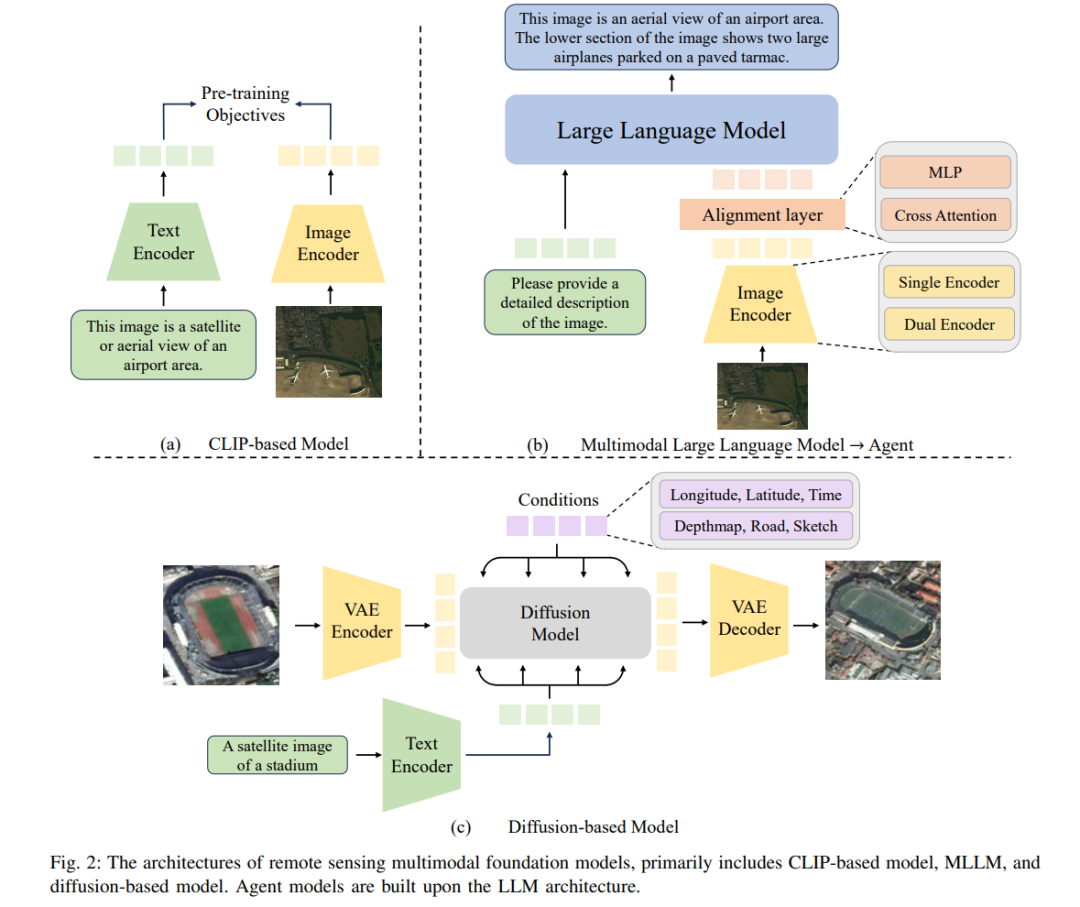
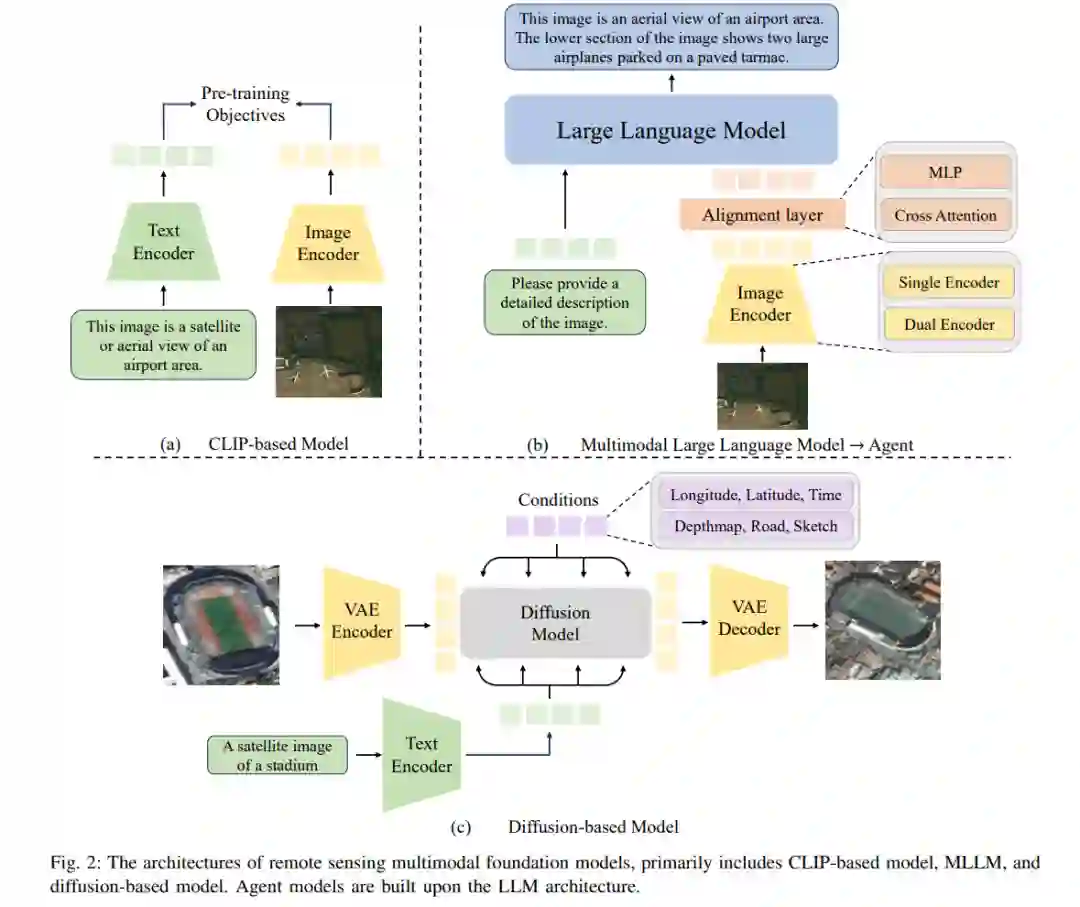
遥感基础模型(尤其是视觉与多模态模型)的快速发展,显著提升了智能地理空间数据解译的能力。这些模型融合了光学、雷达、激光雷达(LiDAR)影像以及文本与地理信息等多模态数据,从而实现对遥感数据更全面的分析与理解。多模态融合技术能够提升目标检测、土地覆盖分类和变化检测等任务的性能,而这些任务往往因遥感数据的复杂性和异质性面临挑战。然而,尽管取得了这些进展,仍存在若干关键问题:数据类型的多样性、大规模标注数据集的必要性,以及多模态融合技术的复杂性,均对模型的实际部署构成显著障碍。此外,训练和微调多模态模型的高计算需求,进一步增加了其在遥感影像解译任务中的应用难度。
本文全面综述了遥感视觉与多模态基础模型的最新进展,重点关注其架构设计、训练方法、数据集和应用场景。我们探讨了这些模型面临的核心挑战,如数据对齐、跨模态迁移学习和可扩展性,同时指出了旨在突破这些限制的新兴研究方向。本文旨在厘清遥感基础模型的当前发展态势,并为未来研究提供启示,以推动这些模型在真实场景中的应用边界。论文整理的资源列表详见:
https://github.com/IRIP-BUAA/A-Review-for-remote-sensing-vision-language-models。
一、引言
近年来,深度学习和人工智能的显著进展已使其成为遥感领域智能解译的核心技术。深度学习广泛应用于地学任务,如场景分类[1]–[5]、目标检测[6]–[10]、变化检测[11]–[13]、土地覆盖分类[14]–[17]及地理定位[18]–[20]。然而,当前多数模型针对特定任务设计,其架构[21]、损失函数[22]和训练策略[23]高度任务专用化,这种强专业性极大限制了模型在相近任务间的泛化能力[24]。此外,这些模型对海量遥感数据的利用不足,导致实际应用中泛化性能欠佳。
基础模型(foundation models)的兴起,依托自监督学习与多模态学习的快速发展,彻底重塑了人工智能技术格局。本文所述基础模型指通过自监督、半监督或多模态学习在广谱数据上预训练、提取通用特征,并能通过微调或提示调优高效适配下游任务的深度学习模型。凭借庞大参量和全量数据,此类模型不仅在自然语言处理领域(如GPT系列、LLaMA等大语言模型)取得革命性突破,还在计算机视觉等领域展现出卓越的泛化能力,推动人工智能应用边界持续扩展。
基础模型最初在自然语言处理(NLP)领域通过GPT[25]–[27]、LLaMA[28]等大语言模型(LLMs)实现普及。这些模型利用千亿级参数和海量文本数据进行多阶段训练,在语言理解、文本生成和机器翻译等任务中达到最优性能,并展现出零样本和小样本学习能力[29]。在视觉任务中,DINOv2[30]等基础模型通过自监督学习在多样化网络规模数据集上训练,实现高效的零样本图像检索;SAM[31]采用半监督训练流程构建了高可靠性的提示驱动分割基础模型。然而,由于视觉任务的复杂多样性,这些模型仍需额外微调或任务专用模块以适应下游需求[32][33]。视觉-语言模型(VLMs)如CLIP[34]和Grounding DINO[35]实现了文本与图像数据的广泛对齐,支持通过文本提示进行零样本推理。多模态大语言模型(MLLMs)如GPT-4V[36]将图像与文本统一为token序列处理,可更灵活应对多样化下游任务。
遥感数据的智能解译面临独特挑战:标注数据稀缺性与任务专业性长期制约深度学习模型性能[19][37]。影像解译作为遥感核心任务,使得视觉与多模态基础模型成为主流研究方向。现有研究通常通过融合遥感解译相关的任务专用数据、结构和训练策略来改造通用模型。视觉基础模型基于传统卷积神经网络(CNNs)和Transformer架构,结合遥感场景特性进行增强,通过设计专用预训练任务和模型架构,更高效提取高分辨率影像的视觉表征[38]。多模态基础模型整合视觉与文本数据,为遥感任务提供新范式:基于CLIP的VLM模型将遥感影像映射至文本描述,实现文本提示驱动的场景分类与检索[37];而采用MLLM架构的多模态模型支持更广泛任务,展现出更强泛化能力。
为系统梳理遥感基础模型研究现状,本文综述最新进展、核心挑战与未来方向。区别于以往聚焦特定任务或阶段的综述,本研究从架构设计、训练方法、数据利用和应用场景四个维度进行全面探讨。主要贡献如下:
全景综述:首次针对遥感基础模型的系统性综述,涵盖视觉与多模态两大方向,梳理其演进路径、技术突破与核心成果;
创新分类体系:提出从模型架构与核心功能双视角出发的新型分类框架,明晰各类方法的关联性与适用边界;
资源集成:建立并维护专项资源库(含论文、评测榜单及开源代码),推动领域协作创新。
模型架构、训练方法与数据集构成深度学习的三大支柱,共同决定模型的泛化能力。基于此,本文采用三维分类体系系统分析遥感基础模型最新进展,为研究者开发更鲁棒的模型提供全面参考。在此框架下,我们详细探讨视觉与多模态模型的主要优化方向及具体策略,并综合现有基础模型的评测方法与结果,完整呈现其优势与局限。全文组织结构如图1所示:第二节讨论模型架构,第三节分析训练方法进展,第四节阐述数据集构建与利用,第五节展示评测基准与结果,第六节总结关键挑战与未来方向。