 subword 单元,且没有对输入作任何额外的预处理或分词。这种做法分别为 BERTBASE 和 BERTLARGE 增加了 15M 和 20M 的额外参数量。
实验结果
Facebook 研究人员综合所有这些改进,并评估了其影响。结合所有改进后的方法叫作 RoBERTa(Robustly optimized BERT approach)。
为了厘清这些改进与其他建模选择之前的重要性区别,研究人员首先基于 BERT LARGE 架构训练 RoBERTa,并做了一系列对照试验以确定效果。
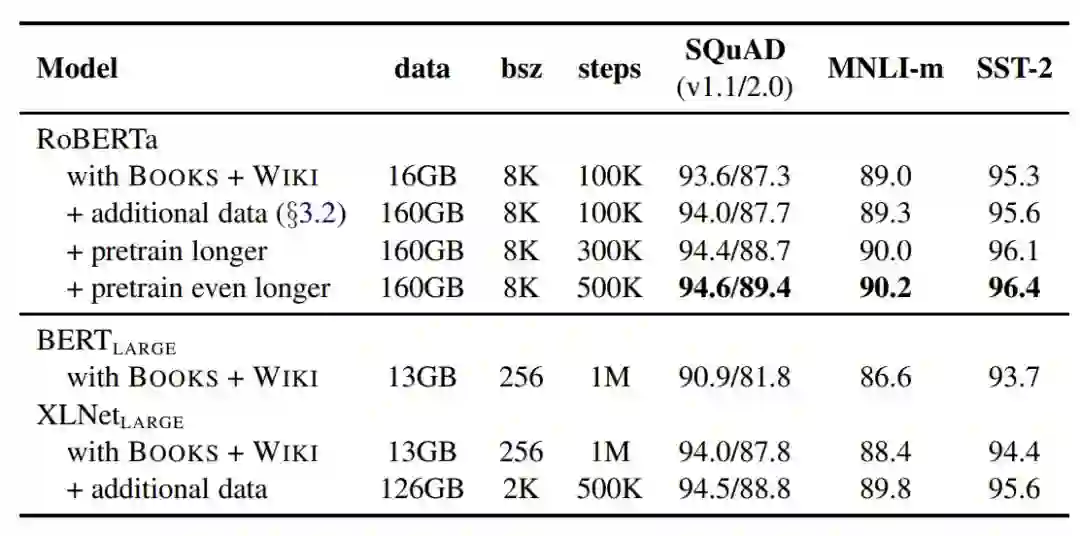
表 4:随着训练数据的增大(文本数量从 16GB → 160GB)、训练步长的增加(100K → 300K → 500K 训练步),RoBERTa 在开发集上的结果。在对照试验中,表格中每一行都累积了前几行的改进。
对于 GLUE,研究人员考虑了两种微调设置。在第一种设置中(单任务、开发集),研究人员分别针对每一项 GLUE 任务微调 RoBERTa,仅使用对应任务的训练数据。在第二种设置中(集成,测试集),研究人员通过 GLUE 排行榜对比 RoBERTa 和其他方法。
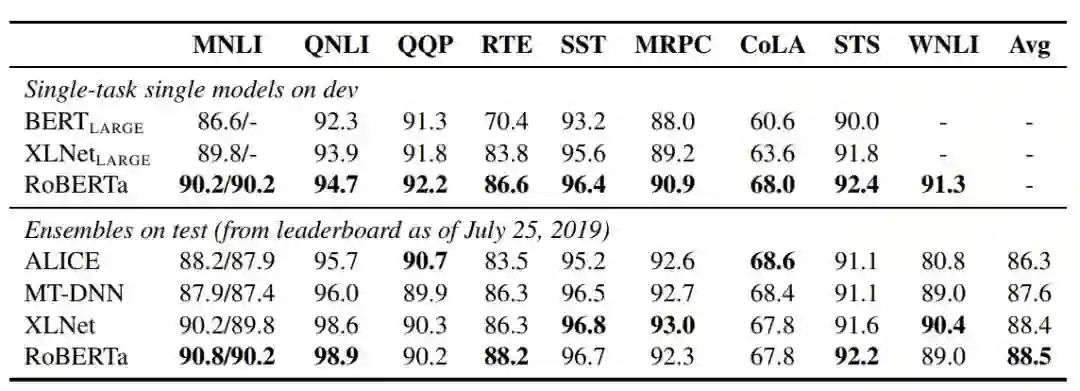
表 5:多个模型在 GLUE 上的结果。所有结果都基于 24 层的模型架构。
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




