「全文」解读苹果首篇GAN研究,精炼器可提升合成图像真实感
原文来源:machinelearning.apple.com
「机器人圈」编译:BaymaxZ
今天,神经网络最成功的案例是监督训练。然而,为了实现高精度,训练集需要大量、多样化和准确地标注,这是非常昂贵的。标注大量数据的替代方法是使用来自模拟器的合成图像。这是廉价的,因为没有标签成本,但合成图像可能不够现实,导致实际测试图像的泛化差。为了缩小这个性能差距,我们开发了一种改进合成图像的方法,使其看起来更逼真。我们表明,这些精细图像上的训练模型可以显着提高各种机器学习任务的准确性。
概论
标准合成图像上的训练机器学习模型是有问题的,因为图像可能不够现实,导致模型学习仅在合成图像中呈现的细节,并且不能很好地概括真实图像。弥补合成图像和实际图像之间的差距的一种方法是改进模拟器,这通常是昂贵且困难的,即使最佳渲染算法仍然无法对真实图像中存在的所有细节进行建模。这种真实感的缺乏可能会导致模型超越合成图像中的“不切实际”的细节。而不是模拟器中的所有细节建模,我们可以从数据中学习吗?为此,我们开发了一种改进合成图像的方法,使其看起来更逼真(图1)。
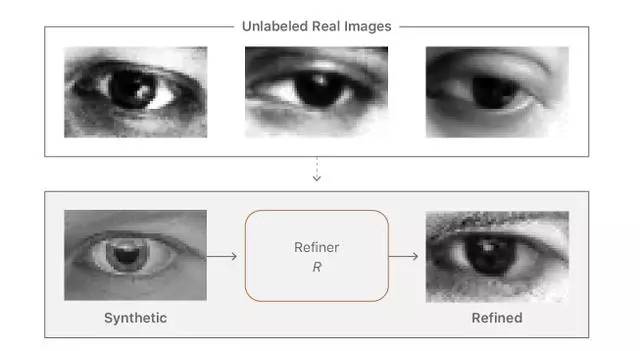
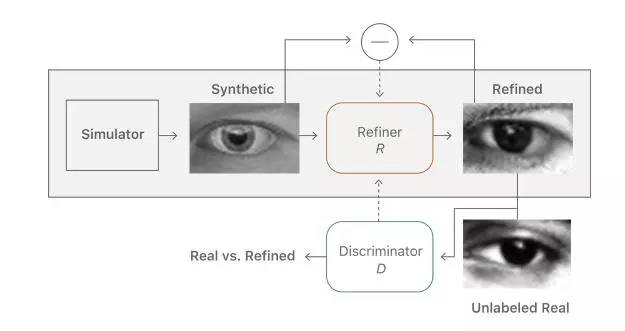
图1.任务是学习一个模型,使用未标记的实际数据从模拟器改进合成图像的真实性,同时保留标注信息。
“提高真实感”的目标是使图像尽可能逼真以提高测试精度。这意味着我们要保留标注信息来训练机器学习模型。例如,图1中的注视方向应该被保留,并且不会产生任何伪影,因为机器学习模型可能会学会过度使用它们。我们学习一个深层神经网络,我们称之为“训练网络”,它处理合成图像以改善真实感。
要学习这样一个训练网络,我们需要一些真实的图像。选择要求具有像素方向对应的实际和合成图像对,或者具有标注的真实图像,比如在眼睛的情况下的目光信息。这可以说是一个更容易的问题,但这样的数据很难收集。要创建像素方向的对应关系,我们需要渲染与给定的真实图像对应的合成图像,或者捕获与渲染的合成图像相匹配的真实图像。我们可以学习这个映射,而不是像素方面的对应关系,还是真实图像的任何标签?如果是这样,我们可以生成一堆合成图像,捕获真实的眼睛图像,并且根本没有标记任何真实的图像,学习这个映射,使该方法在实践中便宜且易于应用。
为了以无监督方式学习我们的训练网络,我们利用一个辅助鉴别网络,将真实和精细(或伪造)图像分为两类。训练网络试图欺骗这个鉴别网络,认为细化图像是真实的。两个网络交替运行,当鉴别器不能区分真实图像与假的图像时,训练停止。使用对抗鉴别网络的想法类似于将随机向量映射到图像的GAN(生成对抗网络[1])方法,使得生成的图像与真实的图像无法区分。我们的目标是训练一个精炼器网络—一个生成器—将合成图像映射到逼真的图像。图2显示了该方法的概述。
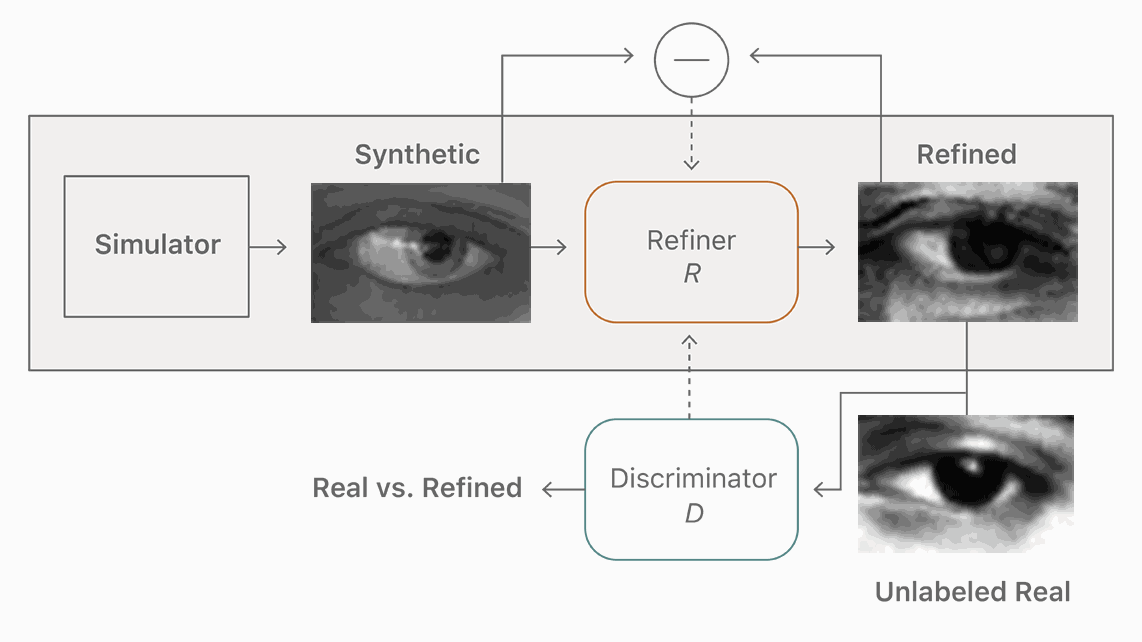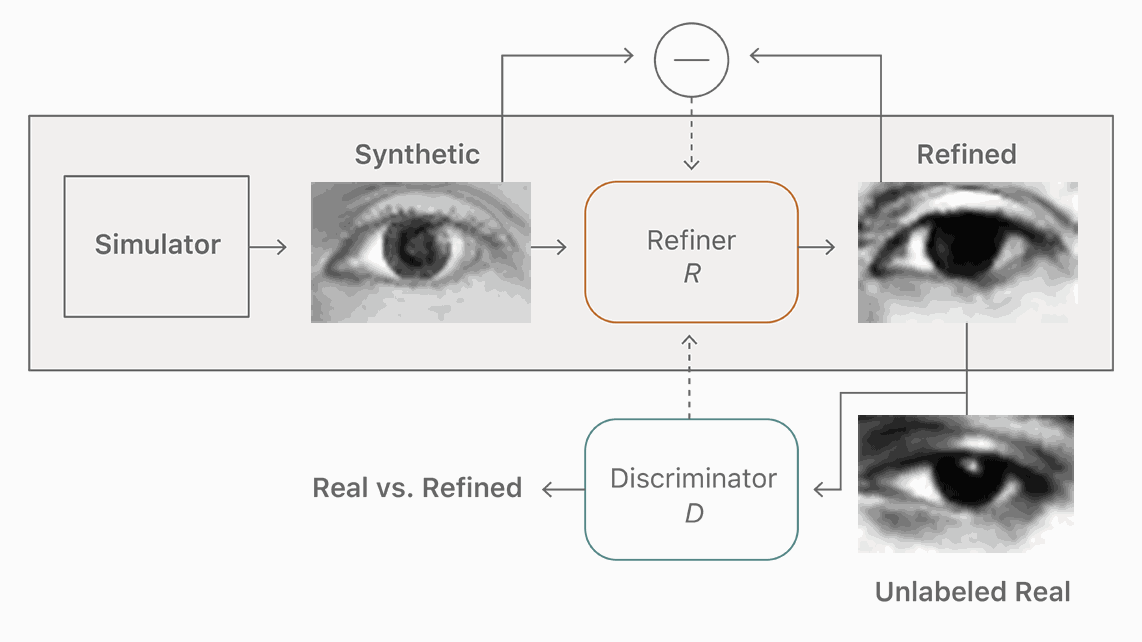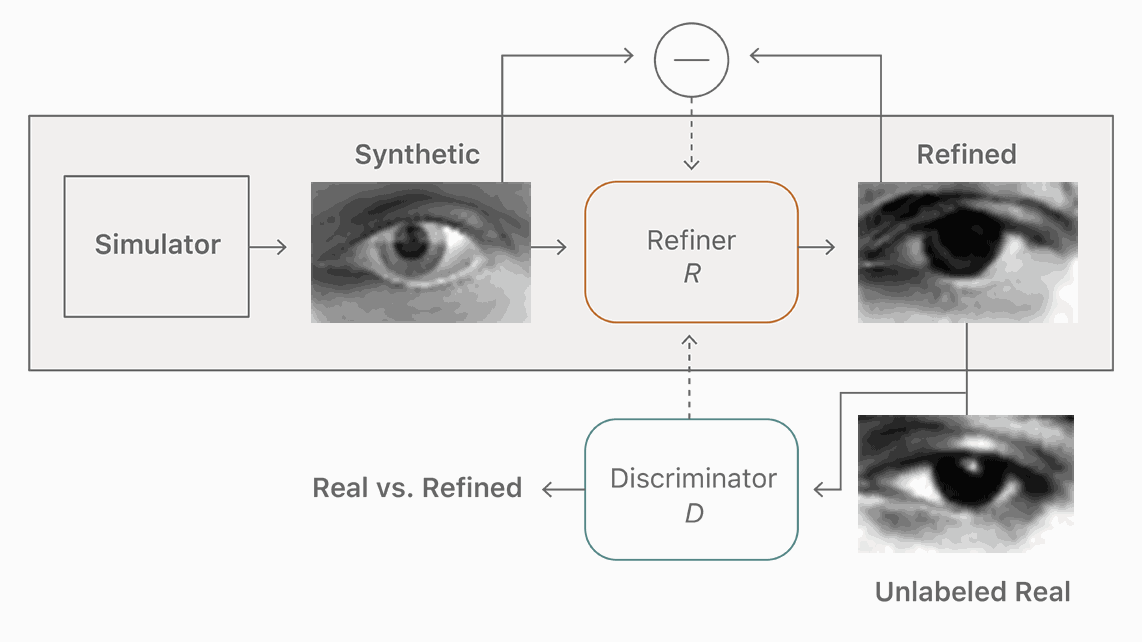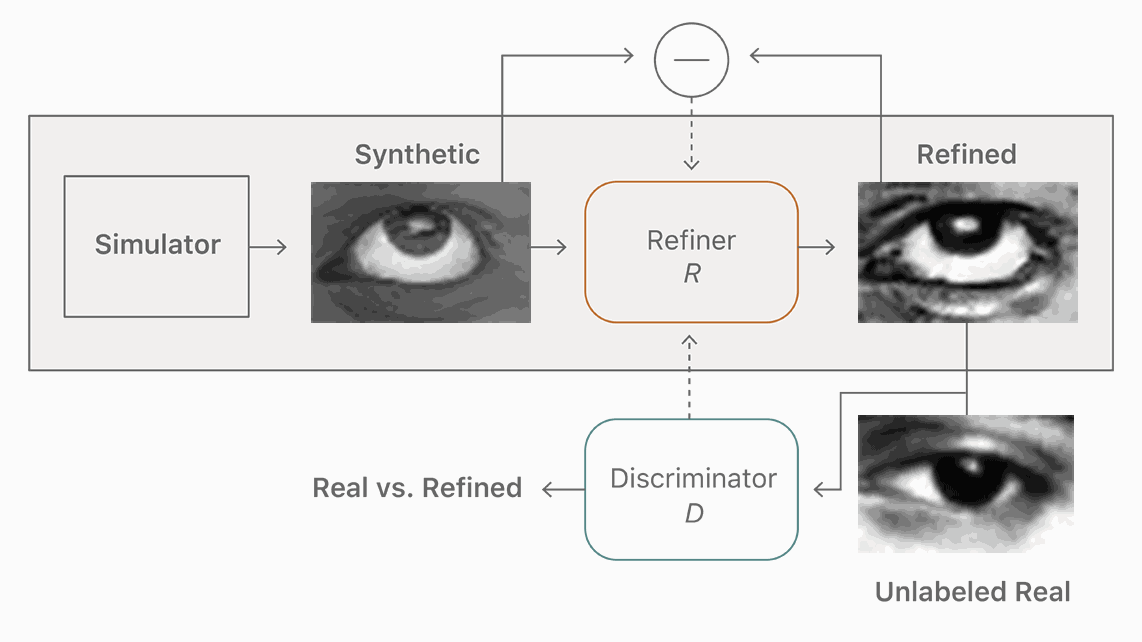
图2.我们的精炼器神经网络R最大限度地减少了局部对抗性损失和“自正规化”项的组合。 对抗性损失“欺骗”鉴别网络,D,它将图像分类为真实或精炼。自正规化项将合成和精细图像之间的图像差异最小化。精炼器网络和鉴别器网络交替更新。
我们如何保留标注?
除了生成逼真的图像之外,精炼器网络应该保留模拟器的标注信息。例如,对于目测估计,学习的变换不应该改变注视方向。该限制是启用使用模拟器标注使用精细图像的机器学习模型进行训练的重要组成部分。为了保留合成图像的标注,我们用自正规化L1损失补充对抗性损失,从而惩罚合成图像和精细图像之间的大变化。
我们如何防止人工因素?
进行本地更改
精炼器网络的另一个关键要求是,它应该学习建模真实图像特征,而不引入任何人工因素。当我们训练一个强鉴别器网络时,精炼器网络往往会过度强调某些图像特征,以欺骗当前的鉴别网络,导致漂移和产生伪像。一个关键的观察是,从精细图像采样的任何局部补丁应该具有与真实图像补丁相似的统计。因此,我们可以定义一个区分所有局部图像补丁的区分网络,而不是定义全局鉴别网络(图3)。该划分不仅限制了接收场,并且因此限制了鉴别器网络的容量,而且还为每个图像提供了许多样本来学习鉴别器网络。还通过对每个图像具有多个“真实感损失”值来改进精炼器网络。
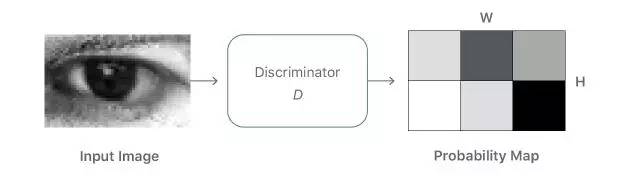
图3.局部对抗性损失的图示。鉴别器网络输出一个w*h的概率图。对抗性损失函数是局部补丁之间的交叉熵损失之和。
使用生成器历史来改进鉴别器
生成器可以使用来自新分布或目标(实际数据)分布的样本,欺骗鉴别器。从一个全新的分布中生成,只有鉴别器才能识别出全新的分布。生成器可以欺骗鉴别器的更有用的方法是通过从目标分布生成。
鉴于这两种演进方式,最简单的方法通常是产生一种全新的输出,这是我们在将当前生成器和鉴别器相互对准时观察到的输出。该非生产性顺序的简化图示于图4的左侧。生成器和鉴别器分布分别以黄色和蓝色显示。
通过引入存储来自前几代(图4的右侧)的生成器样本的历史,鉴别器不太可能忘记已经学习的空间的一部分。更强大的鉴别器有助于生成器更快地向目标分布。该图是一个简化,忽略了分布是复杂的,经常断开的区域。然而,在实践中,简单的随机替换缓冲器从先前的生成器分布捕获足够的分集,以通过加强鉴别器来防止重复。我们的想法是,在整个训练过程中的任何时间,由精炼器网络生成的任何精细图像真的是鉴别器的“假”图像。我们发现,通过构建D的小批次,从历史缓冲区中抽取一半样本,另一半从当前生成器的输出(如图5所示),我们可以改进训练。
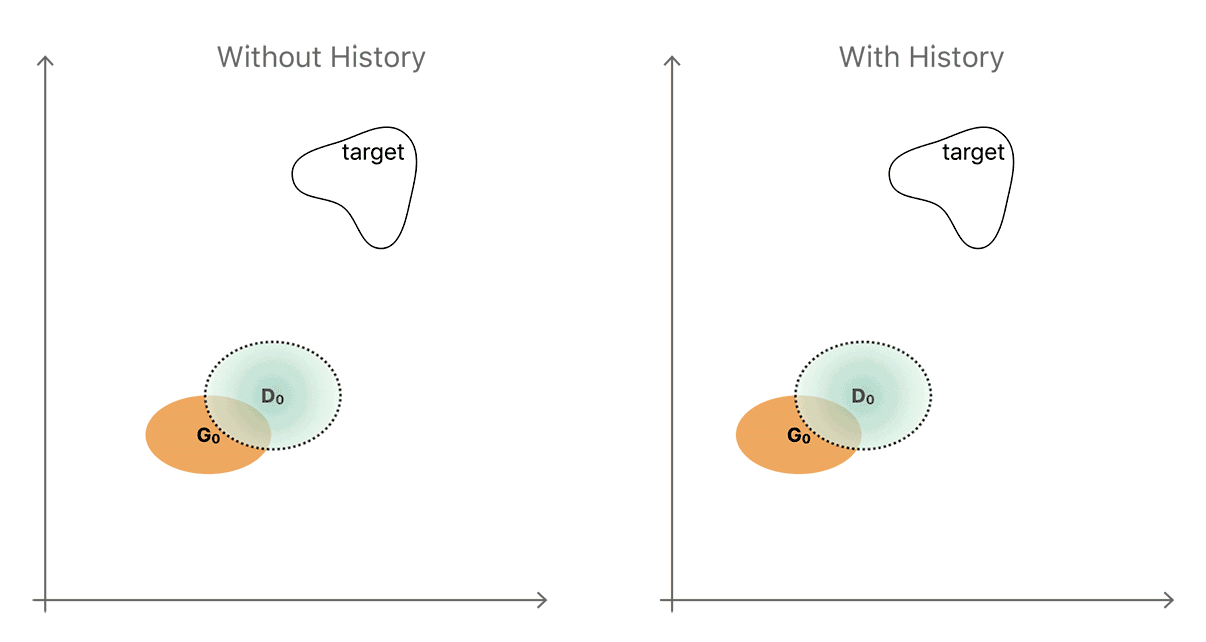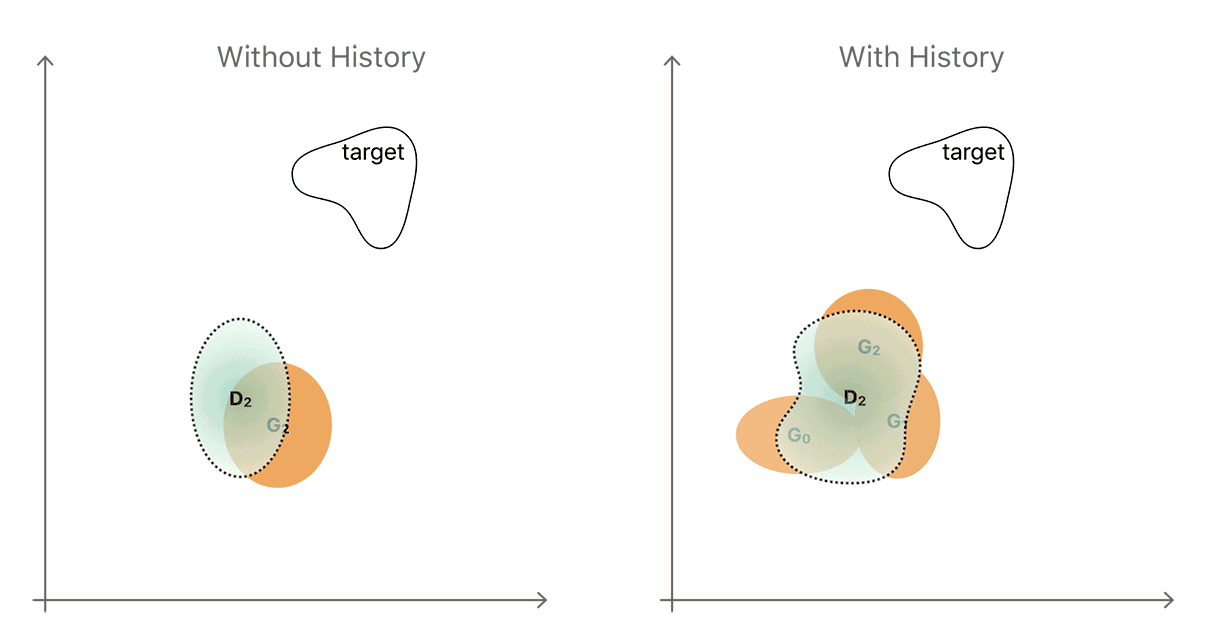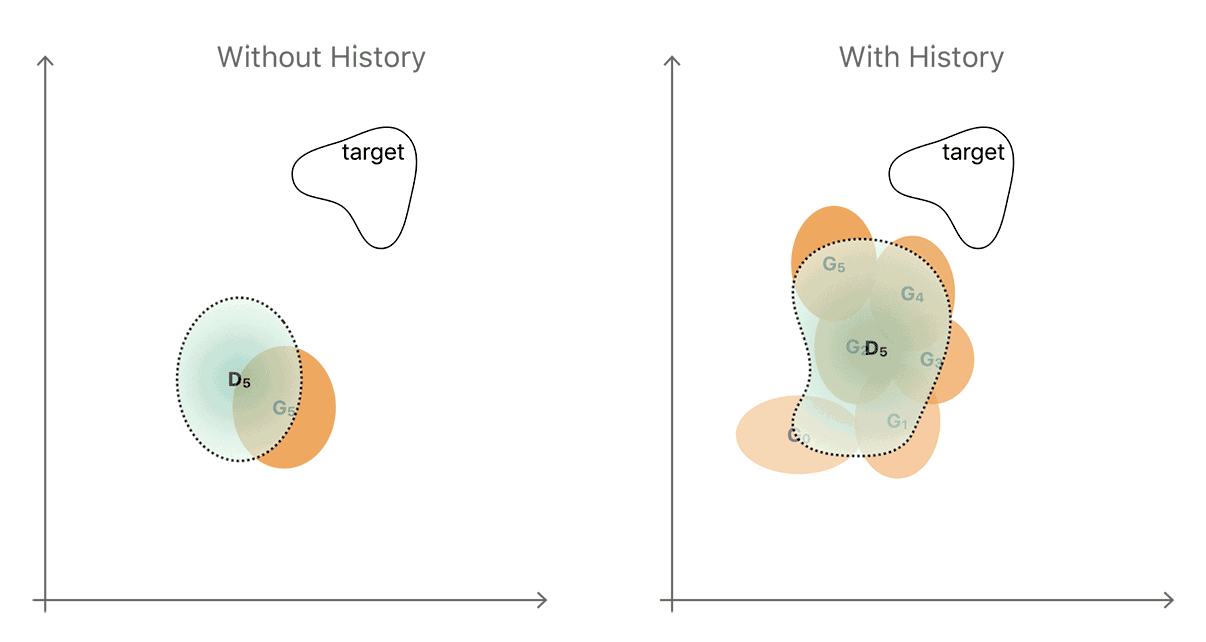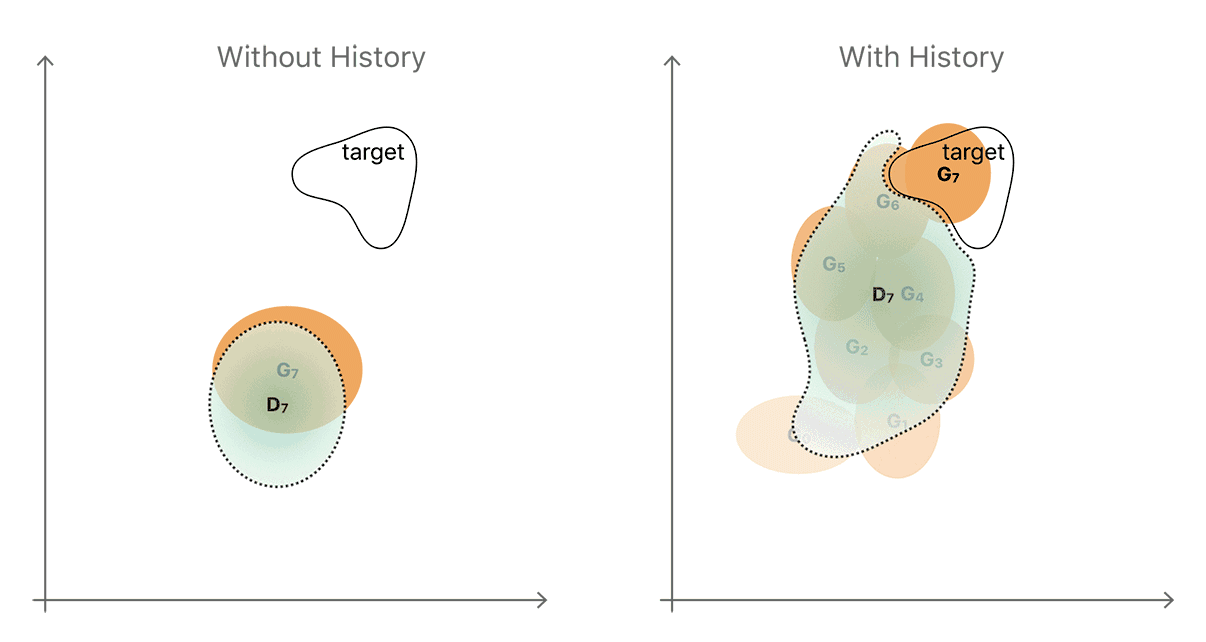
图4.使用图像历史以改善鉴别器的直觉的图示。
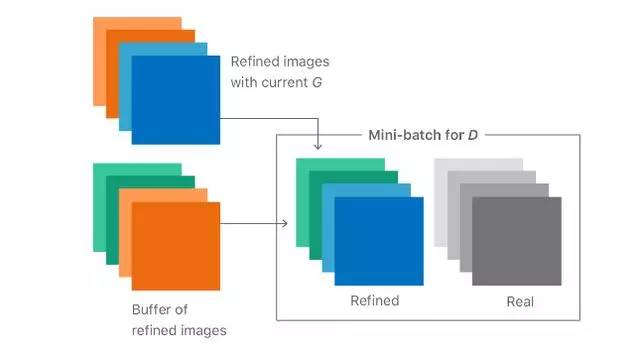
图5.具有D历史的迷你批次的图示。每个迷你批次都包含来自生成器当前迭代的图像,以及来自先前假图像的缓冲区。
训练进展如何?
我们首先训练精炼器网络只有自正规化损失,并在精炼器网络开始生成模糊的输入合成图像后引入对抗性损失。图6显示了在训练的各个步骤中的精炼器网络的输出。一开始,它生成了一个模糊的图像,随着训练的进行,它变得越来越真实。图7将不同训练迭代时的鉴别器和生成器损耗可视化。注意,鉴别器的损耗在开始时很低,这意味着它可以很容易地说明真实和精简之间的差异。缓慢地,鉴别器损耗增加,并且生成器损耗随训练进度而减小,生成更多的真实图像。

图6.随着训练进度的精炼器网络的输出。从模糊的图像开始,网络学习模拟真实图像中存在的细节。
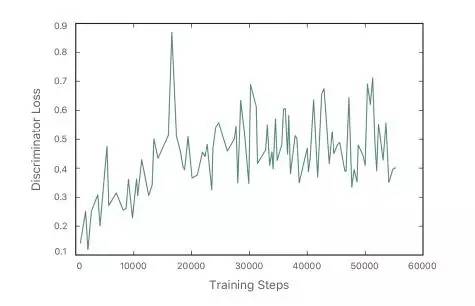
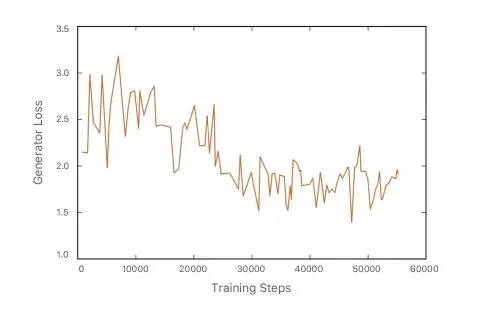
图7.随着训练的进行,生成器和鉴别器的损耗。
自正规L1损耗是否有限制?
当合成和真实图像在分布中具有显着的偏移时,像素方向的L1差异可能是限制性的。在这种情况下,我们可以用替代特征变换替换身份映射,在自己的特征空间放置一个自定义符。 这些可以是手动调整的功能,或者学习的功能,如VGGnet的中间层。例如,对于彩色图像细化,RGB通道的平均值可以产生逼真的彩色图像,如图8所示。
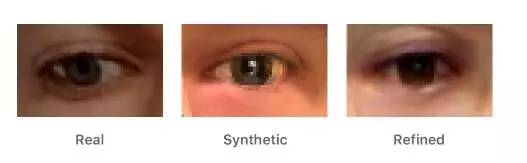
图8.特征空间中的自正规化损失示例。
标签是否由生成器改变?
为了验证标签没有显着变化,我们在合成和精细图像上手动绘制椭圆,并计算其中心之间的差异。在图9中,我们显示了50个这样的中心差异的散点图。合成和相应精致图像的估计瞳孔中心之间的绝对差异非常小:1.1 +/- 0.8px(眼宽= 55px)。
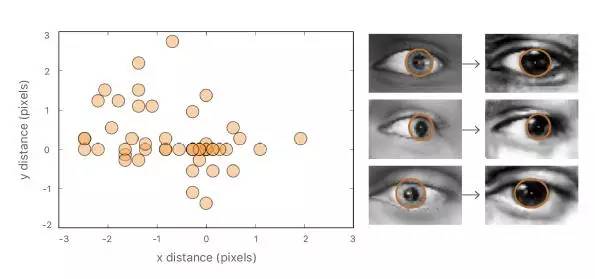
图9.合成图像和实际图像的瞳孔中心之间的距离的散点图。
如何设置超参数?提示与技巧。
G的初始化
首先,我们用自正则化损失初始化G,以便它可以开始生成模拟版本的合成输入。通常,G(没有训练D)需要500-2,000步。
首先,我们用自正则化损失初始化G,以便它可以开始生成模拟版本的合成输入。通常情况下,G需要五百到两千步(没有训练D)。
每个训练迭代G和D的不同步骤
我们在每个训练迭代中使用了不同数量的步进生成器和鉴别器。对于具有深度的手势估计,我们对于每个D步骤使用G的两个步骤,并且对于眼睛注视估计实验,我们最终对于每个D步骤使用50个步骤G。我们发现鉴别器与生成器相比更快地收敛,部分是因为鉴别器中的批量规范。所以我们将#D步骤修改为1,并从小数字开始变化#G步骤,根据鉴别器丢失值缓慢增加。
我们在每个训练迭代中使用了不同数量的步进生成器和鉴别器。对于具有深度的手势估计,我们对于每个D步骤使用G的两个步骤,并且对于眼睛注视估计实验,我们最终对于每个D步骤使用五十个步骤G。我们发现鉴别器与生成器相比更快地收敛,部分是因为鉴别器中的批量规范。所以我们将#D步骤修改为1,并从小数字开始变化#G步骤,根据鉴别器丢失值缓慢增加。
学习率和停止标准
我们发现保持学习率非常小(〜0.0001),训练很长时间是有帮助的。这种方法可能是因为它使发电机或鉴别器不会发生突然的转移,这会使另一个发生故障。我们发现难以通过可视化训练损失来停止训练。相反,我们保存训练图像作为训练进度,并且当精细图像看起来与真实图像视觉相似时,停止训练。
定性结果
为了评估精细图像的视觉质量,我们设计了一个简单的用户研究,其中被摄体被要求将图像分类为真实或精细的合成。受试者发现真正和精致的图像之间很难区别。在我们的总体分析中,10个受试者在1000次试验中选择了正确的标签517次,这意味着它们不能可靠地区分真实图像和精制合成图像。相比之下,当对原始合成图像与真实图像进行测试时,我们显示每个受试者10个实际和10个合成图像,受试者在200次试验中正确选择了162次。在图10中,我们展示了一些合成和对应的精细图像。
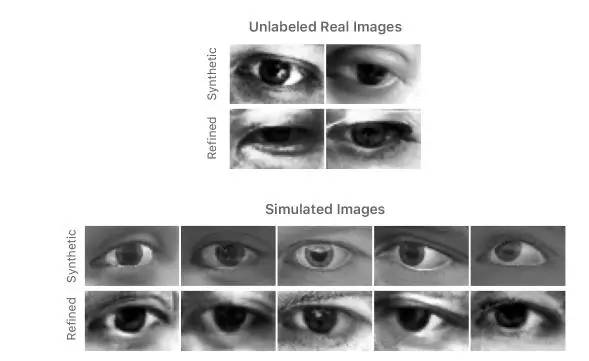
图10 使用上述的方法实际生成精细的眼睛图像。
定量结果
图11显示了使用精细数据的改进,与使用原始合成数据的训练相比。 从图中可以看出两点:(1)使用精细图像进行训练优于使用原始合成图像的训练,(2)使用更多的合成数据可进一步提高性能。在图12中,我们将目光估计误差与其他最先进的方法进行比较,并且表明改进真实感有助于模型推广实际测试数据。
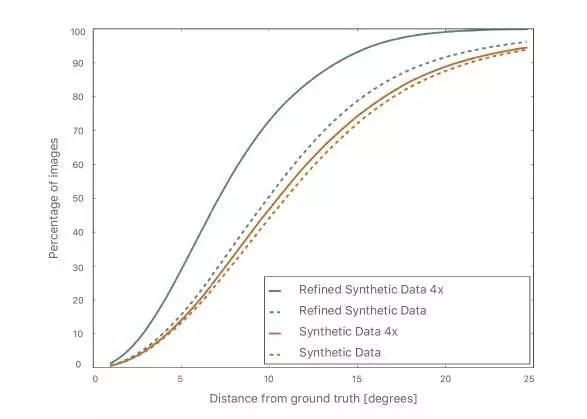
图11 使用合成和精细图像进行注视估计的训练比较。对实际测试图像进行评估。


中国人工智能产业创新联盟在京成立 近200家成员单位共推AI发展

关注“机器人圈”后不要忘记置顶哟
我们还在搜狐新闻、机器人圈官网、腾讯新闻、网易新闻、一点资讯、天天快报、今日头条、QQ公众号…
↓↓↓点击阅读原文查看中国人工智能产业创新联盟手册



