

多年来,信息提取一直引领着从文本中进行事件检测的方向。大语言模型(LLM)和视觉语言模型(VLM)等神经模型的最新进展实现了多种模式的整合,提供了更丰富的事件信息来源。与此同时,模式图和三维重建方法的发展也增强了对复杂事件进行可视化和注释的能力。在这些创新的基础上,本文推出了 MUMOSA(MUlti-MOdal Situation Awareness)交互式仪表盘,将这些不同的资源整合在一起。MUMOSA 旨在为事件态势感知提供一个综合平台,为用户理解和分析各种模式的复杂场景提供一个强大的工具。
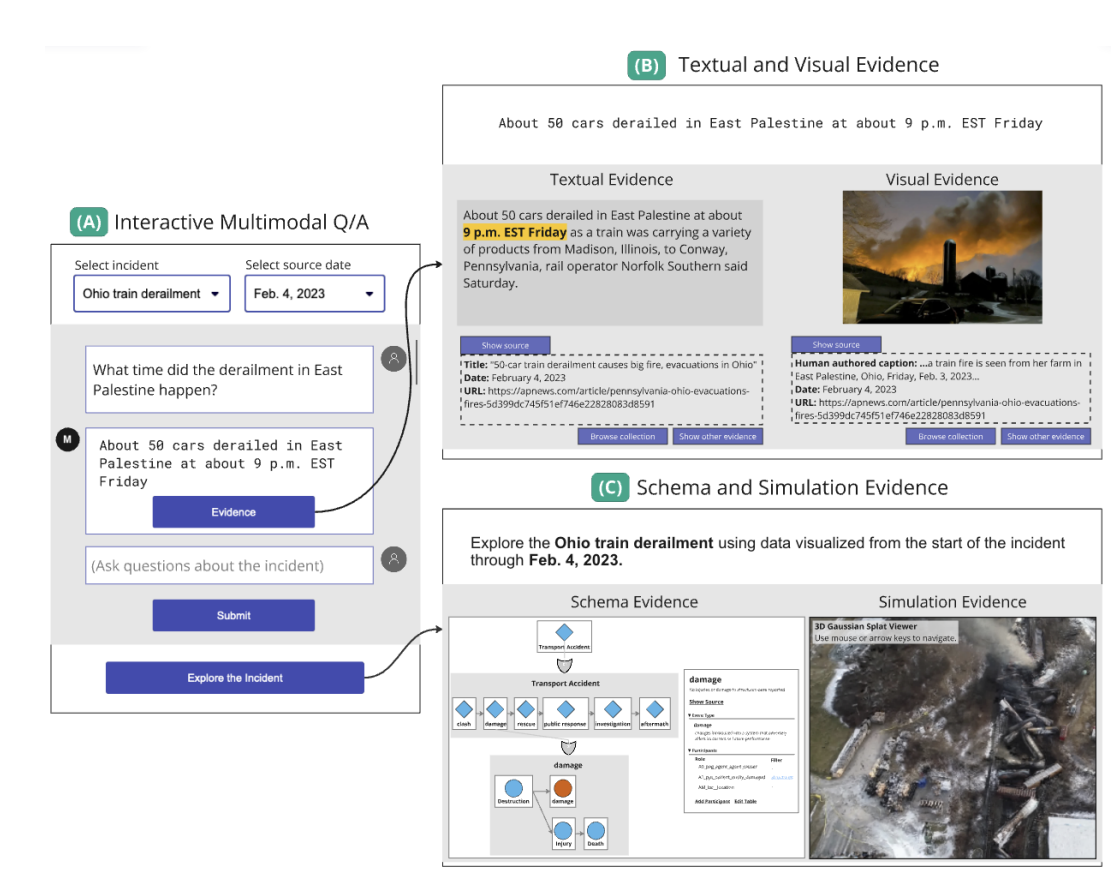
图 1:用户通过 (A) 交互式多模态Q/A 参与 MUMOSA 面板,选择带有源日期的事件,并以自然语言输入问题或直接请求。然后,他们可以选择通过 (B) 文本和可视化证据面板检查系统响应的源数据,或继续通过 Q/A 参与仪表板。也可以通过 (C) 模式和模拟证据中的面板,对所选事件的整个事件进行探索。
在重大事件或危机发生后,调查人员如何确定和评估何时发生了什么,以便编写一份报告,从事件发生的顺序中提供明确证据,详细说明吸取的经验教训?社区如何让应对人员做好准备,以应对未来可能出现的类似复杂、危急的情况?有些危机应对程序是针对特定情况制定的,例如对野火的初步灭火应对,因此应对人员可以事先接受持续培训,调查人员也知道事后应该注意什么。但在其他情况下,危机来得太突然、太出乎意料,既定的通信线路难以传递最新信息。在这些意外情况发生后,调查人员和救灾人员这两个群体都需要了解危机后报告所收集和分析的证据中有关事件的各类信息。
自 20 世纪 80 年代末以来,计算语言学中的信息提取(IE)领域一直引领着将符号方法、统计方法以及最近的神经方法应用于自然语言文本,以识别此类报告所需的基本信息要素类型,包括实体、关系和事件(Grishman,2019 年)。最近,神经模型(如 LLM 和 VLM)可以将多种模式结合起来,提供有关事件的更多信息来源,因此现在有机会利用各种多模式事件信息组合,支持调查人员梳理文本和图片证据以撰写报告,并培训应对人员为将来处理此类信息做好准备。此外,最近还开发了可访问超过 3K 种事件类型的模式图(Zhan 等人,2023 年),以及从仅有的 24 幅图像中进行情景模拟的三维重建方法(如 Kerbl 等人,2023 年),用户现在可以亲手访问界面,对复杂事件进行在线可视化和注释,同时从现有的证据和文件中了解这些事件发生的过程。
本文将介绍如何将这些不同的资源汇集到一个用于理解复杂事件的交互式 MUlti-MOdal Situation Awareness(MUMOSA)仪表板中,最终为用户在危机期间的实时事件态势感知(SA)和决策提供支持。对于特定的角色,如现场第一响应人员或紧急行动中心的事件协调员,其 SA 的具体内容将由其工作任务和决策决定。但在任何情况下,他们的 SA 都需要 “在一定的时间和空间范围内感知环境中的各种因素,理解其含义并预测其在不久的将来的状态”(Endsley, 1995, 2015)。
MUMOSA 仪表板的面板旨在以多模式证据的形式,让用户感知所选复杂事件的基本信息要素(SA 1 级)。工作流程设计使用户能够探索和比较各证据面板的信息,以及编辑和注释复杂模式图和情景模拟的内容。这样做的目的是支持用户解释和保留包含多种信息要素的面板内容,并建立自己对复杂事件的叙述(第 2 层)。
用户参与互动式多模式问答(Q/A),探索事件和模拟环境。用户为感兴趣的复杂事件和时间框架初始化仪表板。在输入问题后,他们会收到一个文本答案,并可从文本文件和图片视觉效果中获取支持证据。同时,他们还可以通过模式图结构和三维模拟探索整个事件。如图 1 所示,与事件相关的每一种证据模式都显示在一个单独的交互式面板中。

