
原创作者:代居益 指导老师:丁效 转载须标注出处:哈工大SCIR
1. 引言
在随着社交媒体和在线平台深度嵌入日常生活,信息传播的速度与规模达到了前所未有的水平。然而,这一高度互联的传播机制也加剧了虚假信息(misinformation)在多领域的扩散风险。无论是未经证实的谣言、经过篡改的图文或伪装成正规报道的假新闻(如图1所示,虚构“2025 年 7 月将发生史上最大全球极光风暴,NASA 发布红色警报,影响多地区通信并需准备应急物资” ,还搭配伪造含 NASA 标识与 “GLOBAL ALERT” 视觉素材这类典型案例 ),这些误导性内容正持续侵蚀公众的认知信任,干扰舆论环境,甚至威胁社会稳定。

图1:虚假信息样例 作为信息不对称问题在数字时代的集中体现,虚假信息的生成与传播呈现出自动化程度高、隐蔽性强、跨平台传播快等新特征,其技术演化也具备阶段性(如图2所示):从早期机器学习(如朴素贝叶斯、TF - IDF 等),到深度学习(GNN、LSTM、ViT),再往后大语言模型(post - LLM)时代,正朝着深度伪造检测、AIGC 虚假信息识别等方向发展。高效、精准地识别虚假信息,并抑制其链式扩散,已成为自然语言处理、社会计算与人工智能安全等交叉领域的关键研究任务。
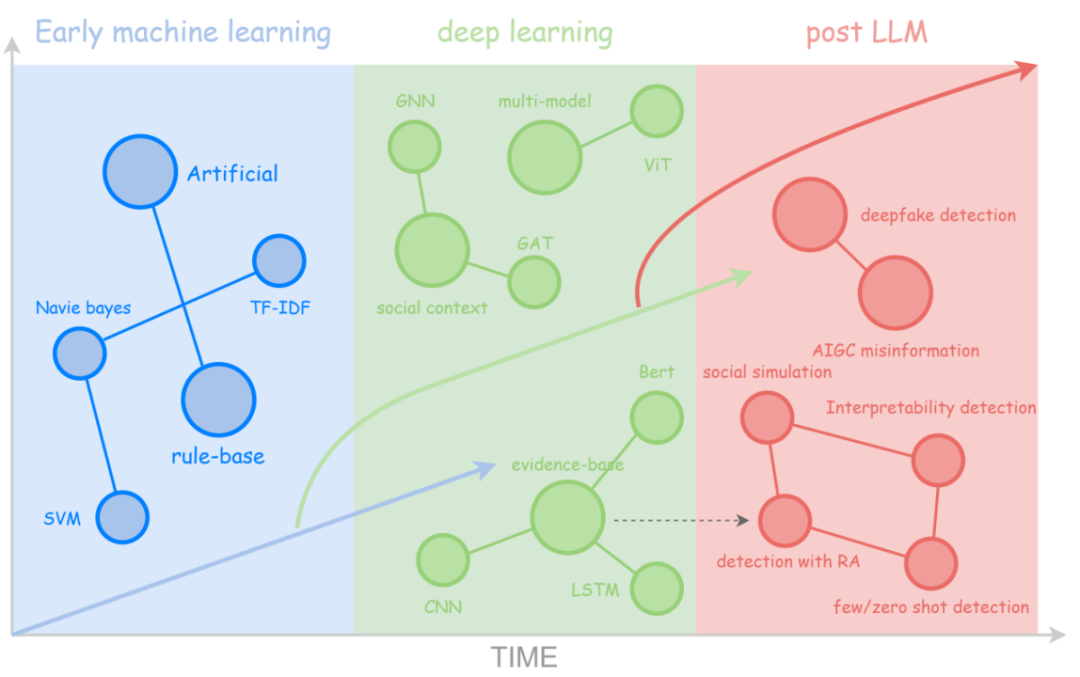
图2 虚假信息检测技术的演化和发展 在此背景下,本文将系统梳理虚假信息检测技术的发展脉络,重点分析方法范式的演化路径、关键技术的融合趋势,以及大模型(LLMs)驱动下的新挑战与应对策略。通过对代表性方法与最新进展的归纳总结,旨在为构建更具智能性、鲁棒性与可解释性的信息可信体系提供理论支撑与实践启示。
2. 虚假信息检测技术的发展脉络
2.1 主流研究范式
在大模型普及之前,虚假信息检测主要围绕三种研究范式展开:基于证据的事实核查(fact-checking)、基于传播语境的谣言检测(rumor-detection)、以及基于意图分析的内容理解(intent-analysis)。这三类方法从不同层面建模虚假信息的语义结构、传播机制与操控意图,构成了该领域的核心技术基础,并在多类任务中形成互补与融合。 第一类是基于证据的事实核查方法,该类方法将检测任务建模为声明(claim)与外部证据之间的关系推理。典型流程包括证据检索、语义匹配与立场判别三个阶段。以 FEVER 数据集(Thorne et al., 2018)为代表,该任务要求系统从维基百科中检索相关证据句,并判断其是否支持、反驳或与主张无关。在模型层面,DeClarE 模型(Popat et al., 2018)检索相关文档作证据,用深层神经网络融合信息与证据特征,实现可解释的虚假信息检测。 第二类是基于传播语境的谣言检测方法,关注信息在社交平台上的传播路径与用户互动特征。该类方法通常将谣言建模为传播图结构或时间序列,并利用图神经网络(GNN)或 RNN 等技术对传播动态进行建模。例如,Ma 等(2018)的树结构递归神经网络(RVNN)通过建模推文转发关系树,捕捉虚假信息传播层级依赖;Shu 等(2019a)的 dEFEND 模型利用注意力机制挖掘用户评论反驳线索,增强检测可解释性;Yang 等(2023b)的 WSDMS 模型结合社交对话与新闻句子上下文关联,实现句子级和篇章级虚假信息联合检测。 第三类是基于意图分析的内容理解方法,聚焦于语言风格、话语策略与操控目标的识别,强调对信息传播背后动机的建模。这类方法常结合情绪识别、极性分析、语用推理等技术,试图识别信息中的误导性表达或操控意图。例如,某些研究利用模型分析文本是否存在煽动性、讽刺性或虚假陈述倾向。近年来,基于BERT、RoBERTa 等预训练语言模型的自然语言推理(NLI)方法被广泛应用于此类任务。如 Kaliyar 等(2021)的 FakeBERT 通过微调 BERT,在社交媒体虚假信息检测中效果显著。
2.2 核心检测技术
虚假信息检测技术方法可归纳为以下三大方向:融合多模态信息的内容检测、大语言模型辅助推理与生成以及跨领域与少样本适应机制。
2.2.1 融合多模态信息的内容检测
多模态检测方法通过整合文本、图像、视频等不同模态的信息,提升虚假信息识别的鲁棒性与泛化能力。Wang 等(2018)提出的 EANN 框架采用对抗训练机制,去除事件特定特征,使模型更专注于图文间的通用欺骗性模式,在多个图文混合虚假新闻数据集上获得良好泛化表现。Qi 等(2021)进一步构建实体增强的多模态检测框架,提取图像与文本中具显著语义意义的实体线索,并进行跨模态实体对齐,从而提升对图文一致性的判别能力。
2.2.2 大语言模型辅助推理与生成
尽管大语言模型直接用于真假判别的性能不稳定,但其在事实推理、风格分析与常识补全等方面表现出良好的辅助能力。Hu 等(2024)提出的自适应推理引导网络框架,通过让小语言模型(SLM)选择性吸收 LLM 提供的解释性线索,在中英文数据集上显著优于独立模型与简单集成方法。 另一方面,LLM 也被用于生成多样化合成数据以增强模型鲁棒性。如 MiniCheck(Tang et al., 2024)利用 GPT-4 生成具备复杂推理链条的虚假文本,训练出轻量高效的核查模型,其性能接近 GPT-4 而训练成本降低 400 倍。DELL 框架(Wan et al., 2024)则结合 LLM 生成用户评论与代理解释任务(如情感、立场分析),构建用户-内容交互图网络,融合多源线索提升检测精度。 2.2.3 跨领域与少样本适应机制 虚假信息往往随突发事件快速演化,导致训练数据与实际检测场景存在严重分布偏移,传统监督学习难以泛化。元学习(Meta-Learning)和对比学习(Contrastive Learning)成为近年解决跨领域检测难题的关键技术路径。MetaAdapt(Yue et al., 2023)通过任务相似性加权机制,自适应调整源领域知识迁移比例,在 COVID-19 场景下仅需少量标注样本即可超越常规模型。ACLR(Yue et al., 2022)进一步引入对抗式对比正则项,强化跨域语义结构的一致性,从而提升检测稳定性。 3. 大模型驱动下的新挑战与应对策略
3.1 语言生成伪造:AIGC驱动的高保真虚假内容
3.1.1 AIGC生成内容的高度拟真性与伪装性****
大型语言模型(LLMs)的广泛应用,使生成式人工智能(AIGC)成为虚假信息的新型生成源。与传统依赖人工编辑或模板拼接的伪造方式不同,AIGC 可生成结构完备、语义连贯、语言自然的文本,其风格与表达逻辑高度接近真实报道,显著增强了虚假内容的迷惑性与传播力(见图3)。

图3 大模型生成的虚假信息 AIGC 虚假信息既可能源于模型“幻觉”导致的事实错误,也可能由恶意用户通过精心设计的提示词(prompt)有意生成误导内容。尤其是在可控生成能力不断增强的背景下,攻击者可通过改写、释义或风格迁移等方式,对虚假文本进行语义保持下的多轮包装,使其语气更中性、逻辑更自然,从而规避语言风格过滤。实证研究表明,风格伪装后的虚假文本可显著降低主流检测模型的识别性能,准确率下降幅度高达 38%。 此外,AIGC生成内容呈现出跨领域、高多样性、多类型错误等特征,覆盖医疗、政治、金融等敏感语境,常伴随虚构事实、伪造引用与因果链断裂等复杂误导策略。这种“高保真伪装”正逐步超越传统检测系统的能力边界,迫切需要引入更强的语义建模与推理机制,提升对深层虚假结构的识别能力。 3.1.2 SheepDog:面向AIGC的风格不变检测机制
为此,Wu等(2024)提出 SheepDog 模型,其设计一套针对风格不可知性(style-agnostic)的检测机制,旨在提升虚假信息识别在AI进行文本风格重写情境下的鲁棒性与解释能力。如图4所示,SheepDog 整体流程由两大模块构成:
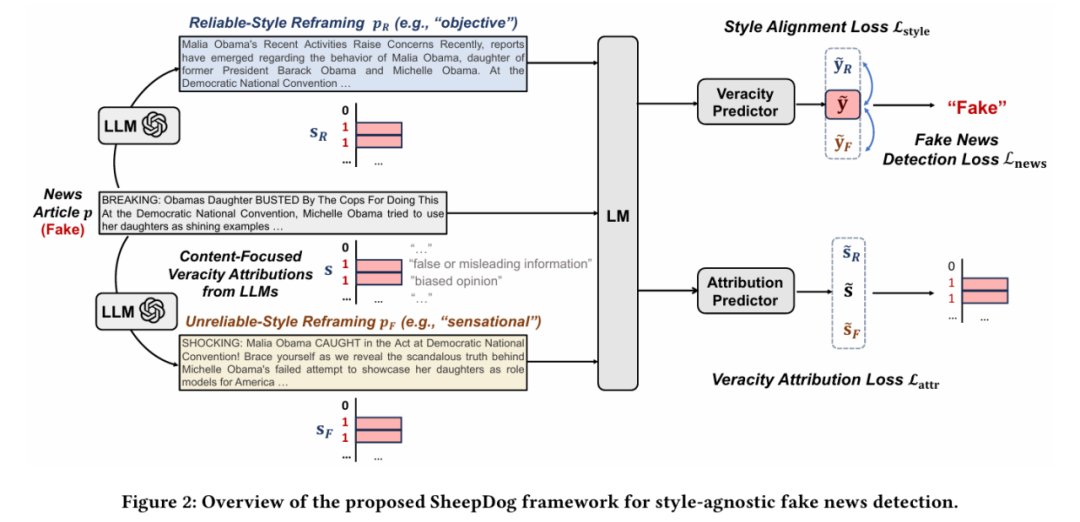
图4 SheepDog 的整体架构 首先,模型使用大型语言模型(LLM)将原始新闻样本(如伪造新闻)生成多种风格重写版本,包括客观风格(objective)和煽动风格(sensational)。这些样本在语义不变的前提下,呈现出语气、措辞、结构等方面的显著差异,从而构建一个风格扰动训练集。 接着,主模型接受这组文本作为输入,并通过两个训练目标进行优化: * 风格一致性损失:要求模型对不同风格的文本输出相同的真实性预测,从而避免因文风而判断失误; * 新闻检测损失:以常规方式训练真假标签,用于监督主检测器。
在此基础上,SheepDog 还引入了第二个子模块——内容归因预测器。它利用LLM自动标注输入文本中可能存在误导性的信息片段(如虚构事件、夸大描述、缺乏来源的数字等),并生成内容导向归因标签,作为弱监督信号引导模型关注关键虚假信息位置。该模块的损失项为内容归因一致性损失,用于提升模型的可解释性与可控性。 实验结果表明(见图5),SheepDog 在多个人工生成和真实世界风格重写数据集上均表现出显著优势。在面对风格改写攻击时,主流检测器准确率下降超30%,而 SheepDog 仍能保持稳定的识别能力。这表明模型确实掌握了“与风格无关的虚假性信号”,在风格对抗检测任务中具有良好鲁棒性。
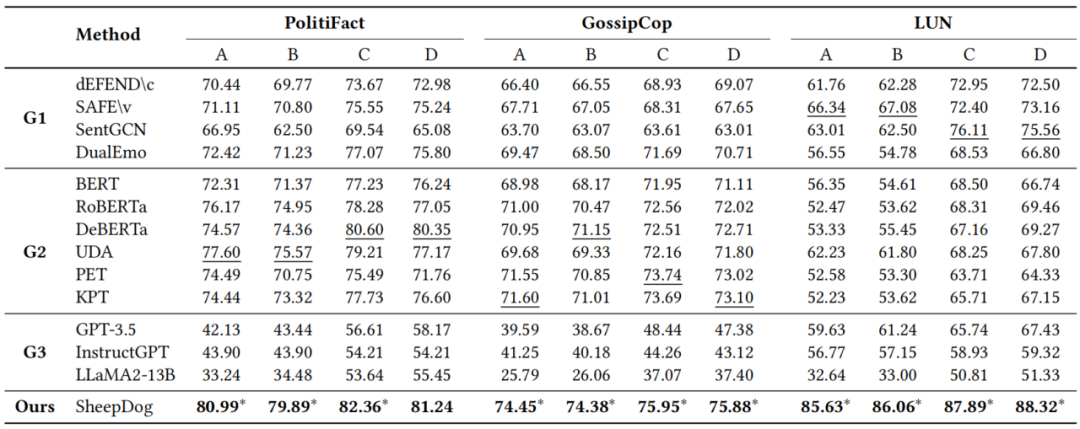
图5 SheepDog 实验结果 总而言之,SheepDog 以风格不可知训练、内容归因监督和多风格生成扰动为核心,实现了从“文本分类器”向“对抗式语言推理器”的演进,是当前应对 AIGC 虚假信息检测的重要技术代表之一。 3.2 多模态伪造:DeepFake带来的复合型挑战
随着多模态生成技术的突破,DeepFake 不再仅是图像或视频的简单伪造,而是演变为融合语言、视觉、音频等模态的复合式虚假内容。其核心特征是通过图文协同生成,在感知与语义层面同时构建高度一致的伪造信息,进一步模糊“真实”与“虚构”的边界,挑战现有检测机制的模态覆盖能力与语境理解能力。**
**
3.2.1 跨模态一致性伪造的迷惑性增强****
近年生成对抗网络(GAN)与扩散模型在图像、视频、语音等领域的快速发展,使 DeepFake 内容实现了从单一模态向多模态融合的跃迁。当前伪造内容往往通过图像+文本+音频的联合方式构建语义一致的传播材料,表现出极高的感知真实度与叙事连贯性。例如,一个合成视频可能结合真实音轨、虚构画面与新闻文本,使内容在视觉、听觉与语言三方面相互印证,从而构成所谓的“伪多模态一致性”。更具挑战的是,这些内容大多以短视频、配图推文、图文混排等形式在社交平台上广泛传播,链路分裂、扩散迅速,难以进行内容溯源与平台干预。同时,DeepFake 技术还可进行细粒度编辑,如局部表情修改、背景替换、唇形同步等,足以绕过传统的帧间一致性或像素差检测。现有基于图像取证、语音匹配或单模态分类的检测方法,面对这类深度语义协调的伪造内容时,往往表现出鲁棒性下降与误判风险。因此,DeepFake 内容的“跨模态伪装性”正成为当前虚假信息检测中最具挑战的前沿问题之一,迫切需要构建更强的多模态对齐机制与语义级一致性验证框架。 3.2.2 FakeShield:融合推理与解释的多模态检测框架****
为应对高保真、多模态、语义伪装等复杂伪造内容,FakeShield 提出了一种集检测、定位与解释于一体的多模态大模型驱动框架。如图6所示,FakeShield的核心由三个子系统组成,分别对应“判别”“解释”“定位”三个阶段:
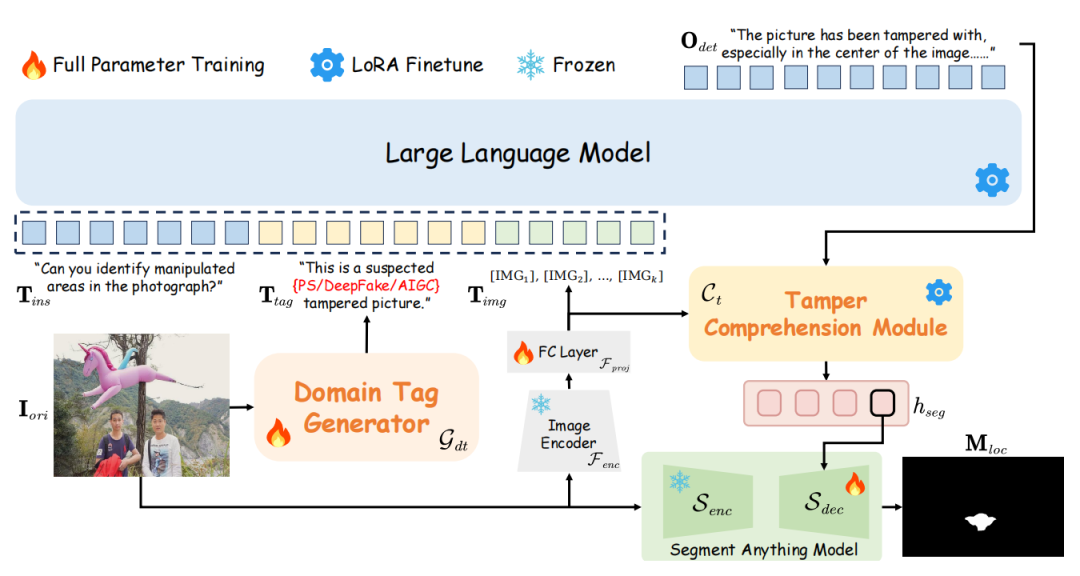
图6 FakeShield的工作流程 1.领域识别模块:输入图像后,系统首先利用视觉语言模型识别其所属语境(如政治、医疗、金融等),作为后续检测任务的上下文条件; 2.解释生成模块:结合图像与提问(如“这张图是伪造的吗?”),FakeShield 能生成自然语言形式的解释性答案,并指出潜在伪造区域(如“人物肤色不自然”“文本与背景不符”); 3.伪造定位模块:进一步调用图像分割与标注网络,基于模型输出的可疑描述,在图像中高精度定位伪造区域,实现“语言—视觉”的双重可解释输出。 与传统“黑箱式”图像分类不同,FakeShield 引入了语言理解和视觉区域标注两个冗余判别路径,使得用户不仅知道“图是伪造的”,更能理解“为什么是伪造的、哪里被伪造了”。实验如图7显示,该方法在多个 DeepFake 类型任务(如人脸融合、纹理篡改、场景替换)上均表现出优异的准确性与可解释性,且在跨域泛化能力上显著优于仅依赖视觉特征的模型。
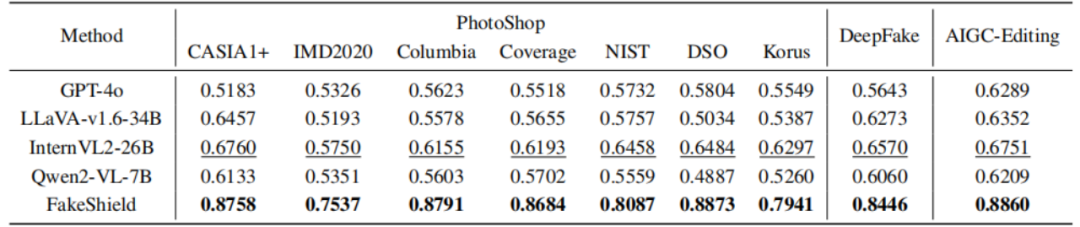
图7 FakeShield 实验结果 FakeShield 的提出不仅在技术上弥合了图文语义推理与区域检测之间的断层,也为未来多模态安全研究提供了可参考的统一范式。随着LLM与VLM的协同进化,该类方法有望成为大模型时代虚假内容检测的重要支柱。 4. 总结与展望
虚假信息的生成与传播已成为数字社会的重要风险来源,随着大型语言模型(LLMs)与生成式人工智能(AIGC)的快速发展,这一问题呈现出自动化、规模化和高度隐蔽化的趋势。本文系统回顾了虚假信息检测技术的发展脉络,从早期的内容分析、证据对齐与社交语境建模三大范式,到当前依托预训练模型与多模态融合的深层语义建模方法,并重点分析了 AIGC 与 DeepFake 所引发的新型挑战。这些进展表明,虚假信息检测正在从基于表层特征的识别任务,转型为融合语言理解、知识推理与传播建模的复杂系统工程。
展望未来,虚假信息检测研究亟需在技术、系统与治理三个维度持续深化:在技术层面,需提升模型的跨模态语义推理能力与风格对抗鲁棒性;在系统层面,应构建集检测、溯源与响应为一体的闭环机制,实现对虚假信息的全链路控制;在治理层面,则需推动平台、用户与算法之间的协同共治,构建可信、透明的信息传播生态。只有多方协作、系统应对,方能在大模型时代有效遏制信息操控风险,守护公共认知安全。 5. 参考文献
[1] Thorne J, Vlachos A, Christodoulopoulos C, et al. FEVER: a large-scale dataset for fact extraction and VERification[J]. arXiv preprint arXiv:1803.05355, 2018. [2] Wang S, Kong Q, Wang Y, et al. Enhancing rumor detection in social media using dynamic propagation structures[C]//2019 IEEE International Conference on intelligence and security informatics (ISI). IEEE, 2019: 41-46. [3] Pan L, Wu X, Lu X, et al. Fact-checking complex claims with program-guided reasoning[J]. arXiv preprint arXiv:2305.12744, 2023. [4] Tang L, Laban P, Durrett G. Minicheck: Efficient fact-checking of llms on grounding documents[J]. arXiv preprint arXiv:2404.10774, 2024. [5] Sheng Q, Cao J, Zhang X, et al. Zoom out and observe: News environment perception for fake news detection[J]. arXiv preprint arXiv:2203.10885, 2022. [6] Wan H, Feng S, Tan Z, et al. Dell: Generating reactions and explanations for llm-based misinformation detection[J]. arXiv preprint arXiv:2402.10426, 2024. [7] Yue Z, Zeng H, Zhang Y, et al. MetaAdapt: Domain adaptive few-shot misinformation detection via meta learning[J]. arXiv preprint arXiv:2305.12692, 2023. [8] Hu B, Sheng Q, Cao J, et al. Bad actor, good advisor: Exploring the role of large language models in fake news detection[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2024, 38(20): 22105-22113. [9] Chen C, Shu K. Can llm-generated misinformation be detected?[J]. arXiv preprint arXiv:2309.13788, 2023. [10] Kondamudi M R, Sahoo S R, Chouhan L, et al. A comprehensive survey of fake news in social networks: Attributes, features, and detection approaches[J]. Journal of King Saud University-Computer and Information Sciences, 2023, 35(6): 101571. [11] Chen C, Shu K. Combating misinformation in the age of llms: Opportunities and challenges[J]. AI Magazine, 2024, 45(3): 354-368. [12] Vladika J, Matthes F. Scientific fact-checking: A survey of resources and approaches[J]. arXiv preprint arXiv:2305.16859, 2023. [13] Shahi G K, Struß J M, Mandl T. Overview of the CLEF-2021 CheckThat! Lab: Task 3 on Fake News Detection[C]//CLEF (Working Notes). 2021: 406-423. [14] Wu J, Guo J, Hooi B. Fake News in Sheep's Clothing: Robust Fake News Detection Against LLM-Empowered Style Attacks[C]//Proceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining. 2024: 3367-3378. [15] Xu Z, Zhang X, Li R, et al. Fakeshield: Explainable image forgery detection and localization via multi-modal large language models[J]. arXiv preprint arXiv:2410.02761, 2024. [16] Hinami R, Satoh S. Discriminative learning of open-vocabulary object retrieval and localization by negative phrase augmentation[J]. arXiv preprint arXiv:1711.09509, 2017. [17] Vo N, Lee K. Hierarchical multi-head attentive network for evidence-aware fake news detection[J]. arXiv preprint arXiv:2102.02680, 2021. [18] Wang Y, Ma F, Jin Z, et al. Eann: Event adversarial neural networks for multi-modal fake news detection[C]//Proceedings of the 24th acm sigkdd international conference on knowledge discovery & data mining. 2018: 849-857. [19] Qi P, Cao J, Li X, et al. Improving fake news detection by using an entity-enhanced framework to fuse diverse multimodal clues[C]//Proceedings of the 29th ACM International Conference on Multimedia. 2021: 1212-1220. [20] Shu K, Cui L, Wang S, et al. defend: Explainable fake news detection[C]//Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining. 2019: 395-405. [21] Xu W, Wu J, Liu Q, et al. Evidence-aware fake news detection with graph neural networks[C]//Proceedings of the ACM web conference 2022. 2022: 2501-2510.
、