G1 垃圾收集器之对象分配过程
(点击上方公众号,可快速关注)
来源:占小狼 ,
www.jianshu.com/p/a0efa489b99f
G1的年轻代由eden region 和 survivor region 两部分组成,新建的对象(除了巨型对象)大部分都在eden region中分配内存,如果分配失败,说明eden region已经被全部占满,这时会触发一次young gc,回收eden region的垃圾对象,释放空间,满足当前的分配需求。
小对象
G1默认启用了UseTLAB优化,创建对象(小对象)时,优先从TLAB中分配内存,如果分配失败,说明当前TLAB的剩余空间不满足分配需求,则调用allocate_new_tlab方法重新申请一块TLAB空间,之前都是从eden区分配,G1需要从eden region中分配,不过也有可能TLAB的剩余空间还比较大,JVM不想就这么浪费掉这些内存,就会从eden region中分配内存。
allocate_new_tlab方法的实现:
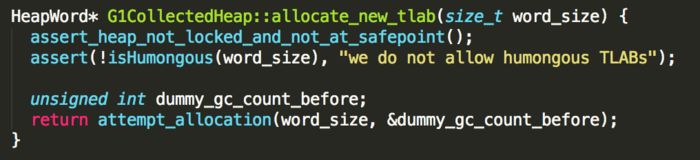
这只是TLAB申请入口,真正的实现位于attempt_allocation方法中,优先尝试在当前的region分配。
attempt_allocation方法的实现:
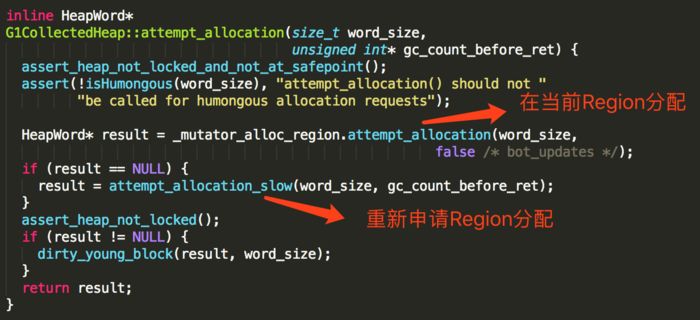
其中_mutator_alloc_region在实现上继承自G1Allocregion,内部持有一个引用_alloc_region,指向当前正活跃的eden region,可以看成是该region的管理器,其attempt_allocation方法负责在该region中分配内存。
G1Allocregion::attempt_allocation方法的实现:
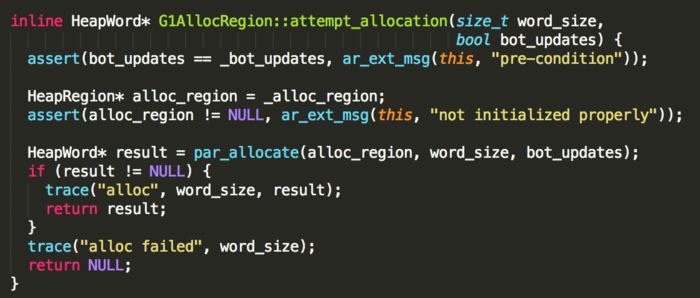
每个region内部管理着一块逻辑连续的地址空间,在并发情况下,采用指针碰撞方式进行内存分配,避免了效率低下的加锁操作。
指针碰撞实现原理:
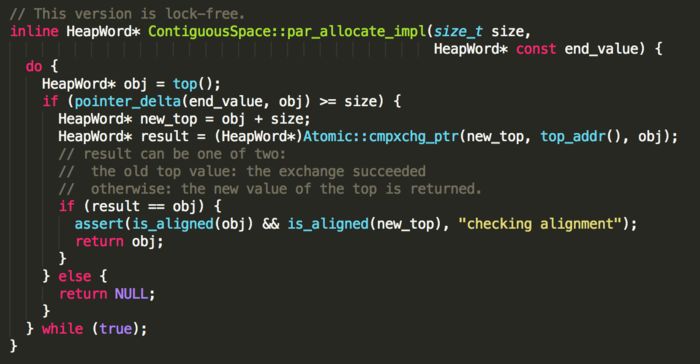
如果上述分配动作返回NULL,说明当前该region空间不足,导致分配失败,继而调用attempt_allocation_slow方法,执行慢路径进行分配。
慢路径的实现如下:
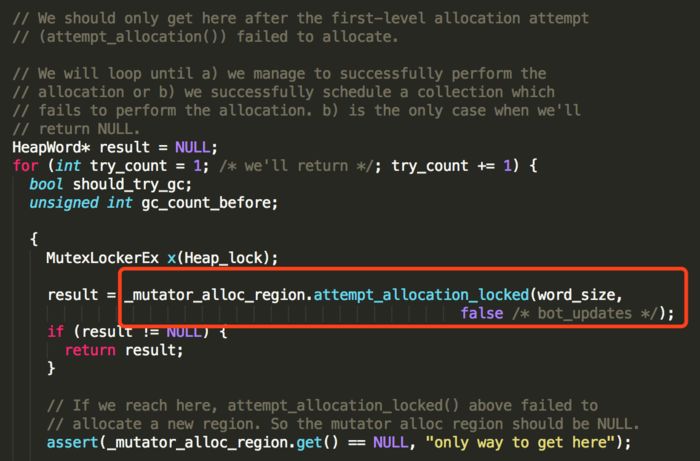
慢路径的逻辑主要是申请一个新的region,不过可能存在多个线程同时申请,所以在申请动作发生之前,需要进行加锁操作,由于调用层级比较多,暂时忽略中间步骤,分析最终实现。
G1CollectedHeap::new_mutator_alloc_region方法实现:
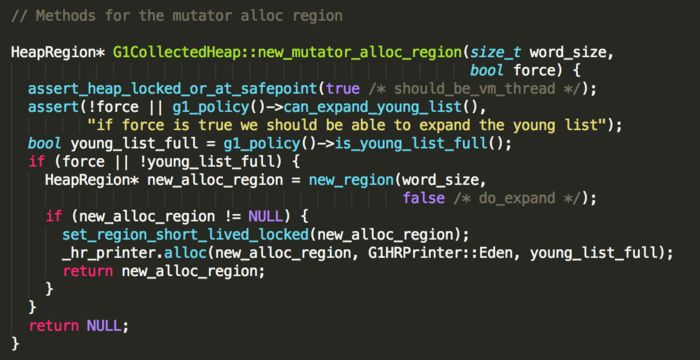
其中force为false,is_young_list_full方法判断当前young_list中的region数是否已经超过阈值_young_list_target_length,实现如下:
bool is_young_list_full() {
uint young_list_length = _g1->young_list()->length();
uint young_list_target_length = _young_list_target_length;
return young_list_length >= young_list_target_length;
}
其中_young_list_target_length,在gc之后会重新计算得到一个合理的值,如果当前young region的数量还没达到阈值,则可以通过new_region()方法获取一个新的region,否则返回NULL。
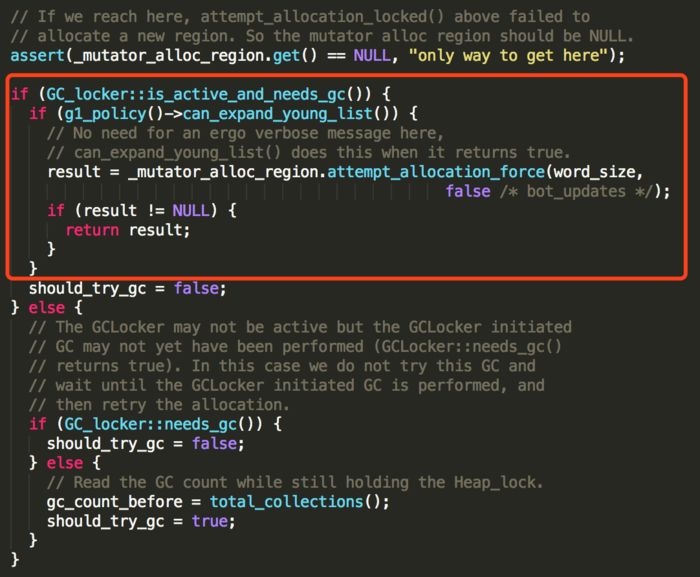
如果返回NULL,说明没有申请到一个新的region,接下去还会判断GC_locker的状态,如果GC_locker::is_active_and_needs_gc(),说明很快会有一个gc操作,并且region list还有扩大的可能(region list的大小还没有达到_young_list_max_length),则可以执行_mutator_alloc_region.attempt_allocation_force强制申请一个新的region,但是强制申请也是有可能失败的(整个堆内存耗尽,不过这种情况很少出现)
如果都失败的话,这个时候确实需要来一发gc治疗一下了
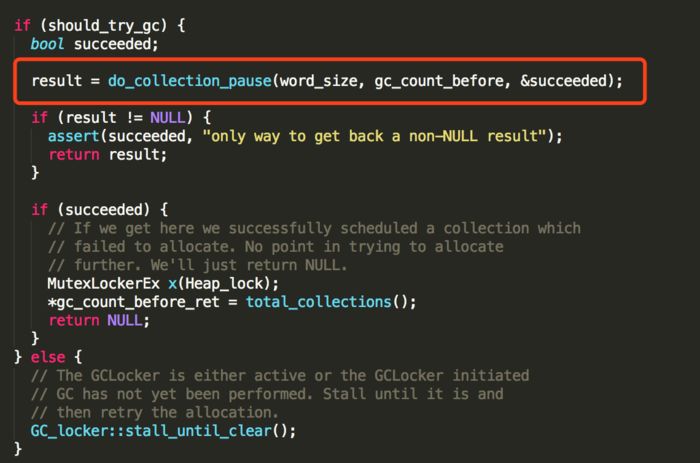
这次gc和后续的大对象分配失败触发的gc过程是一样的。
大对象
前面描述的小对象的内存分配过程,如果当前分配的是大对象,由于在TLAB中放不下,这时只能走G1CollectedHeap::mem_allocate()逻辑进行分配:
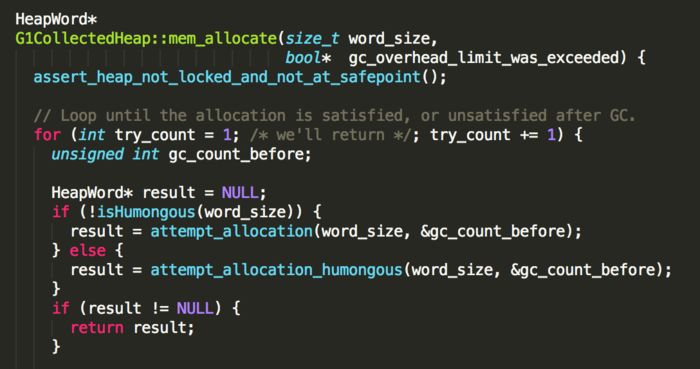
判断当前分配的大小是否满足巨型对象(超过region大小的一半),如果不是巨型对象,则通过attempt_allocation()的碰撞指针方式进行分配。
如果是巨型对象,则执行attempt_allocation_humongous()方法进行分配,在申请内存之前,会进行MutexLockerEx x(Heap_lock)加锁操作,根据所分配的大小计算出至少需要多少个连续的region。
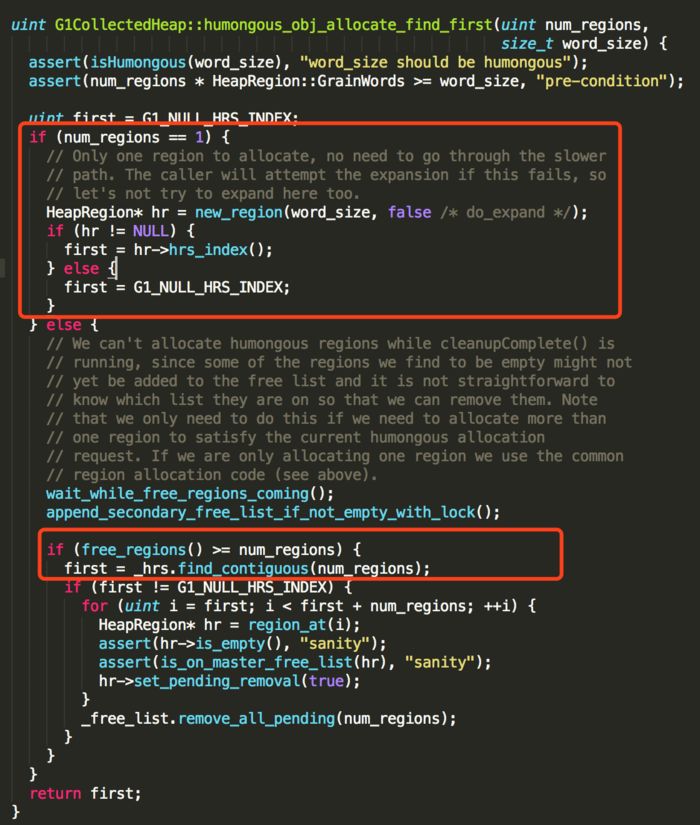
1、如果只需要一个region,通过new_region()直接返回一个可用的region即可。
2、如果需要多个region,则从空闲可用的region列表中找到多个连续的region,并返回第一个region的序号。
3、如果不存在这么多个连续的region,则会扩大堆内存,尝试再次分配。
4、如果扩大堆内存还是不够(一般情况是够的,因为是按需要的大小进行扩大,除非可扩大容量已经很小了),有可能会触发一次gc操作。
巨型对象分配失败之后:
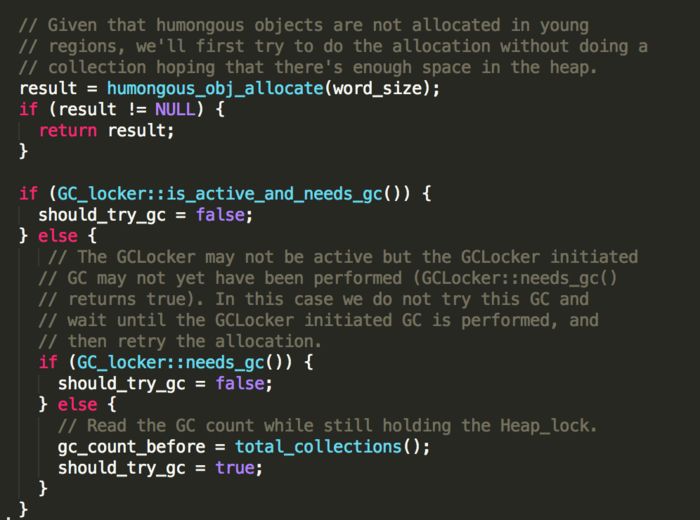
根据当前的GC_locker的状态,决定是否执行本次gc
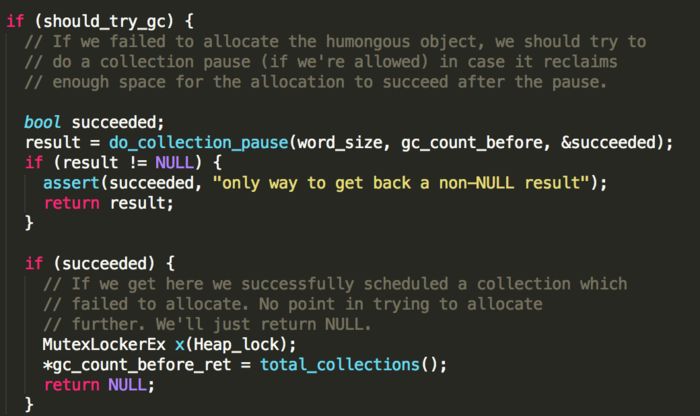
如果需要,则执行do_collection_pause方法触发一次gc动作
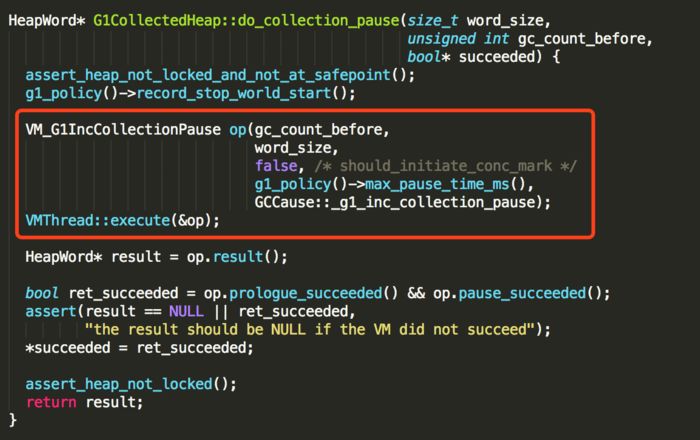
这里触发的gc是VM_G1IncCollectionPause,具体的gc过程,在后续文章继续进行分析,等完成之后,再次尝试分配。
看完本文有收获?请转发分享给更多人
关注「ImportNew」,提升Java技能





