![]()
编译 | 王念
生逢这个效率和利益无比珍贵的时代,万事万物都需要准确的“评价”和“度量”。就像看到一幅油画,我们会评估它的笔触;入手一款香水,我们会品味它的前中后调;交往一位异性,我们会感受ta的温柔、曲线或棱角(是的!)。甚至是对于自身,我们也有着一系列的度量方法和评价指标。
这些指标定量地描述了世界,理性地构成了我们对于所处环境和所遇事物的认知。它们是世间万物的影子,是我们洞悉世界的镜头,也是监督和改变目标事物的方式。
本文作者作为在几十个数据科学项目上战斗了好几年的老炮儿,希望
通过这篇
文章跟大家聊聊他心中的“评价指标设计之道”。
简单来说,他认为评价指标的设计共有5个关键点:
代价成本、简洁性、可信性、准确性和因果相关性
。它们之间的权衡与取舍决定了所设计的评价指标的侧重方向,它们也是评价指标的设计过程中最核心的考虑因素。
无数个日夜里,我都在思考着“评价指标”这个神奇的家伙。我觉得评价指标和对应的度量方法是构成现代科学的基础,也是促进现代社会、政策和商业等领域发展的关键技术。
举例来说,人类的航海和远征事业一直受到时间记录方法的限制,直到我们发明了更加精准的时间记录方法之后,人类才能绘制出整个大陆乃至世界的恢弘地图;再例如天文学原本长期处于牛郎织女和圣斗士星矢的神话水平,直到十分系统的天文观测记录技术才为其带来了革命性的进步;而在流行病学领域,也只有当约翰斯诺用笔建立了霍乱病人传播的扩散图时,人们才明白这场搅得大英帝国天翻地覆的传染病是由水源引起的。
正所谓工欲善其事必先利其器,只有当我们对所研究问题构建起正确的记录方法和衡量方法,其本质和内在规律才能够被剖析出来,人们也才能有的放矢地对其进行研究并加以解决。
曾几何时,集体投资是个玄学。面对金融界风云莫测的时局以及浩如星海的商海变数,人们往往无法准确锁定投资目标。但是当人们建立了合理的评价和测量标准,投资人就只需要将注意力放在选定尺度上的那些特定属性上,大大提高了投资的成功率。当然也正是因此,我们也才能创造出高效的分布式感知系统(Distributed Perceptual System)。
度量和评价指标正在逐渐成为我们生活的一部分,当我们跟朋友聊起正在发生的事情的时候,当我们根据当前形势进行决策的时候,度量跟评价标准都会高频率的出现在我们的语言之中。它潜移默化地影响着我们。
其实说起度量方法和评价指标,它最厉害的地方在于能对目标内部组织的协调过程进行量化和描述。在生活中,我们会对自己所珍视和关注的事物格外关心;而在研究和建模时,我们也应小心地选择和设计度量方法和评价标准。就好像在爬山的时候,我们会根据山丘的拓扑结构(其实就是陡峭程度啦)和y标度(y-scale)来选择较易攀爬的路线。但仅仅这样是不够的,我们还应同时将各种风险和不利因素(湿滑程度、岩石风化程度等等)考虑进去,综合形成一套统一的登山路线度量方式和评价指标。我们希望这个指标既能够对有利于攀登的因素进行正向的表示,也能够对不利于攀登的危险因素进行负值编码。
在设计一个评价指标的时候,我们一定要时刻铭记5个关键点:代价成本、简洁性、可信性、准确性和因果相关性。对于这几个关键点的提升能够直接帮助后续产品的改进、用户体验的提升,也能帮我们在各种左右为难的权衡局面中做出合理和自然的取舍。当然了,这5个关键点不仅用于商业和数学场景,也能应用于其他领域中。在本文中,因为我的老本行是产品开发,所以在介绍中会更多的以统计和因果特性角度对这5个问题进行描述。
![]()
咱们先从代价和成本说起,因为它们是评价指标中最容易被忽略的方面。俗话说,有钱能使鬼推磨。只要你有钱、愿意付出足够的“成本”和“代价”,那这个世界上几乎任何事都能被量化和评估出来。这个“代价”或者“成本”可能是钱、可能是时间、可能是员工时间、用户时间(就是占用用户时间让他们做特定事情)、计算量或者技术和债权等等。在研究问题时,当我们考虑成本因素时,便自然而然地需要对所研究事物的决策进行一定的权衡和取舍了。但是据我观察,人们在设计度量方法的时候,总是喜欢使用包含人类主观标记信息、用户调查报告或者外源性的数据集。不是说不好,而是这些信息源都会给评价标准的设计引入大量的复杂性、延迟和误差,我们称之为“噪声”。
虽然在我们的印象中,代价和成本通常是一个固定的、有限制力的约束条件,它相对来说很稳定,不会根据外界呈现巨大的波动。但其实在很多情况下,我们能够通过多付出一些成本的方式“作弊”,从而让评价指标的结果得分变得更加漂亮。换句话说,我们能够通过付出时间、金钱或者一些额外的代价来得到更好的评估结果。这种成本和结果之间的折衷很难处理,因为评价方法的改变也能带来评估结果的受益,这个收益也要加入评估结果当中。而且评估方法的改变会产生蝴蝶效应,其下游产品势必会产生连锁反应,这个影响所带来的受益或者损失也要考虑进去……emm,错综复杂。
![]()
评价指标是人设计的嘛,人天生喜欢简单明了的东西:数学领域称之为公式之美,计算机科学称之为代码简洁之道,异性们称之为直爽……亦或性感。不好的评价指标往往充斥着人们对于所描述事物的不信任和二次猜忌,也会因为忽略了事物的某些特征而让评价指标不够全面。
通过实践总结,我关注到规则化(Normalization)通常是一个不错的技术,它能让问题的描述和考虑的方面更加的集中、不冗余,从而构建出一个性能优越的评价方法。而通过组合方式(Combination)叠加出来评价标准通常不怎么样(因为组合之后要考虑的东西更多,我们评估的时候就特别不容易集中到关键上)。比如在体育赛事的技术数据分析环节中,人们会发现在评价指标中添加某某率(比如击球的成功率、上垒的成功率、三分命中率,就是用原本的数值除以一个整体的次数)或者考虑比赛的环境背景(主场优势之类)因素来评价某个球队的表现是很有效的。但是一股脑儿的将击球率、出手次数也放到评价标准里显然没啥用,因为没人觉得击球率也能和本垒打能有半毛钱关系。
哦对了,虽然规则化很有效,但是找到规则化项中“某某率”的分母通常是很难的。有多难呢?瞅瞅人家怎么说:
https://twitter.com/fredbenenson/status/370222055083753473
有一次在项目中,我想用所谓的“模型化度量(Modeled Metrics)”来降低模型对于简单化的硬性标准(技术上来说就是输出统计模型,从而平滑并提高估计的准确性)。但很可惜,它们都没能完全成功。机器学习领域有个定律叫“没有免费的午餐”嘛,当我们牺牲了简单性,那相应的就会在所研究的其他问题和特性上产生变动并引入不确定性。
![]()
虽然人们绞尽脑汁地想设计出高效的评价指标,但是很遗憾,世界就是这么残酷,一多半的工作都不能准确表达出我们所关心的事物和概念。在我的经验里,两种情况下设计的评价指标效果极差:第一个是缺乏结构有效性的设计,第二个是数据集带有某种抽样偏差的情况。其中缺乏结构有效性的设计是指,这个指标所度量的东西跟我们关心的目标根本不是一码事儿的情况,驴唇不对马嘴,无法构成有效的度量;而抽样的偏差是指我们数据集中的样本和事物本身的分布不匹配的情况,采样的偏差会让我们关注到事物的那些没什么用的方面,从而忽略了数据的重要特征。
在实践中,简单性、低成本和构造的有效性通常是对立的,此消彼长。我们通常会为了追求简单和低成本性而破坏了构造的有效性。很多公司或团队在这个方面投入了大量的人力物力,力求得到完美的平衡。结构有效性设计的一个难点在于它其中使用的人类标记信息。人类都具有主观偏差性,每个人在标记过程中的准则和标准都可能有所差异,可能A童鞋将这个标签标记为1,B童鞋就认为应该标记为2。每个人对于标签的理解都存在着主观性和差异性。
https://twitter.com/seanjtaylor/status/1090320775901409280
除了人类标记信息外,还有一种十分主观且伴随着噪声的信息会影响评价指标的客观性,就是用户反馈。用户的反馈五花八门,比如调研报告、缺陷报告和众包标签等等,我们在利用数据的时候很难判断这个人到底能不能代表我们关心的目标人群,不知道他掺入了多少主观因素,更不知道他到底认真反馈了没有。如果我们不能保证用户反馈体现了严格数学意义上的随机抽样,那我们可能永远无法解决这个问题。因此,在设计评价指标的时候我们就必须接受并容忍这个误差源。需要注意的是,即便是特别简单的二分类标签,比如抖音上“喜欢”和“不喜欢”,也可能会因为用户的参与率和调查涵盖面的问题而引入较大偏差,那此时我们的样本集就可能会出现以偏概全的现象。我们将这种现象称为“度量信度”问题。
1)广告的点击量和销售额没什么联系。如果我们用广告的点击率作为销售额的衡量标准,那可能会出现南辕北辙的现象,因为根据统计,它们两个压根儿没有关联。如果算法只使用广告点击率作为评价指标,那它可能会去优化一个跟销售总额不相关的目标函数。要知道,广告的点击者和购买者可能是两拨不同的人。
2)微博文字的情绪和作者真实情绪间相关性很低。微博上感伤文字的主人可能是个乐天派,阳光文学的作者可能是个伤痕累累的文艺青年呢。如果你想通过人们的Twitter和Facebook帖子衡量他们的幸福感,那很可能老铁,你就弄错了。
![]()
准确性应该是五个重要指标中最容易理解的那个了。毋庸置疑,准确性越高越好。不好的度量方法会导致数据中的噪声和有效值混到一起的现象,从而无法区分。换句话说,在这种情况下我们没法通过控制变量来对所研究问题进行评估了。当我们调整一个参数的时候,结果在变;我们不调整它的时候,结果还是在变。如此一来我们就糊涂了,不知道结果的改变是由参数的调整所引发,还是因为噪声所致。这里我列举了三个关于精确度指标的注意事项:
1)我们能够通过数学变化对评价指标的结果进行干预,从而提升精确度。数学变换包括对数计算、尾处理或者一些其他的高级技术。
2)规则化能够大幅提高度量的精确度。比如在评价指标的计算中,如果分子是有偏差的,那我们通过规则化能够让分母也具有类似的偏差。如此一来,这个偏差会被约分,比值结果的方差便会缩小(难道这就是所谓的以毒攻毒)。通过规则化能够降低度量方法的方差。
3)对多个评价标准进行求和或均值操作能够提高精度。不同的度量方法就是从不同的角度对事物进行观测,如果我们能够对目标事件进行多种不相关的观测,那它们的组合结果就会比单独观测的结果更加稳定,也就不会充斥着那么多噪声了。但代价是模型的简单性会降低,也可能会减少因果关系的相关性。
评价方法的精确性和可信性间往往存在内在的权衡。比如说在商业场景中,财务结果(比如销售额、收入或利润)的评价指标可能包含很多造噪声,这是因为数据分布的倾斜性所致的。当我们锁定变量,仅对其中的一位客户或某一宗交易进行离散的计算时,结果就会具有较小的方差了。
![]()
好的度量方法还需要有一个特点就是能被人类刻意控制。Deng和Shi在2016年定义了一个很有意思的概念,叫做灵敏度,它由上一节我们提到的精度性和典型效果尺寸(Typical Effect Sizes)组成。我觉得应该将这两个属性分开,分别考虑。于是我使用相关性(Proximity)来描述我们设计的评价指标与人为更改变量在因果空间上的近似程度。
当评价指标和人为因素之间的因果的相关性很低时,人们通常不会根据产品的变化经常性的修改评价指标,因为你要对评价指标进行干预的话是需要经过很长一个因果关系链才能完成的。而这个链条太长、太晦涩了,相关度太低了。通常来说,如果因果关系性很低的话,我们只能使用利润或者收入这个简单粗暴的最终指标衡量大多数产品的变化效果,但是这个衡量通常是无效的。我们必须建立一个具有更高相关性的评价指标,并尝试通过某种理论来说明这对于可信性的影响是多么的有效。
这个理论被称为代理度量(ProxyMetric)。这个代理度量的具体数学内涵可能不是本文关心的重点(要是真写也没人看了哈哈),但是我们能够通过它对可信性的影响程度进行评估。对于我们所关心事物的长链输出影响,最近有研究提出使用替代指标(Surrogate Indices)进行描述。在这个方法中,我们可以通过使用短期指标的输出来更靠谱地估计长期输出的结果。
对了,物极必反,因果相关性太高的话也是不可取的。因为谁想要一块一成不变的木头来体现当下的变化呢?评价指标中适当的敏感性能帮助人们更好地理解可控参数为结果和评价所带来的影响(也叫操作检查Manipulation Checks),从而能够评估我们的假设和处理操作能否引起正确的反应。只有这样,我们才可以将评价指标作为一个监视器,从而建立起“改变-反馈”的链条来指导生活并服务当下。
![]()
作为一个评级指标,其高贵性一定要得到充分的体现。毕竟万事万物皆有灵性,如果我们无法给予评价指标足够的尊重、尊严和自豪感,那么它……算了,我编不下去了哈哈哈,这条是开玩笑的哈,别当真老铁。
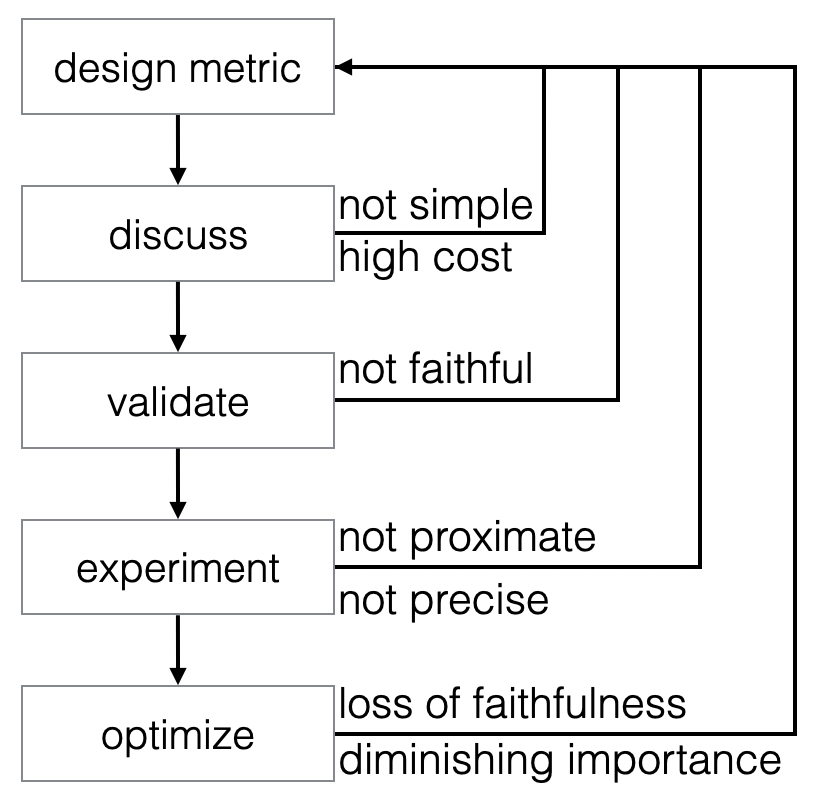
根据我的经验,评价指标的设计是一个来回迭代性的过程,它是多方参与者在一个较长时间内的合作、总结和权衡的漫长过程。下面这张图是一个理想情况下的评价指标设计流程。我们可以看到,它实际上是一堆循环的嵌套,我们甚至在某些特殊情况下会陷入死循环的窘境。这是因为评价指标的设计没有一定之规,它的变数太大、问题太多、可能的解决方法也千奇百怪。这个流程图也只能帮助我们“以管窥豹”,大概了解评价指标的设计之道。
![]()
设计评价指标的过程有时候就像写代码一样,我们要经历写代码、样例测试、重新评估和代码调整,然后在代码逻辑不符合最新需求的时候重写关键模块(或者在甲方无限的苛责和临时起意下删库走人,开玩笑哈哈)。
1、讨论
:毛爷爷告诉我们,从群众中来,到群众中去。
我们要广泛的听取人们内心的需求,同时更要将这些需求形式化、量化起来。
虽然有点絮叨,但是在我的实际
工作中,我会首先认真细致地了解目标人群的需求,并且尝试在多个矛盾的需求之间做出权衡和取舍,力求找到一个平衡点。
在这个过程中我们可能会使用很多种不同的评价指标作为候选,因为这样很方便很简单,成本也很低。
但是如此简单和低成本的做法很可能会限制评价指标的表达能力和学习能力,从而降低评价指标的应用效果。
2、验证
:有个有趣的现象,就是人们往往更喜欢那些新提出来的评价指标(喜新厌旧的家伙!),而且会十分乐意去相信那些少数的、符合自身认知和直觉的特例(所谓刻板偏见嘛)。
比如说,当我们对某个事物进行了调整,如果结果的变化跟我们设想的一样,那我们会特别容易接受这个现象,也会更容易信任所使用的评价指标了。比如曾有研究者收集数据集,就是看某个已知好坏的操作会引发人们评价指标的哪些主观变化。我觉得这个数据集很有意思,它能用来评估人们的刻板偏见所带来的的主观影响,当然,前提是我们收集了足够多的实验、标记了足够多的样本哈。
3、实验:
其实很多研究都没有得到他们最关心的评价指标的理想实验结果。
我曾经在Facebook做了一个产品,在那我们几个月的实验,但是收效甚微。因为我们的评价指标的噪声太大了,其中的因果关系太低了。如果我们无法刻意地、有因果对评价指标产生一些影响和控制,那其实这个评价指标就没什么实际作用了。这时候你可能就要考虑牺牲一些评价指标的可信性,或者付出一些其他的代价从而换取更高的因果性和精确性了。在我们的实验验证过程中,那些不好的评价指标应该被尽量剔除掉,因为他们只会让我们实验结果的“信噪比”降低,让结果分析起来更加困难。
4、优化:
有了度量之后,我们就能用它作为目标对所研究的事情进行优化了。
那优化操作会带来什么结果呢?人们总觉得只要目标选对了,算法所进行的优化就一定能带来积极的反馈。但其实对于很多评价指标来说,它都是有自己的优化上限的,或者叫做优化的饱和点。从这个饱和点开始,如果我们再进行额外优化的话,就会不经意间过度修饰,从而损害一些我们关心的其他东西。就比如在很多公司中,他们都会面临一个核心挑战,就是最优化评价指标和原则性决定之间的权衡。为了追求最优化的评价结果,可能就会触碰公司的原则性底线。这些原则性的问题也许关乎行业利益、信誉甚至是法律道德。也像某建国同志为了追求股市和经济的上涨而不顾某国疫情强制开工一样。
我们需要注意,当我们纯粹地以某个指标为驱动来最大化利益或最小化损失的时候,这个评价指标原本想表达的意义就会逐渐被削弱。这个现象在经济学和社会学中通常被称作古德哈特定律(Goodhart’s Law)。
很晦涩?其实就像利用增强学习技术教会计算机打游戏的场景一样:计算机通常会寻找到某个歪门邪道的玩法,甚至不惜利用游戏的bug(比如某种骚操作让内存数值溢出)来让自己取得更高的分数或者出奇制胜。显然我们的目的不是让它找bug,而是让他在我们制定的规则中找到最优的操作方法和获胜路径。所以,面向评价指标的优化也是个烧脑的话题呀。
via https://medium.com/@seanjtaylor/designing-and-evaluating-metrics-5902ad6873bf
AI 科技评论希望能够招聘 科技编辑/记者 一名
办公地点:北京/深圳
职务:以参与学术顶会报道、人物专访为主
工作内容:
1、参加各种人工智能学术会议,并做会议内容报道;
2、采访人工智能领域学者或研发人员;
3、关注学术领域热点事件,并及时跟踪报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。
感兴趣者,可将简历发送到邮箱:cenfeng@leiphone.com
点击"阅读原文",直达“ACL 交流小组”了解更多会议信息。