

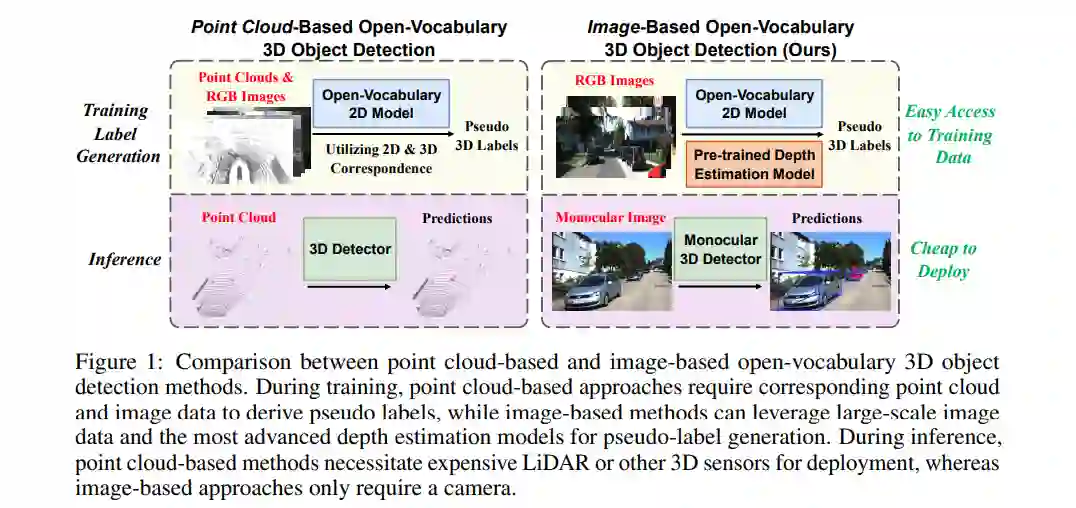
开放词汇3D物体检测最近因其在自动驾驶和机器人领域的广泛应用而受到广泛关注,旨在有效识别之前未见过的新类别。然而,现有的基于点云的开放词汇3D检测模型受限于高昂的部署成本。在本研究中,我们提出了一种新颖的开放词汇单目3D物体检测框架,称为OVM3D-Det,该框架仅使用RGB图像训练检测器,使其在成本效益和可扩展性方面具有优势,并能够利用公开数据。与传统方法不同,OVM3D-Det不需要高精度的LiDAR或3D传感器数据作为输入,也不需要用于生成3D边界框。相反,它采用开放词汇的2D模型和伪LiDAR自动标注RGB图像中的3D物体,促进了开放词汇单目3D检测器的学习。然而,直接使用伪LiDAR生成的标签训练3D模型是不够的,因为从噪声点云中估计的边界框往往不精确,且严重遮挡的物体会进一步影响效果。为了解决这些问题,我们提出了两项创新设计:自适应伪LiDAR侵蚀和基于大语言模型的先验知识进行的边界框精细调整。这些技术有效地校准了3D标签,并使得仅用RGB图像进行3D检测器训练成为可能。大量实验表明,OVM3D-Det在室内和室外场景中均优于基线方法。代码将公开发布。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
Arxiv
153+阅读 · 2023年3月29日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
Arxiv
153+阅读 · 2023年3月29日