不想云厂商坐收渔翁之利,Kafka 团队修改 KSQL 开源许可
(给Linux爱好者加星标,提升Linux技能)
来源:开源中国社区
www.oschina.net/news/102737/license-changes-confluent-platform
15 日,Confluent 宣布修改其平台部分组件的开源许可,从 Apache 2.0 切换到 Confluent Community License。

新的 Confluent 社区许可允许用户免费下载、修改和重新发行代码,这点类似于 Apache 2.0,但是不允许将其作为 SaaS 产品提供给用户。流数据 SQL 引擎 KSQL 将受到新许可的影响,而由于 Kafka 是 Apache 软件基金会的一部分,它将继续使用 Apache 2.0 许可,此次修改方案只会影响到由 Confluent 维护的开源组件。
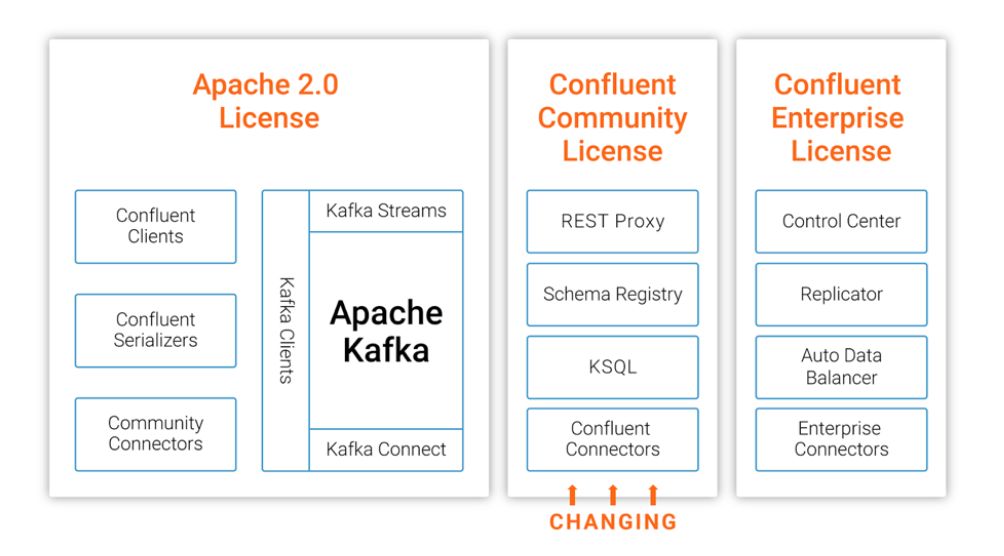
Confluent 解释,新的授权方式下,用户仍然可以将 KSQL 等应用作为产品或服务的一部分,无论这些产品是作为软件发行还是作为 SaaS 服务提供给用户都可以,但不能用它创建类似“KSQL 即服务”这样的东西。
至于为什么这么做,Confluent 表示,云厂商将产品作为 SaaS 提供给用户,他们具有显著的优势,可以控制资源的定价,并且可以在他们的所有产品中集成自己的服务。而在这其中,有一些云厂商会与开源公司合作,由开源公司提供云系统的托管版本,并作为服务提供给用户。但是其它公司则直接将开源代码放到他们的云产品中,并投入资金开发差异化的专有产品。Confluent 认为这无可非议,作为一家公司,可以考虑构建更多的专有软件,并减少开源方面的投入。但是从其自己的角度来看,构建基础设施层的正确方式应该是使用开源代码,而随着工作负载不断迁移到云端,需要有一种机制在保持自由的同时实现投资周期。
Confluent 表示,组件的开发仍然是开放的,并且继续接受 PR 和功能建议,同时其还会继续在开发上大量投入。而对于那些非商业云提供商用户来说,新许可并没有实质上的限制。
推荐阅读
(点击标题可跳转阅读)
看完本文有收获?请分享给更多人
关注「Linux 爱好者」加星标,提升Linux技能





