基础模型(Foundation Models)是一类新兴的大规模机器学习模型,可以适用于各种任务。这些模型依赖于大规模数据训练,因此,高质量的数据集对于基础模型的准确性、鲁棒性和训练效率至关重要。然而,策划这些数据集的方法通常是临时的,基于启发式的,并且需要大量的人工努力。在本论文中,我们提出了一些系统性的方法来理解和改进用于训练基础模型的数据。作为一个核心主题,我们从分布变化的角度探讨了从广泛的预训练数据到任务特定的适应数据的泛化问题。
首先,我们分析了视觉和语言领域的各种基础模型预训练设置,包括对比预训练、多任务学习、掩码语言建模和自回归语言建模,并展示了在每种设置中,预训练可以证明提高准确性、增强鲁棒性,并使模型在下游任务中具有上下文学习的能力。在我们的分析中,我们广泛展示了在预训练期间,模型学习了预训练数据和适应数据共享的潜在结构。利用这一潜在结构有助于模型在适应下游任务时克服分布变化。
其次,我们介绍了基于分布变化技术的系统性算法,以解决优化训练基础模型的数据分布的两种主要设置:有目标适应分布和无目标适应分布。当给定目标分布时,我们开发了一种基于重要性重采样的高效大规模数据选择方法,该方法在简化的特征空间上选择一个子集以匹配目标分布。当目标未知时,如在训练多用途模型时,我们开发了一种通过分布鲁棒优化来优化跨数据源混合比例的方法,其目标是对未知目标具有鲁棒性。重要的是,我们展示了用小型代理模型优化的数据混合可以更有效地训练大型模型(在流行数据集上对于8B模型训练效率提高了2.6倍)。应用于训练语言基础模型,我们的算法在下游任务中的准确性和训练效率优于手动调整和启发式方法。
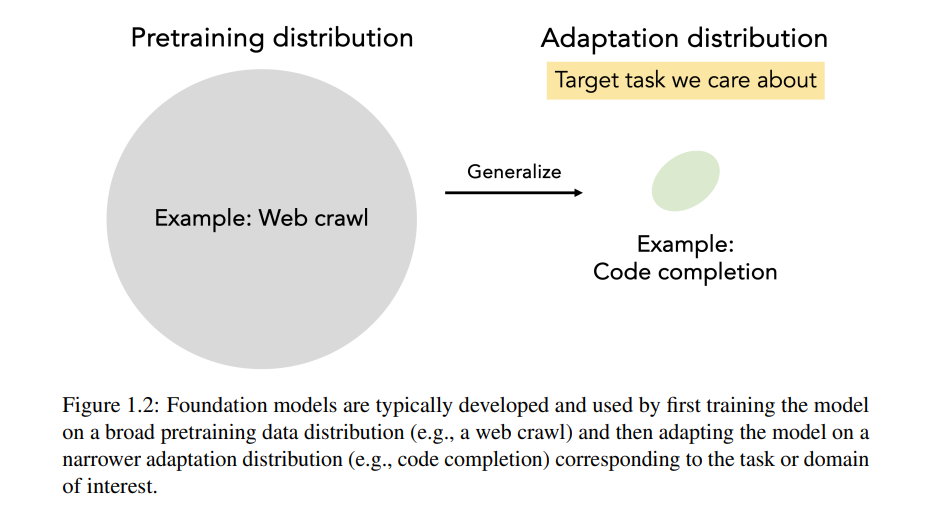
大规模数据训练的机器学习模型在语言和视觉领域的最新技术中取得了成功 [Devlin et al., 2019, Brown et al., 2020, Chen et al., 2020b, Radford et al., 2021, Touvron et al., 2023, Krizhevsky et al., 2012, Gadre et al., 2023, LeCun et al., 1998, Radford et al., 2019]。这一类模型被称为基础模型(Foundation Models),它们首先在广泛的预训练数据集上进行训练,然后可以适应各种下游任务 [Bommasani et al., 2021]。
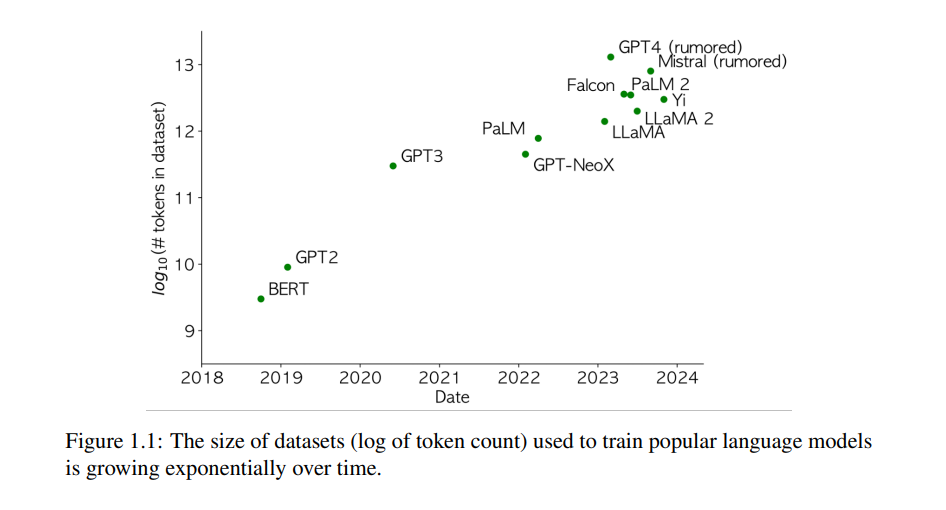
基础模型成功的一个主要因素是用于预训练的大规模、多样化的数据。图1.1显示了用于训练流行的大型语言模型(LMs)的数据集规模随着时间的推移呈指数级增长,追踪了这些模型能力的进步。高质量、多样化和大规模的数据对于基础模型的准确性、鲁棒性和训练效率至关重要 [Xie et al., 2023b,a, Du et al., 2021, Chowdhery et al., 2022, Touvron et al., 2023, Brown et al., 2020, Gadre et al., 2023, Schuhmann et al., 2022, Radford et al., 2021],并且在深度学习中也是如此 [LeCun et al., 1998, Deng et al., 2009, Russakovsky et al., 2015, Schmidt et al., 2018]。
然而,由于许多因素,数据在最终模型能力和属性中的作用尚不完全清楚。数据集非常大、嘈杂(从互联网上抓取)且高维(文本或图像空间)。数据对最终模型的影响由中间的训练步骤以及模型架构和超参数选择的归纳偏差介导。最重要的是,预训练和适应数据之间在任务、目标函数和输入数据分布等方面存在许多差异,因此不清楚为什么预训练在适应后能改善下游任务的性能。相应地,策划大规模数据集的方法通常依赖于人工努力、直觉或临时启发式方法 [Brown et al., 2020, Du et al., 2021, Chowdhery et al., 2022, Touvron et al., 2023, Deng et al., 2009, Schuhmann et al., 2022, Gadre et al., 2023]。
例如,GPT-3 [Brown et al., 2020] 和 PaLM [Chowdhery et al., 2022] 等语言模型通过过滤类似于维基百科的数据作为高质量文本的代理。特定领域的语言模型如 Codex [Chen et al., 2021a] 通常通过定制方法手动策划相关数据 [Gururangan et al., 2020]。在视觉领域,LAION-5B 数据集 [Schuhmann et al., 2022] 通过使用现有的 CLIP 模型 [Radford et al., 2021] 对数据进行评分,以及其他启发式过滤方法策划而成。
我们的目标是 1) 提高对预训练基础模型如何改善下游性能的理解,并 2) 在改进预训练数据方面的系统性、大规模算法上取得实际进展。为了使我们的初步分析更易处理,我们抽象掉模型架构和训练算法的角色,专注于预训练数据分布对基础模型的影响。
我们的核心见解是从分布变化的角度,通过严格的统计方法解决预训练和适应数据分布之间的泛化问题。首先,我们分析了预训练如何自然地克服分布变化并转移到下游任务。在预训练期间,模型学习了预训练数据分布中的潜在结构,这与下游任务共享。推断这种潜在结构的能力转移到更好的下游准确性。其次,我们开发了减少预训练和适应之间分布变化的算法,采用了来自鲁棒机器学习的技术,包括重要性加权和分布鲁棒优化,并证明它们提高了训练效率和下游准确性。