蚂蚁金服 30 万级测试用例的核心应用如何分钟级运行?

互联网行业的最主要属性是快,一方面是量的快速增长;另一方面是业务场景的多样化变更。每年的交易量都增长得非常快速,同时业务也快速丰富起来,之前可能只有线上电商担保交易,现在新增了许多金融属性的业务如花呗、借呗、相互保,甚至还有跨境支付。同时,蚂蚁金服具备的金融属性,要确保监管合规和资金安全,需要把稳放到首位,我们需要在这个稳的基础上去快速创新以满足市场的快速变化。也就是说要“又稳又快”。
把又稳又快深入到软件开发,「稳」要求软件质量可靠;「快」体现在研发队伍快速扩张和代码量的快速增长。在这种背景下,对于 CI(持续集成)的研究和改造成为保障软件质量可靠又快速交付的有效手段。
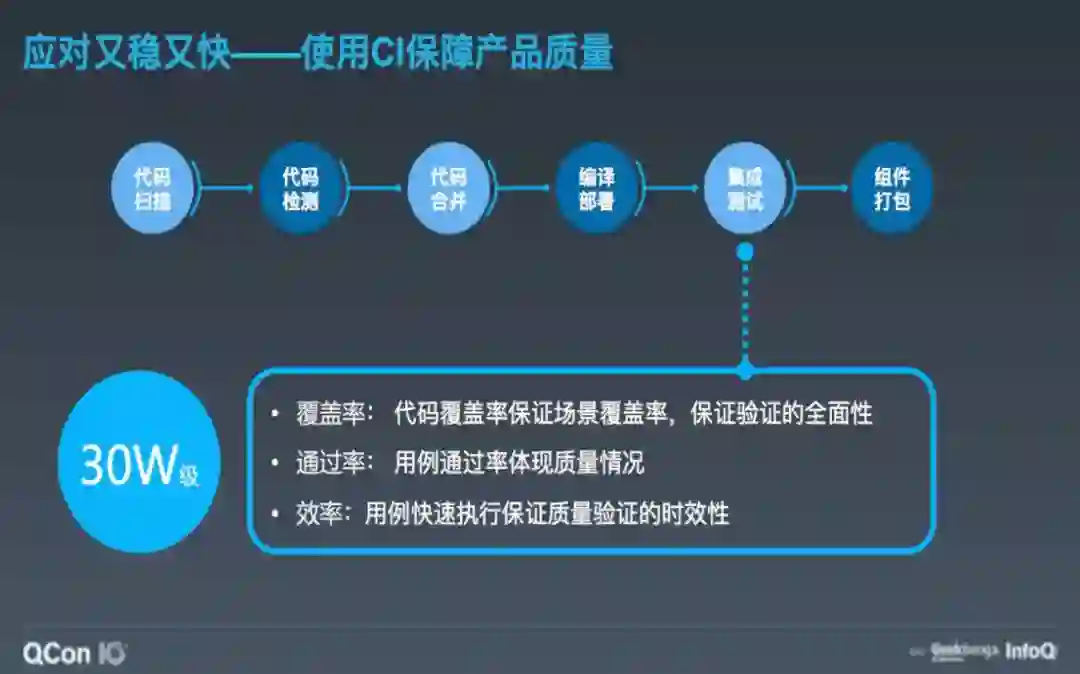
要实现通过 CI 来保障软件产品的质量,首先要对 CI 的全部流程做分解,CI 包含代码扫描、代码检测、代码合并、编译部署、集成测试、组件打包等环节,其中集成测试应该是保障软件质量的核心环节,如何考量集成测试是否做得到位呢?
在蚂蚁金服有三个指标:
覆盖率:业务场景的覆盖率或者比较直观的代码覆盖率,体现测试是否完整全面。
通过率:产品质量的优劣表现。
执行效率:用例快速执行保证质量验证的时效性。
三者中最基本的是覆盖率,而为了保证覆盖全面需要增加大量的用例,30 万级的用例诉求应运而生。
先回顾一下最早进行 CI 的情况。在没有 30 万级用例的诉求之前,业务和用例都相对较少,我们能使用定时 CI 的方法,即每天定时执行几次 CI,CI 平台只通过搭建一个 Jenkins 集群进行执行。虽然当时 CI 的执行效率不高,但因为频率低,且一般是在非工作时间执行,没有给日常的研发工作带来负担和困扰。
随着业务快速发展,研发团队快速扩张,每天代码的提交次数和代码合入量增长非常快,定时执行 CI 已经不能够很好满足验证需求,于是就引发了研发模式的变化,对于 CI 来说,最大的变化是从定时触发变成了 pull Request 触发,且每次 PR 都会触发执行一次 CI。
这个变化对 CI 带来了三大冲击:
因为触发频率大大增加而引发的任务量激增。
反馈快速。之前定时执行无感知,现在 PR 触发,开发同学都期望能够快速得到验证结果。
通过率稳定。一方面是要求大量任务下 CI 平台要稳定;另一方面由于用例越来越复杂,会有一些依赖和干扰,要求通过率的稳定。
基于这三大冲击带来的挑战,有两个层面的难题需要重点解决:
执行效率低。
通过率不稳定。
解决执行效率低问题的一个难点是会碰到通过率不稳定的问题。前面已经说过,CI 里面最耗时的环节是集成测试,在集成测试中又包含下载代码、下载依赖(以 Java 工程为例)、编译、执行用例、报告解析等步骤。其中,又以执行用例最为耗时。
在蚂蚁金服的集成测试是基于 testng 的基础上,考虑到可以通过使用 testng 本身的多线程并行来解决执行效率低的问题。但通过配置,我们发现这个多线程并行效果并不好,不仅没有怎么提速,还导致了通过率下降。
经过分析,主要原因有三:
执行机配置低,多线程并行效果不明显。
多线程执行用例间互相影响导致通过率下降。
一些框架和代码的原因,导致不适合使用多线程并行。


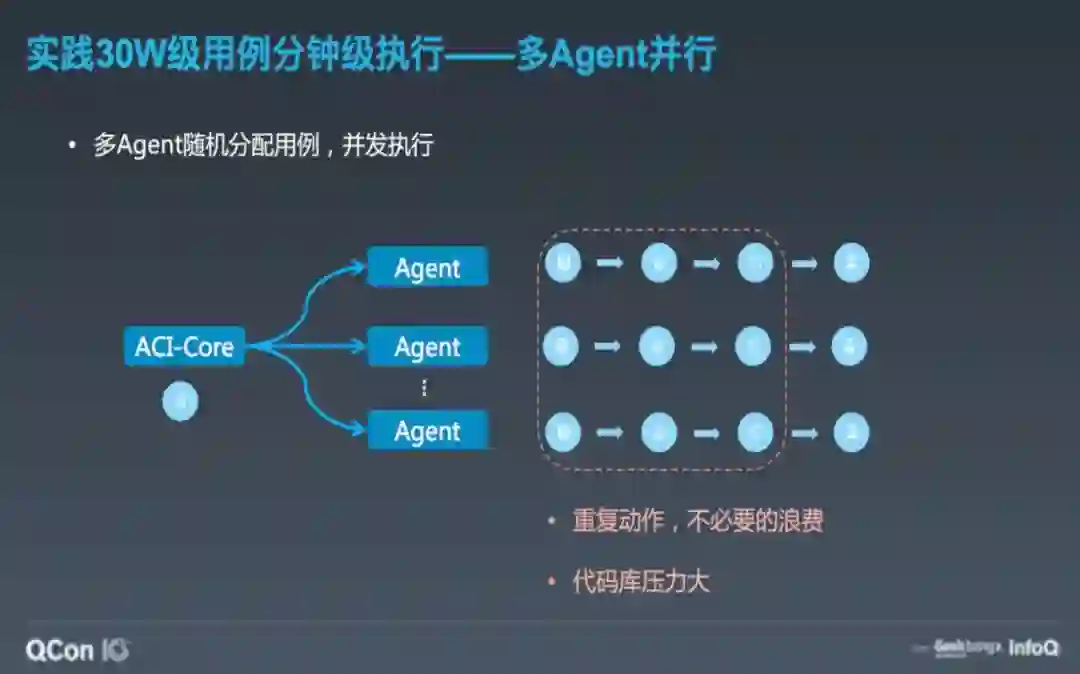
在单机多线程无法解决的情况下,选择通过多机并发进行解决,通过采用分布式多 Agent 随机分担测试用例的方式来执行。
这样做了之后,确实非常明显的提升了执行效率,但我们发现 agent 上做了很多重复的事情,如下代码、下依赖、编译。这些事情只需要做一次即可,多做会造成不必要的浪费,在降低资源利用率的同时对代码服务也产生了比较大的压力。因此就使用主辅 agent 的方式做了进一步优化。主 agent 负责将公共的事情(下代码、下依赖、编译)做完,只做一遍。辅助 Agent 在主 agent 产物的基础上做用例执行。
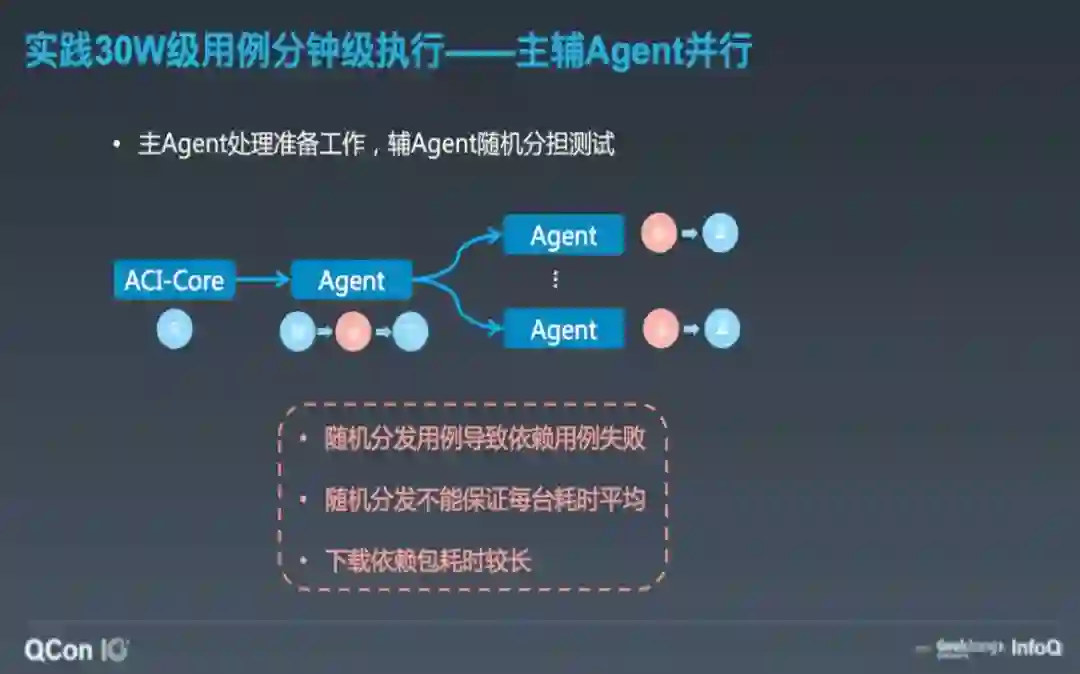
经分析发现是由于某些用例间是有依赖或者顺序关系的,这些用例必须运行在同一台 Agent 执行机上。于是选择在代码库中增加了一个 yaml 配置文件,在 yaml 文件中对用例进行分组,将有依赖关系的用例配置成一个分组,在执行用例分发的时候按照分组来分发即可。同时还对 agent 增加了 maven 缓存,每次运行就不需要全量下载依赖了,也有一定的提速效果。
这样做了之后,稳定的通过率有了保障,但是不同用例的运行时间不一样长,我们没有办法保证每次运行多个 agent 的执行耗时都比较平均。也就是说虽然多机并发了,但最终的完成时间取决于分组中最慢的那一台。

于是,我们又将用例分成两类:
有依赖关系的用例,需要在同一台 Agent 上执行。D-TestGroup (Dependency-TestGroup)。
无依赖关系的用例,可随机分发。C-Test (Common-Test)。
对于这两类用例,我们采用不同的分发策略,D-TestGroup 按照 Group 分发,在 Agent 将领到的 D-TestGroup 执行完成后,就自己主动去拉取 C-Test 执行,拉取的粒度可以配置,可以是一个用例一个用例的拉,也可以是多个多个,这种机制我们称为动态分发,通过对 testng 做了一些改造来实现。动态分发使得每次执行都能够尽量的将多台 Agent 的执行耗时比较平均。至此,基本解决了执行效率慢和用例干扰原因造成的通过率不稳定问题。

最初尝试了testng本身的多线程并发,效果不好;
进而使用了多机并发,又改进成主辅Agent多机并发,提速明显,但通过率不稳定;
之后我们又通过人工分组解决依赖用例的问题,稳定了通过率;
最后通过动态分发+人工分组的方式使得多机并发的Agent执行耗时比较平均。
一个核心应用之前是 1 万用例运行需要 90 分钟,优化后 30 万用例只需要 30 分钟。这不是一个特例,我们将这一套机制在内部推广,平均提速达到 30% 以上,对用例数多的应用提效尤其明显。

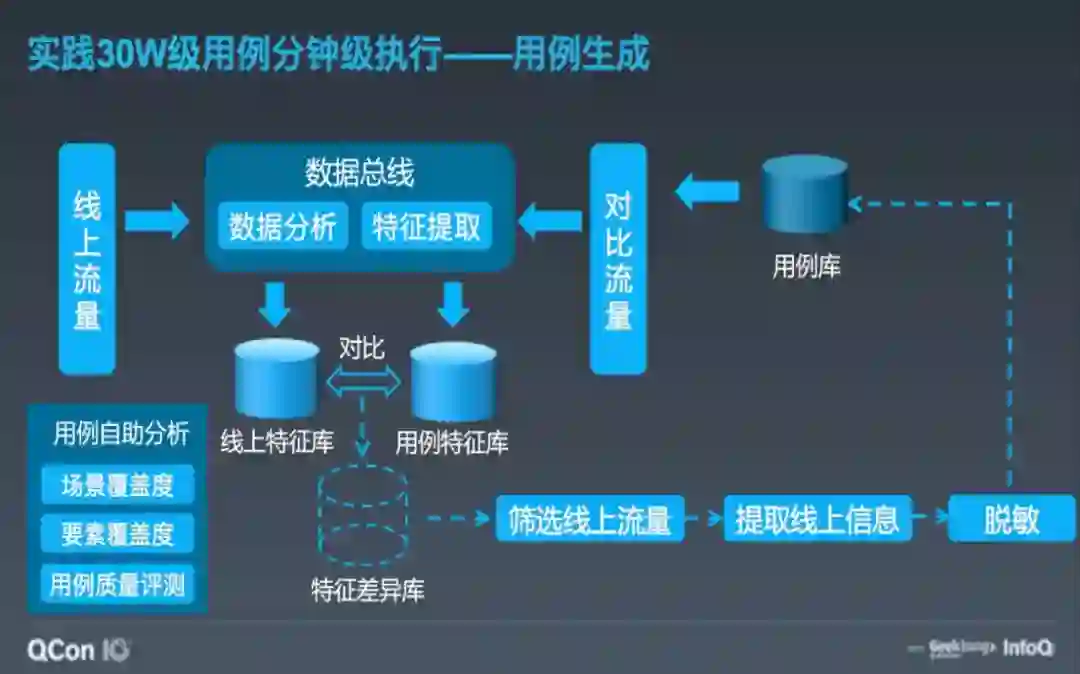
大家可能会有一个疑问,30 万级用例是可以分钟级执行了,通过率也稳定了。可是这么多的用例是怎么生成的呢?用例的编写是开发人员一个很大的挑战,面对枯燥重复的工作,需要耗费很长的时间。
于是我们想有没有办法根据线上的流量自动生成呢?通过中间件插件的方式将线上的流量数据采集下来发送到数据总线,数据总线对线上流量做数据分析和特征提取,落库到线上特征库。通过线上特征库与存量用例特征库的对比得出特征差异库,对特征差异库再进行筛选、提取和脱敏生成新的用例再补充道用例库中。通过这种方式循环,不断生成新的用例,最终达到了 30 万级用例的规模。
在对执行用例这一环节不断优化改进的同时,我们的 CI 架构也进行了演进。主要是为了应对之前说的研发模式变更带来的任务量激增的冲击,以及满足对 CI 平台本身稳定性的要求。
在初始的时候,任务量较小,用例也不多。CI 可以说是没有架构的,可以称为架构 0.1,我们只是简单的搭建了一个 Jenkins 的集群。后来由于研发模式的变化,搭建了多套 Jenkins 集群,并将多个 Jenkins 集群抽象为 CI 的执行层 ACI-Executor。多套 Jenkins 集群一方面提升了 CI 平台的任务吞吐量,使其具备了大量任务并行的能力,另一方面也保障了 CI 平台的稳定性,不再依赖单个 jenkins 集群的健康度。
有了执行层的集群,就需要对任务进行调度和编排,以及对集群本身的管理、监控等。于是在执行层之上又增加了调度层 ACI-Core。最后在调度层之上建设业务层,对 API 进行封装,暴露给外围的 DevOps 平台 LinkE、代码托管平台 AntCode 等系统使用,同时响应定时、PR、Push 等事件,转换任务模板,展示执行完成后的报告等,整个架构演进到 1.0。
这个架构看起来是比较完整了,在实际使用中,我们发现两个新问题:1、CI 任务高峰期排队,低谷期 CI 机器闲置。2、新语言、新的技术栈、中间件版本要求环境多样化。
为了解决这两个问题,对执行层和调度层做了进一步的演进,也就是架构 2.0。在执行层引入 Kubernetes 和 Docker,一方面借助 Kubernetes 的容器编排能力削峰填谷,另一方面通过 Docker img 定义不同的环境,应对多语言、多技术栈版本的要求。在调度层引入 Tekton 对接 Kubernets,编排 Pipeline。
蚂蚁金服将持续对 CI 进行探索和实践,未来的发展将围绕以下四个关键词:效率、云原生、中台能力、智能化。
效率,对我们的软件生产活动有最直接的提速效果,或许能够使用更精细的调度、编排,目前还没有做到用例级别,还只是测试方法级别,如果未来能够做到用例级别,可能会有更多的调度玩法。另外在 CI 中集成测试和编译打包两个环境都有编译的动作,能不能让集成测试复用编译的结果,在编译结果的基础上执行测试用例呢?这样又可以省掉一次编译的消耗。
云原生,主要围绕对测试执行环境的支持,测试资源的动态扩缩容、以及测试环境的快速准备。甚至还包含了开发同学能够在本地运行测试时,能够快速的拉起一个与 CI 一样的测试环境,进行验证。避免由于本地与 CI 环境的差别造成的测试结果、覆盖率等的不一致。
中台能力,为什么要讲中台能力?因为我们发现,业务团队自己也常会做一些针对自己业务系统的提速或优化工具。这些工具应该能够非常便捷的集成到 CI 平台上,能够复用 CI 平台的任务编排、执行、输入输出、日志、产物等公共能力。更进一步能够与 CI 平台本身所做的优化形成合力,更有效的提升生产效率。
智能化,可以用在用例自动生成、用例推荐上。通过建立业务模型,对它进行训练,从而得到更全面、有效的用例,从而进一步节省我们生成用例的时间。
期望从这四个点发力,使 CI 能够更快、更灵活、更开放、更智能,解放开发同学的生产力!

点个在看少个 bug 👇



