最近租房有点烦!技术人如何用Python找到称心如意的“小窝”?

相关阅读:
17届互联网校招薪酬报告:白菜价22W,青菜价30W,神价150W
互联网技术(java框架、分布式、集群)干货视频大全,不看后悔!(免费下载)
11 月 18 日,北京西红门镇新建二村“聚福缘公寓”突发火灾。火灾后,随之而来的是一场全北京市的“安全隐患大排查大清理大整治”风暴。

聚集着几万外来务工人员的新建村在几天之内被清理一空。很多人正面临着要重新找房子或是离开北京的问题。
违建的公寓正在消失,危房出租正在被拆,这些被“风暴”涉及到的外来上班族怎么办?只有接受现实,勇敢面对。
为了生存,为了能留在帝都,为了改变人生、出人头地,再贵的房子他们都要租,或者他们可以再寻找一处稍远点的房子。
租房的烦恼,相信大家或多或少都有过。独自一人在大都市打拼,找个温暖的小窝实属不易,租个称心又价格公道的房子是件重要的事儿。
站在技术人的角度,今天我就如何从各大租房网的房源里面,找到最称心如意的小窝做些分享,供大家参考。
在找房子的过程中我们最关心是价格和通勤距离这两个因素。关于价格方面,现在很多租房网站都有,但是这些租房网站上没有关于通勤距离的衡量。
对于我这种对帝都不是很熟的人,对各个区域的位置更是一脸懵逼。所以我就想着能不能自己计算距离呢,后来查了查还真可以。
实现思路就是:先抓取房源信息,然后获取房源的经纬度,最后根据经纬度计算公司与具体房源之间的距离。
我们在获取经纬度之前,首先需要获取各个出租房所在地的名称,这里获取的方法是用爬虫爬取链家网上的信息。
Xpath 介绍
在爬取链家网的信息的时候用的是 Xpath 库,这里对 Xpath 库做一个简单的介绍。
Xptah 是什么
Xpath 是一门在 XML 文档中查找信息的语言。Xpath 可用来在 XML 文档中对元素和属性进行遍历。
Xpath 在查找信息的时候,需要先对 requests.get() 得到的内容进行解析,这里是用 lxml 库中的 etree.HTML(html) 进行解析得到一个对象 dom_tree,然后利用 dom_tree.Xpath() 方法获取对应的信息。
Xpath 怎么用
Xpath 最常用的几个符号就是“/”、“//”这两个符号,“/”表示该标签的直接子节点,就比如说一个人的众多子女,而“//”表示该标签的后代,就比如说是一个人的众多后代(包括儿女、外甥、孙子之类的辈分)。

更多详细内容这里就不 Ctrl C/V了。
数据抓取
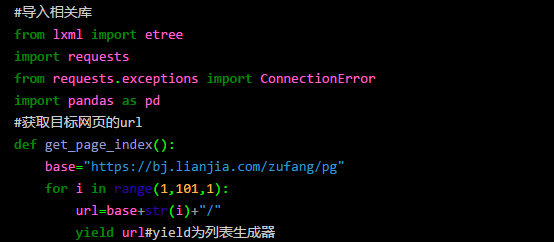
我们本次抓取数据的流程是先获得目标网页 url,然后利用 requests.get() 获得 html,然后再利用 lxml 库中的 etree.HTML(html) 进行解析得到一个对象 dom_tree,然后利用 dom_tree.Xpath() 方法获取对应的信息。
先分析目标网页 url 的构造,链家网的 url 构造还是很简单的,页码就是 pg 后面的数字,在租房这个栏目下一共有 100 页,所以我们循环 100 次就好啦。
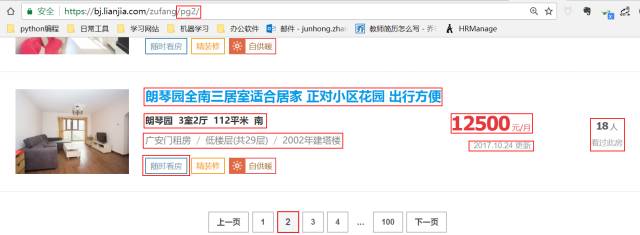
还有就是明确我们要获取的信息,在前面我们说了目标是要研究公司附近的出租房信息,但是我们在租房的时候也不是仅仅考虑距离这一个因素。
这里我准备获取标题、价格、区域(大概在哪一块)、看房人数(说明该房的受欢迎程度),楼层情况(高楼层还是低楼层),房租建筑时间等等。(就是你能看到的信息差不多都要弄下来哈哈)。
开始代码部分:
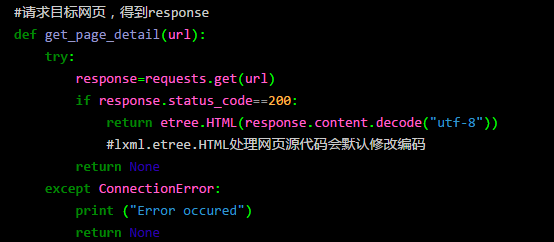
得到目标网页的 url 后,对其进行解析,采用的方法是先用 lxml 库的 etree 对 response 部分进行解析,然后利用 Xpath 进行信息获取。
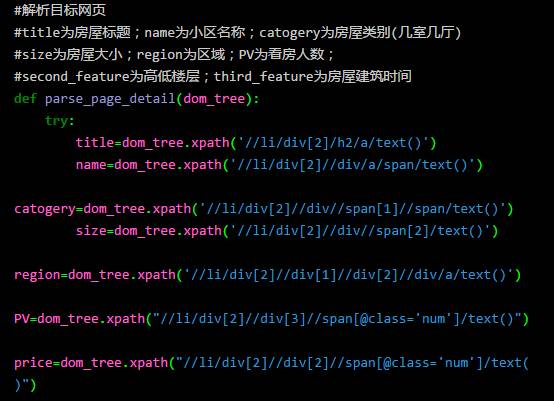
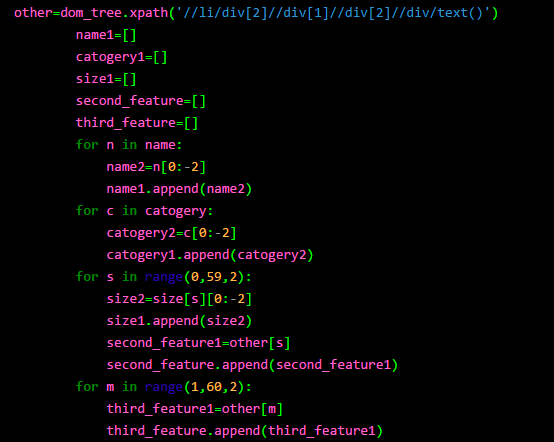
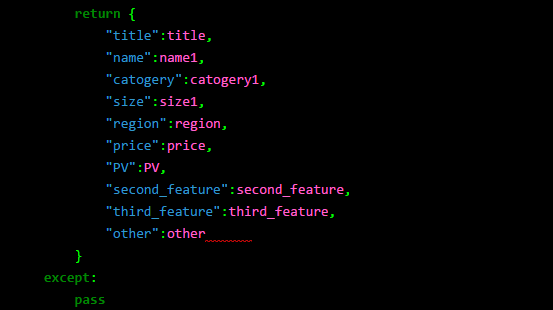
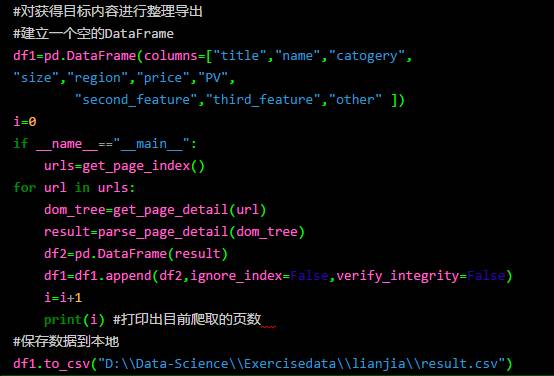

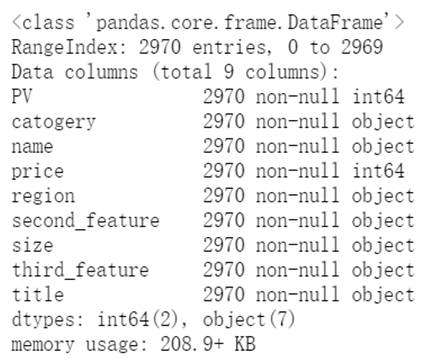
通过上图可以看出,我们一共抓取到 2970 条房屋信息,9columns。


经纬度的获取
我们刚刚只是获取了一些出租房的基本信息,但是我们要想计算距离还需要获得这些出租房所在的地理位置,即经纬度信息。
这里的经纬度是获取的区域层级的,即大概属于哪一个片区,本次爬取的 2970 条房屋信息分布在北京的 208 个区域/区域。
关于如何获取对应地点的经纬度信息,这里利用的 XGeocoding_v2 工具:
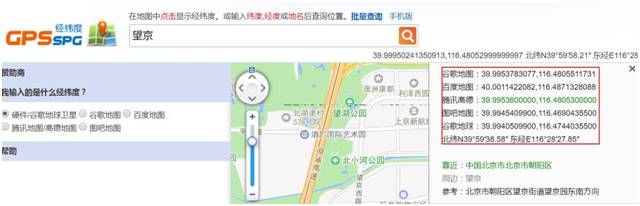
获取经纬度信息的地址如下:http://www.gpsspg.com/maps.htm
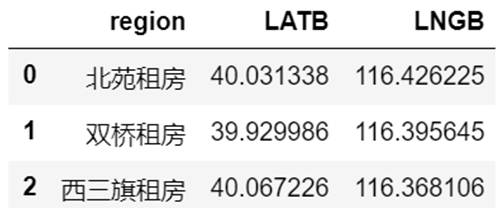
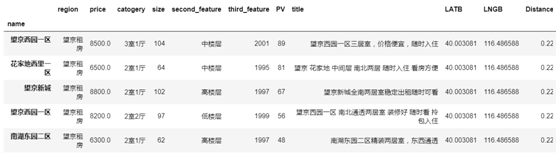
得到如下的结果(LATB 表示维度,LNGB 表示经度):
距离的计算
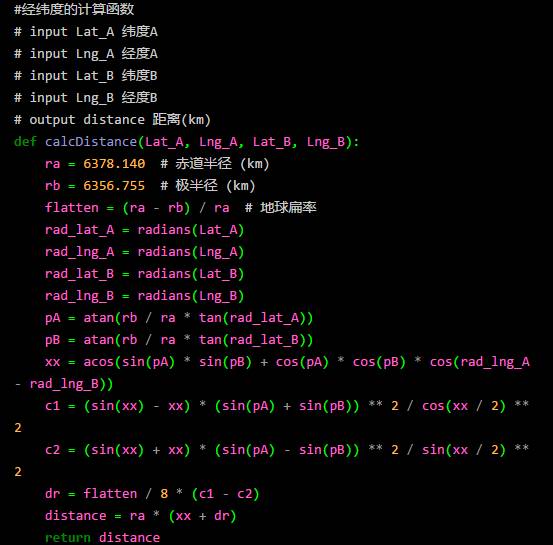
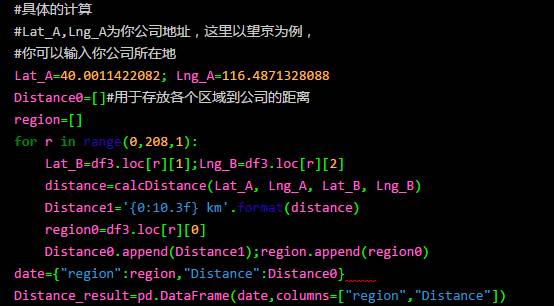
最后将距离以及区域与对应的小区拼接在一起,得到下面的结果。
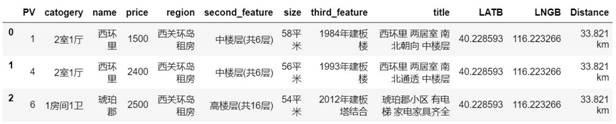
进一步分析

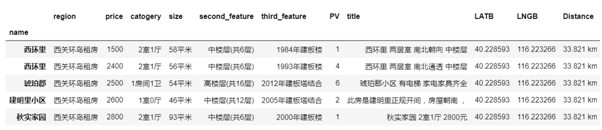




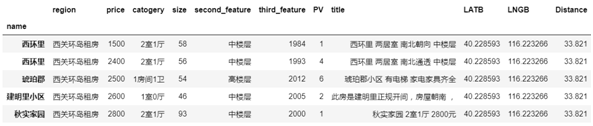

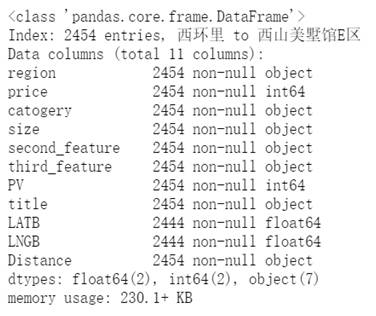
我们把后缀去掉了,Size、third_feature 和 Distance 看上去是数字,但是通过 df.info() 看出,这两个指标类型依然是 Object。为了进一步分析,我们要对它们继续进行处理。

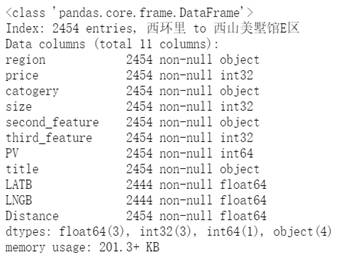
再次通过 df.info() 看出,该是数字类型的指标全部变成了 int/float 了,可以进行下一步了。


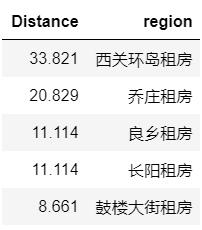

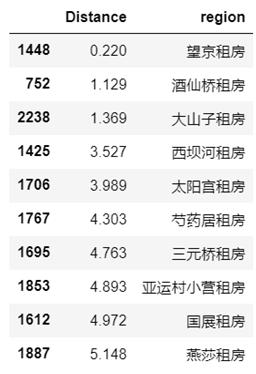
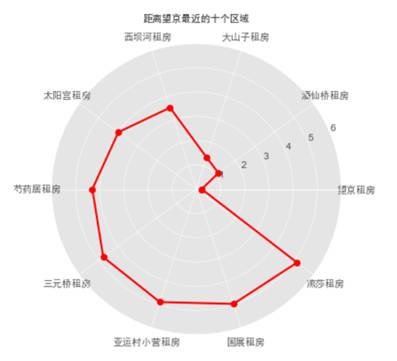
可以看到,Region=“望京”距离最近,所以我们重点在该区域内选择,接下来具体看看该区域内租房情况。

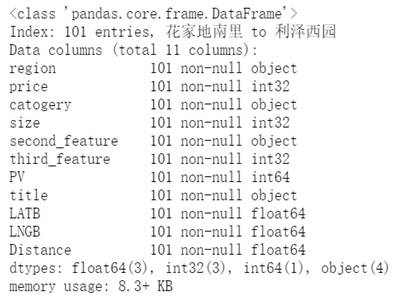
通过上表可以看到在望京区域总共有 101 套房源,接下来对这 101 套房源进行深入分析。

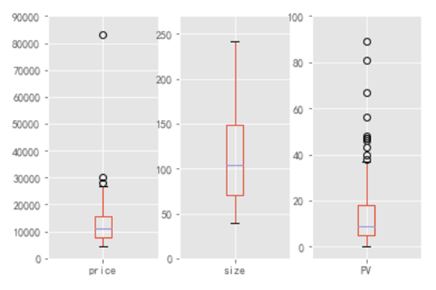
数据概览,先对该区域的租房整体情况有个认识,看到 Price 指标的下界为 5000 左右,上界接近于 30000,中位数为 10000 出头(有没有感觉到好贵哈哈哈哈),但是我们也看到有一个大于 80000 的超级异常值,我们利用截尾均值对他进行替代。
关于房屋大小,中位数为 100 平,这与 Price 中位数正好可以对应,折算下来相当于 1 平 100 大洋,在与那些 10 平左右的合租房需要 2000+ 大洋比一比,是不是觉得还是 100 平 10000 大洋便宜哈。
所以论一平米的价格的话还是整租更便宜。
先找出那个大于 80000 的异常值具体值是多少,然后进行值替换。




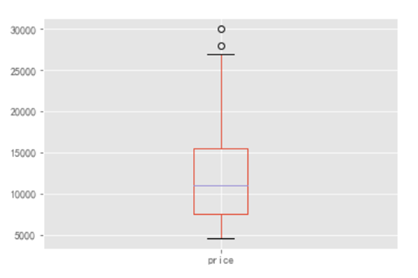
这是将 Price 异常值处理以后得到的箱型图,看起来就比较规范了哈。
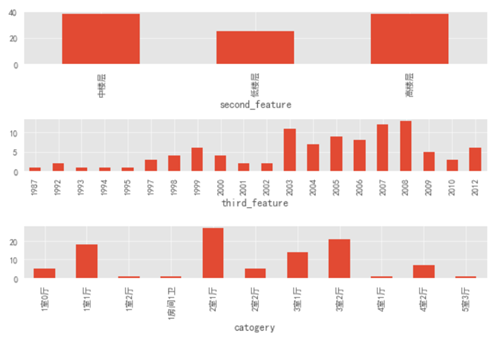
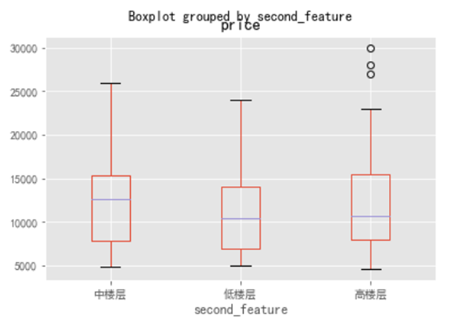
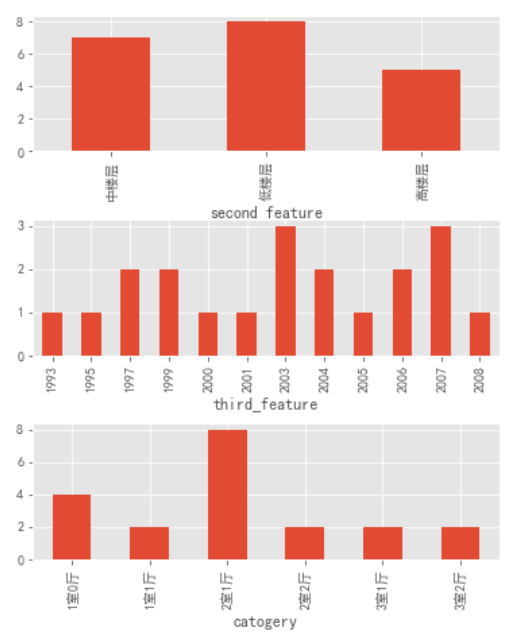
通过上图可以看出:中楼层和高楼层的房源绝对数量基本持平,高出低楼层数量一半。
房屋修建时间也是 2003 年以后的居多,这就和前面的楼层类型可以对应上了,在刚开始的时候(2003 年以前)大部分房子都是低楼层,随着时代的进步,科技的发展,人员的增多,楼层的数量和房屋的数量也随之增加。
房屋类型上的 Top3 类型分别为:2 室 1 厅、3 室 2 厅和 1 室 1 厅。

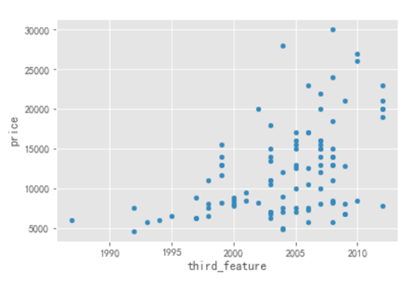
通过上图可以看出,随着时间的推移,2003 年以后的房子的 Price 要明显高于 2003 年以前的,如果要是对价格比较敏感,可以考虑 2003 年以前的房子。

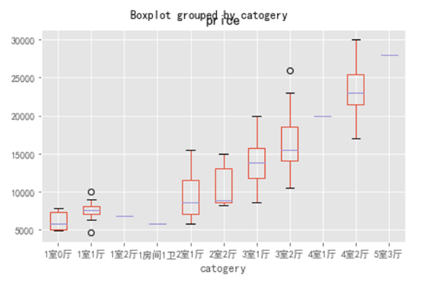
随着房屋类型的升级,价格也是随之升高,但是我们也发现,有一些三室房子的价格(下边界)要低于两室的价格的,如果对房间数量和价格都有要求的可以考虑这部分房源。



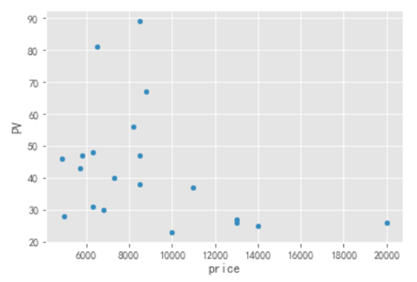
按 PV 进行降序,我们可以看出哪些房源是比较受欢迎,这些房源都有啥特征。


结论
通过上面的分析我们可以得出一些参考:

注:本次的数据为链家网的整租房源信息,非合租信息,所以你会看到价格都很高。
作者:张俊红

张俊红,中国统计网专栏作者,个人公众号ID:zhangjunhong0428,数据分析路上的学习者与实践者,与你分享我的所见、所学、所想。
看完本文有收获?请转发分享给更多人
欢迎关注“互联网架构师”,我们分享最有价值的互联网技术干货文章,助力您成为有思想的全栈架构师,我们只聊互联网、只聊架构,不聊其他!打造最有价值的架构师圈子和社区。
本公众号覆盖中国主要首席架构师、高级架构师、CTO、技术总监、技术负责人等人 群。分享最有价值的架构思想和内容。打造中国互联网圈最有价值的架构师圈子。
长按下方的二维码可以快速关注我们
如想加群讨论学习,请点击右下角的“加群学习”菜单入群






