导读 本次分享题目为腾讯大数据实时湖仓智能优化实践。将围绕下面四点展开:
- 湖仓架构
- 智能优化服务
- 场景化能力
- 总结和展望 分享嘉宾|陈梁 腾讯 高级工程师 编辑整理|李笑宇 内容校对|李瑶 出品社区|DataFun
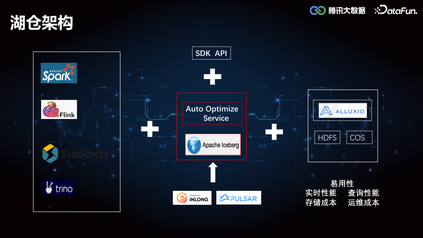
01****湖仓架构腾讯大数据的湖仓架构如下图所示:
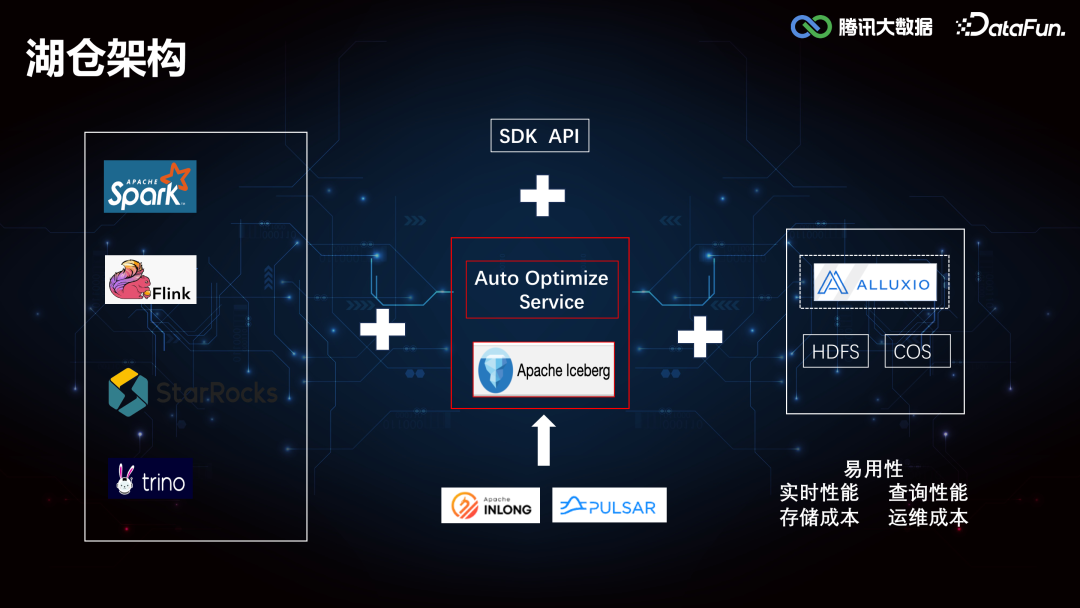
这里分为三个部分,分别是数据湖计算、数据湖管理和数据湖存储。数据湖计算部分,Spark 作为 ETL Batch 任务的主要批处理引擎,Flink 作为准实时计算的流处理引擎,StarRocks 和 Presto 作为即席查询的 OLAP 引擎。数据湖管理层以 Iceberg 为核心,同时开放了一些简单的 API,支持用户通过 SDK 的方式去调用。在 Iceberg 之上构建了一套 Auto Optimize Service 服务,帮助用户在使用 Iceberg 的过程中实现查询性能的提升和存储成本的降低。数据湖底层存储基于 HDFS 和 COS,COS 是腾讯云的云对象存储,可以满足云上用户的大规模结构化/非结构化存储需求,在上层计算框架和底层存储系统之间,也会引入 Alluxio 构建了一个统一的存储 Cache 层,进行数据缓存提速。本次分享的重点主要是围绕智能优化服务(Auto Optimize Service)展开。02****
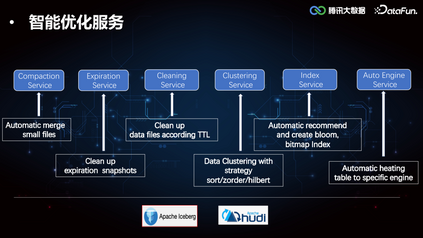
智能优化服务********
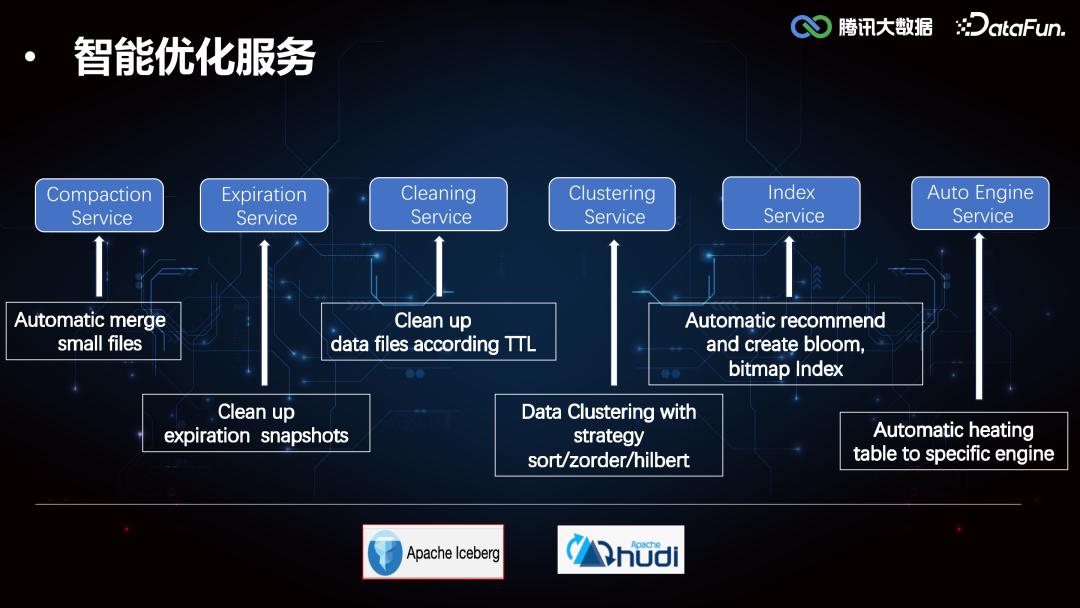
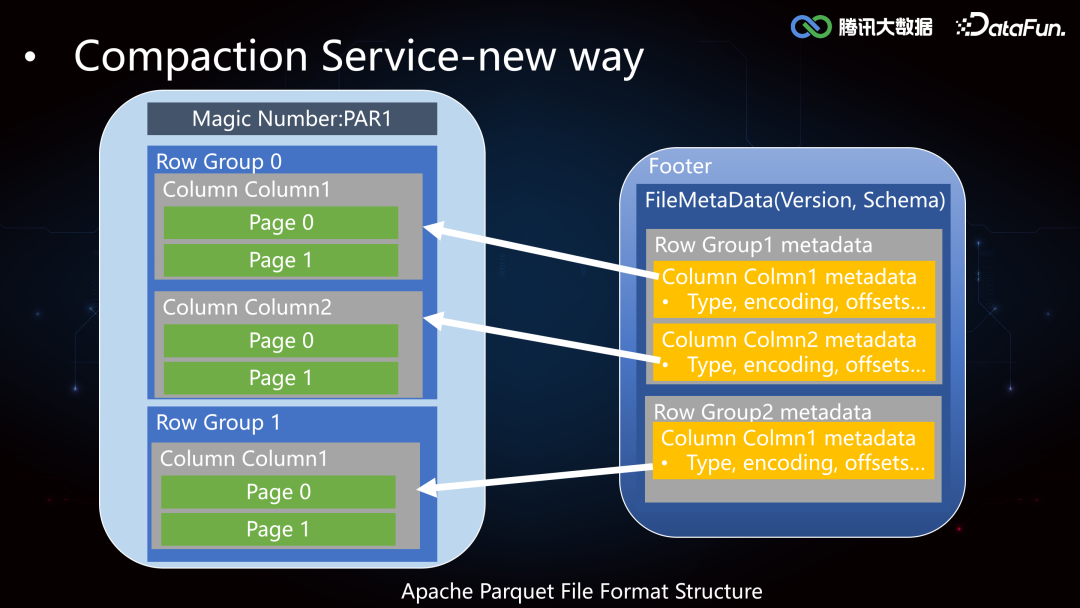
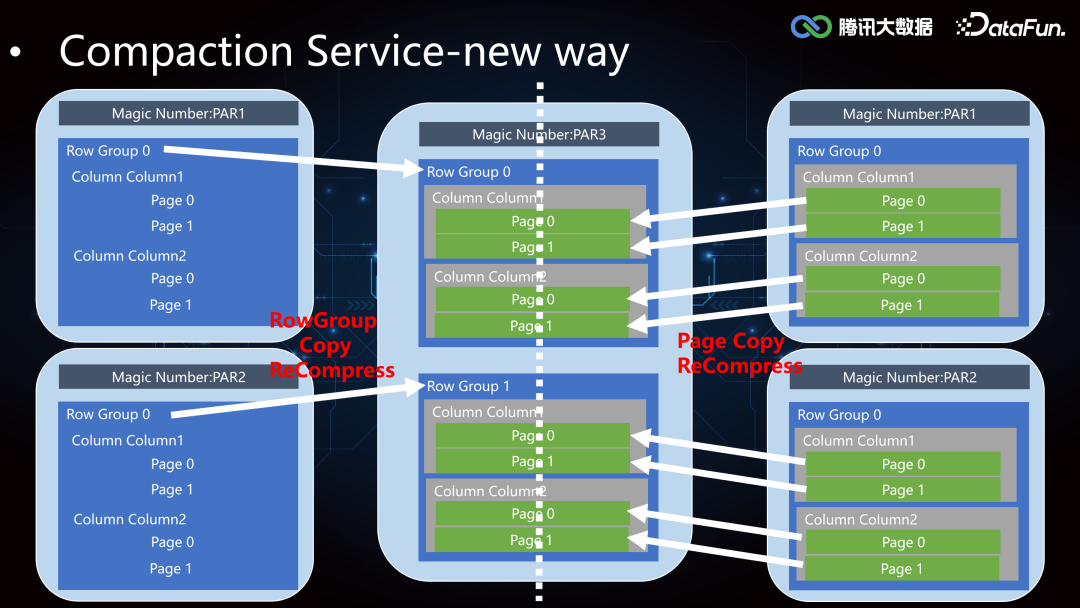


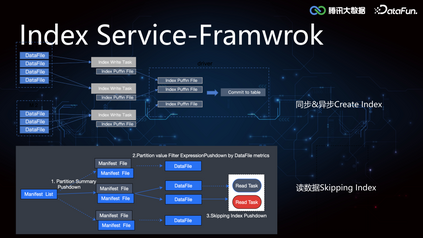
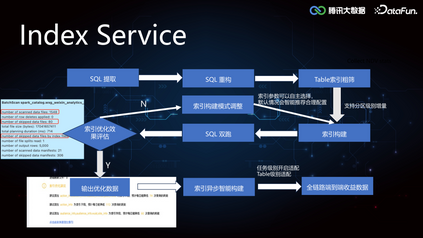
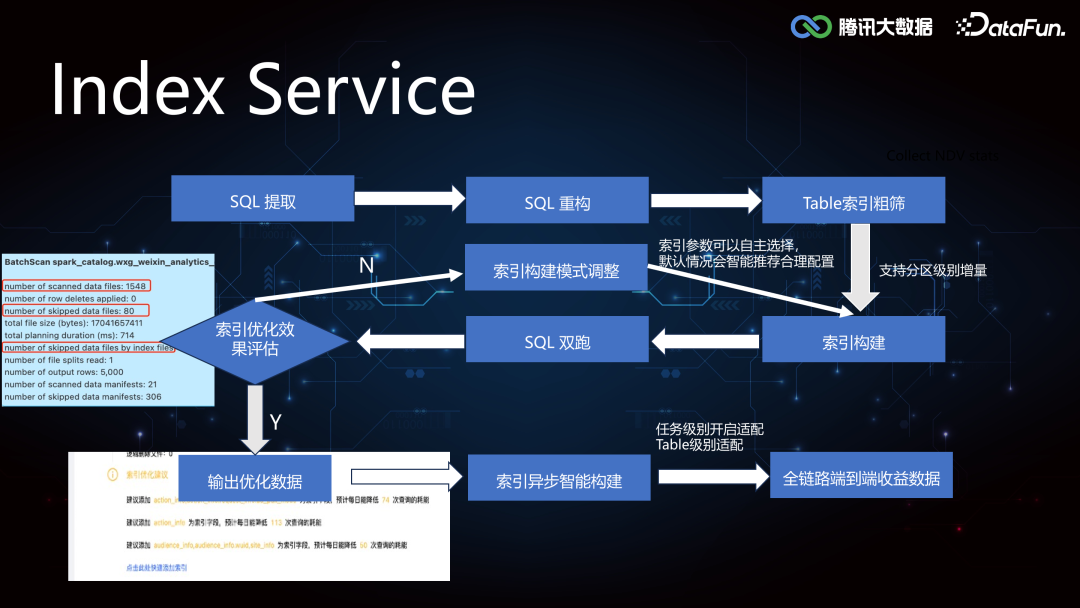
2. Index Service****(1)Iceberg Core FrameworkIceberg 较 Hive 增加了 min-max 索引,记录了 DataFile 所有 column 列的最大值和最小值,在执行引擎计算时可以协助做文件级别的过滤,但是文件级别的索引粒度较粗,在随机写数据的时候 min-max 存在交叉,导致索引失效。所以我们在这个基础之上进一步拓展了二级索引,来提高 Data Skipping 的能力,加速查询。索引的构建和加载过程在 Iceberg Core 层的框架支持实现如下: 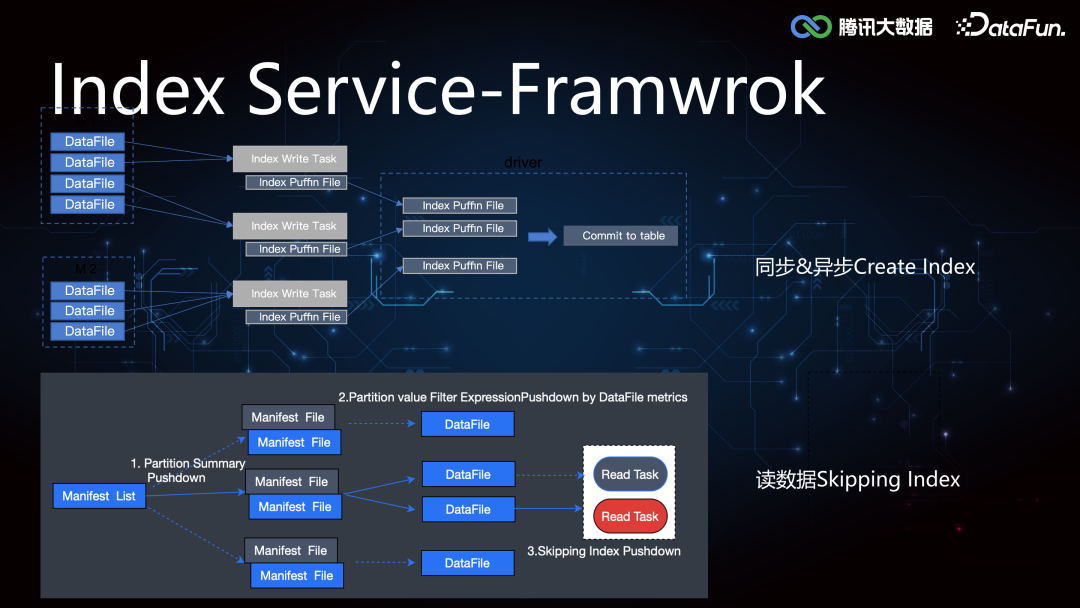

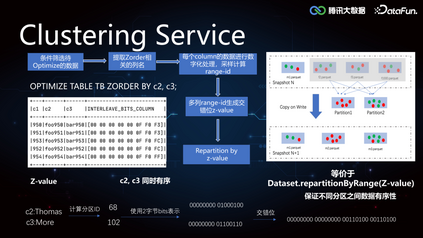
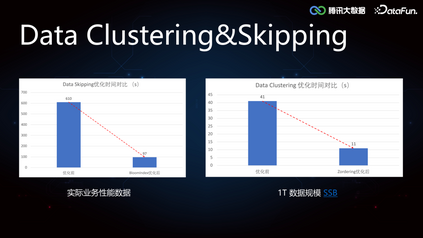
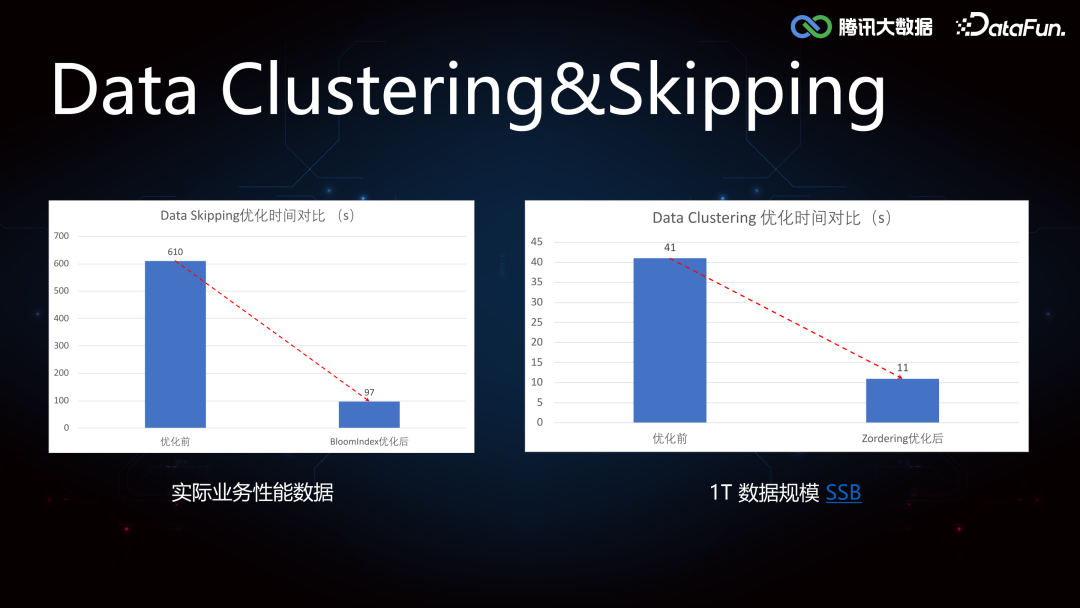
3. Clustering Service****由于 Iceberg 的 min-max 索引在随机写的情况下是普遍失效的,导致 Data Skipping 能力较差,所以如果需要精确覆盖 min-max,可以将数据进行重排分布。当用户进行单列查询的时候,提前对数据列排序写入,如果是多列查询的情况,由于无法保证多个列都分布在一个文件中,我们使用 Z-order,对每个列进行数字化处理,采样计算 Range-ID,生成交错位Z-Value,根据 Z-Value 进行重分区,可以保证不同列之间的相对有序性。 
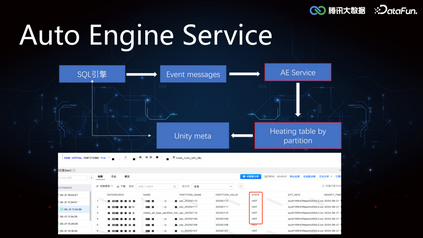
4. AutoEngine Service****相对于 OLAP 引擎来讲,Iceberg 表,Hudi 表都是外表,这些外表基本都是 TB 级别,使用 StarRocks,Doris 查询外表并不能发挥 OLAP 的查询优势。AutoEngine Service 通过收集 OLAP 引擎的 Event Message,对相应的分区进行加热,也就是将相关分区数据路由到 StarRocks 集群,上层引擎可以在 StarRocks 集群中发现该分区的元数据,由此实现基于存储计算引擎的选择优化。 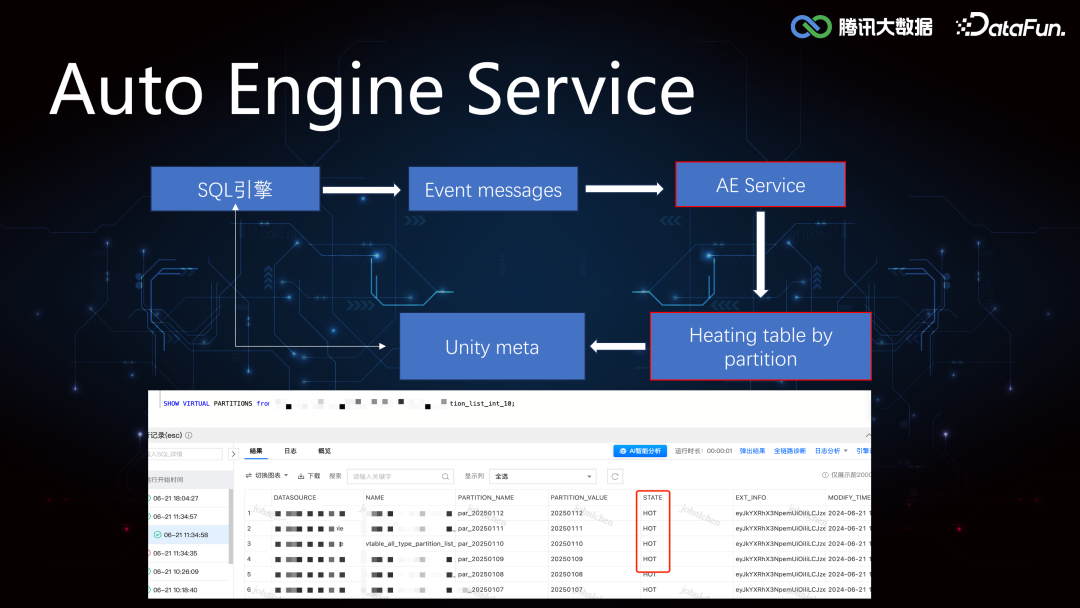
场景化能力****
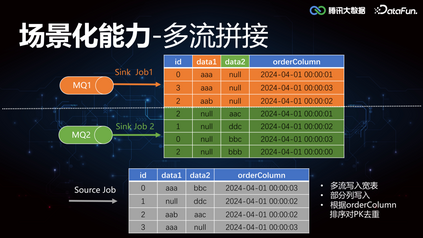
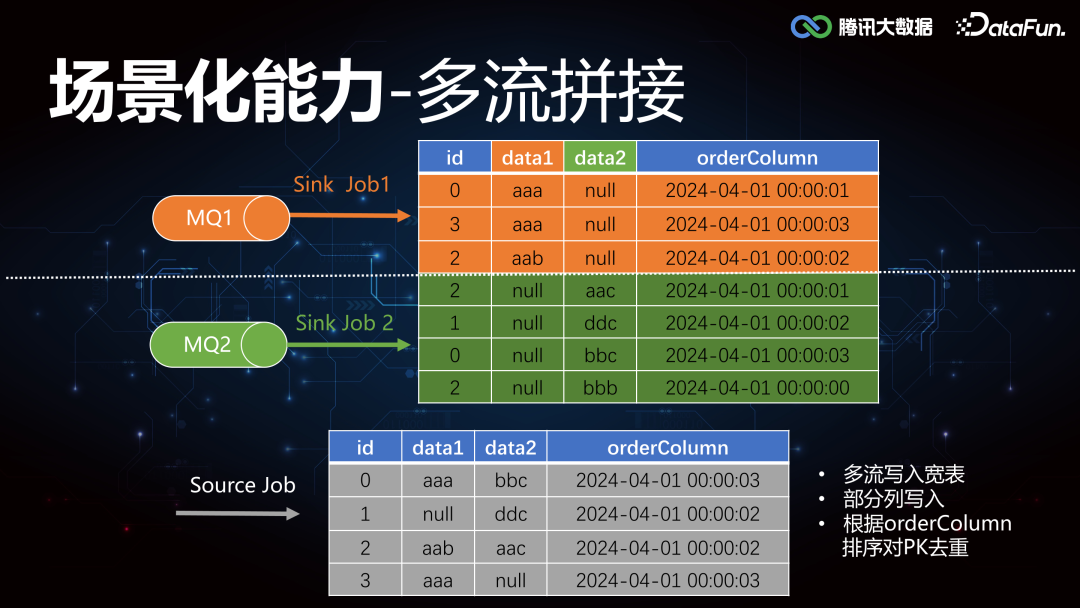
1. 多流拼接关于多流拼接,这里举个例子简单说明, 如图所示,有两个 MQ 同时往下游写数据,MQ1 更新列 data1,MQ2 更新列 data2,最终根据 id 聚合,取时间戳 orderColumn 排序最靠前的一条,作为 join 之后的 source。要实现这个合并更新能力,往往需要外接各种临时存储 Redis/Hbase/MQ 等组件。****

2. 主键表****通过多流 Join 的实现方法依赖 Compaction Service 的调度性能,当数据规模不断增加,多流 join 聚合计算更新的拼接方式可能存在性能瓶颈,所以我们也引入主键表作为行级更新的另一种实现方式。比如这里我们根据 id 分成四个桶,存在多个任务往一个桶去写数据,一个桶内的数据是有序的,那么下游在读取桶数据的时候会更轻松。但是当 id 的基数很大的时候,比如当 id 为 4/8/16 的时候,都会往一个桶内写数,会产生 DataFile 的重叠,在下游从桶内读数的时候,就需要合并一个桶内的多个 DataFile 到一个 Reader 处理。如果分桶数量设置的不合适,单点压力就会过大,此时可以使用 Rescale 实现桶的弹性扩缩容。另外在桶的基础上扩展列族 Column Family 的概念,相当于每个列都作为独立的文件写入,多个 Column Family 行拼接 Full Outer Join 即可。

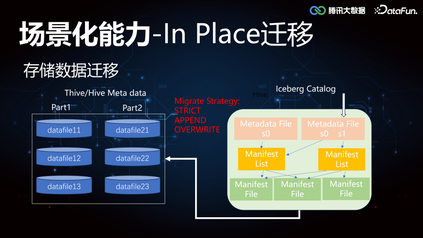
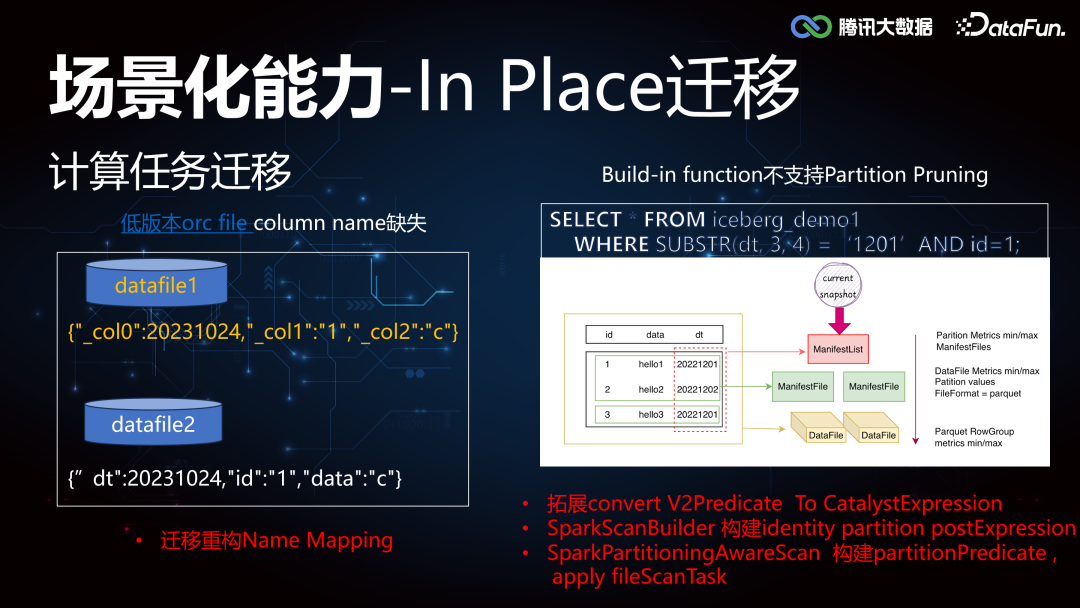
3. In Place 迁移****由于对数据湖的高阶特性能力的需要,很多业务做了架构的升级,同时也面临着存量 Thive(腾讯自研 Hive)和 Hive 的数据迁移到 Iceberg。这里需要重点支持的工作包括:存储数据的迁移,计算任务的迁移。 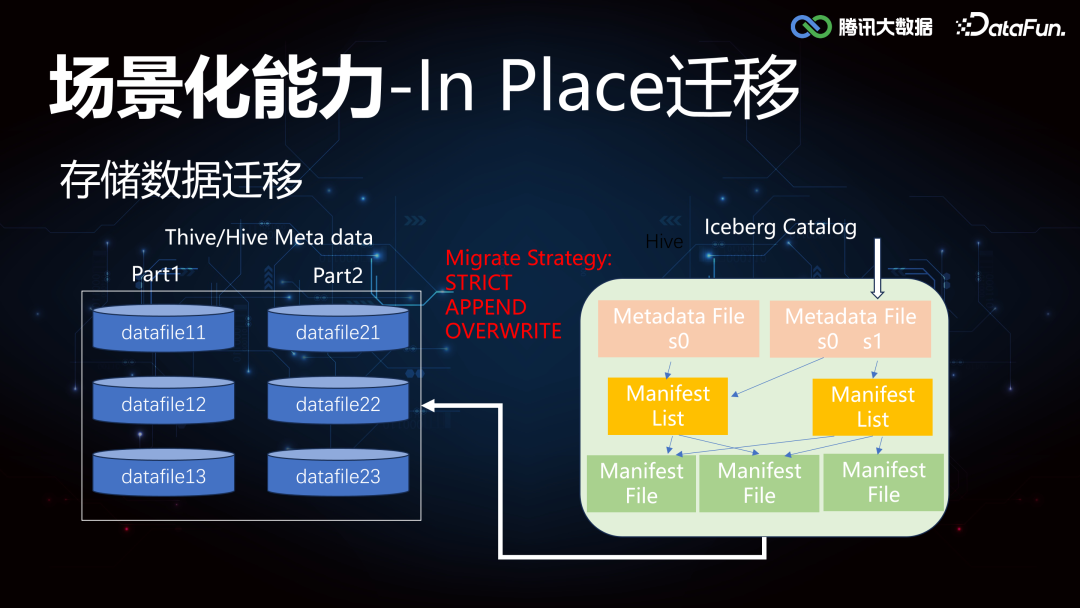
4. PyIcebergIceberg Table Spec 是开发性的实现,可以支持多种语言 API 接入,AI生态圈数据科学等主要以 Python 环境为主,要求高性能 Native 解码,对 JVM 环境无强依赖,PySpark 虽然具备接入 Iceberg 的能力,但是太重了。我们可以直接利用 PyIceberg 能力,无JVM 依赖,加载解码一次即可,提供广泛的机器学习类库的优势,拓展 Python的技术栈到 Iceberg 元数据层面,构造 Pandas,Tensorflow,Pytorch 等不同的 DataFrame,方便进行数据分析和 AI 模型训练的编程探索,我们内部也深度支持了 PyIceberg SQL 的列裁剪和谓词下推能力,结合 DuckDB 做一些小数据集的算法快速调试。 
总结和展望****未来还将从以下方面着手,进行实时湖仓的优化:

1. Auto Optimize Service****
冷热分离降本提效 * 物化视图提速 * AE 服务智能化感知 * Compaction 能力打磨 * 更多 Transform UDF Partition Pruning 优化
2. 主键表优化拓展 Deletion Vector,解决谓词下推必须联合去重的性能问题 3. AI 探索
落地适合模型训练的湖仓格式。 * 探索实现分布式 dataFrame,整合 metadata 和引擎。 以上就是本次分享的内容,谢谢大家。

分享嘉宾
INTRODUCTION

陈梁
腾讯
高级工程师
腾讯高级工程师,主要负责腾讯实时湖仓的架构设计和内核优化等工作,推动湖仓一体化在公司大范围内落地并取得显著的性能提升和降本收益。