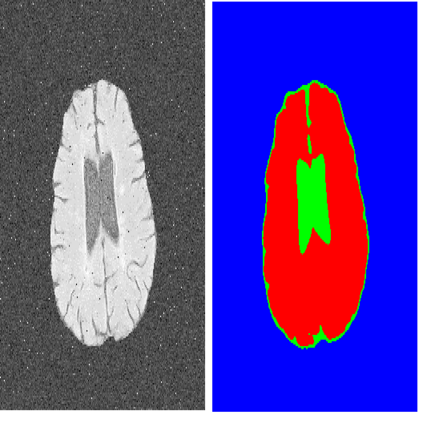
Kaggle大神分享:图像分割的「奇技淫巧」
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
本文转载自机器之心。
一个经历了 39 场 Kaggle 比赛的团队在 reddit 上发帖表示,他们整理了一份结构化的图像分割技巧列表,涵盖数据增强、建模、损失函数、训练技巧等多个方面,不失为一份可以参考的图像分割技巧资料。


使用高斯差分方法进行斑点检测;
使用基于图像块的输入进行训练,以减少训练时间;
加载数据时,用 cudf 替换 Pandas;
确保所有图像保持相同的方向;
使用 OpenCV 对所有常规图像进行预处理;
采用自主学习并手动添加注释;
将所有图像调整成相同的分辨率,以便将相同的模型用于不同厚度的扫描等。

用 albumentations 包进行数据增强;
使用 90 度随机旋转;
使用水平、垂直翻转或这两个方向都做翻转;
尝试进行复杂的几何变换,包括弹性变换、透视变换、分段仿射变换、枕形失真;
应用随机 HSV;
使用损失较小的增强数据进行泛化,以防止有用图像信息丢失;
应用通道 shuffle;
根据类别频率进行数据扩充;
应用高斯噪声等。
使用基于 U-net 的架构;
用 inception-ResNet v2 架构得到具备不同感受野的训练特征;
经过对抗训练的 Siamese 网络;
以密集(FC)层作为最后一层的 ResNet50、Xception、Inception ResNet v2 x 5;
使用全局最大池化层,无论输入尺寸如何,该层都将返回固定长度的输出;
使用堆叠的膨胀卷积;
VoxelNet;
用 concat 和 conv1x1 替换 LinkNet 跳跃连接中的加号;
广义平均池化;
用 3D 卷积网络在图像上滑动;
使用在 Imagenet 数据集上预训练的 ResNet152 作为特征提取器等。
dice 系数:能够很好地处理不平衡数据;
加权边界损失:减少预测分割与真值之间的距离;
MultiLabelSoftMarginLoss:基于最大熵优化多标签一对多损失的标准;
具备 logit 损失的平衡交叉熵(Balanced cross entropy,BCE):以特定系数权衡正例和负例;
……

尝试不同的学习率;
尝试不同批大小;
使用带有动量项的 SDG,并且手动设置学习率衰减;
数据增强过多会降低准确率;
使用裁剪后的图像训练,并在完整的图像上做预测;
在学习速率调整上使用 Keras 中的 ReduceLROnPlateau() 方法;
冻结除了最后一层以外所有的网络层,并使用 Stage1 中的 1000 张图片进行模型微调;
开发一个能使标签更加均匀的采样器;
使用类别感知采样(class aware sampling)等。



测试时增强(Test Time Augmentation,TTA):向模型多次展示经过不同随机变换的图像,取预测平均值;
均衡使用测试预测概率,而不是仅使用预测类;
将几何平均数应用于预测;
在推理过程中将图块重叠,使每个边缘像素至少覆盖 3 次,因为 UNET 在边缘区域范围的预测往往较差;
非极大抑制和边界框收缩;
分水岭后处理:在实例分割问题中分离对象。

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

投稿、合作也欢迎联系:simiter@126.com

长按关注计算机视觉life
给优秀的自己点个赞