

该研究独特地识别并表征了当今多模态领域中四种流行的多模态模型架构模式。通过对模型进行架构类型的系统分类,有助于监测多模态领域的发展。与近期提供多模态架构一般信息的综述论文不同,本研究对架构细节进行了全面探索,并识别出四种特定的架构类型。这些类型根据各自将多模态输入整合到深度神经网络模型中的方法进行区分。前两种类型(类型A和B)在模型的内部层中深度融合多模态输入,而后两种类型(类型C和D)则在输入阶段进行早期融合。类型A采用标准的交叉注意力机制,而类型B在内部层中使用自定义设计的模态融合层。另一方面,类型C使用模态特定的编码器,而类型D则利用分词器在模型的输入阶段处理模态。这些识别出的架构类型有助于监测任意多对多的多模态模型发展。值得注意的是,类型C和类型D目前在构建任意多对多的多模态模型中备受青睐。类型C以其非分词的多模态模型架构而著称,正在成为类型D(使用输入分词技术)的可行替代方案。为了辅助模型选择,本研究根据数据和计算需求、架构复杂性、可扩展性、增加模态的简化、训练目标以及任意多对多多模态生成能力,重点介绍了每种架构类型的优缺点。 https://www.zhuanzhi.ai/paper/73467d84ba8b0938df117c12672d6054
近年来,机器学习的多模态领域取得了显著进展。能够处理图像、音频或视频与文本(语言)相结合的模型的大量涌现显著扩展了该领域 (Alayrac et al. [2022], Lu et al. [2023], Mizrahi et al. [2024], Wu et al. [2023a], Yang et al. [2024], Tang et al. [2023a])。尤其是在各种视觉语言任务中,图像与文本模态的整合取得了显著进展,主要归功于Transformer模型 (Vaswani et al. [2017])。Transformer模型 (Vaswani et al. [2017]) 作为一种开创性的深度神经网络(NN)架构,引领了跨领域学习的统一框架。该单一模型在理解和处理来自不同领域的数据方面表现出色。2017年,Transformer模型在自然语言处理(NLP)领域的引入标志着基于Transformer的模型架构的开端。随后,视觉Transformer (ViT) (Dosovitskiy et al. [2021]) 和CLIP (Radford et al. [2021]) 在视觉领域的引入展示了Transformer在处理图像相关任务中的多功能性。这一展示突显了Transformer从不同领域学习的能力,促使了一系列旨在构建能够联合处理图像和文本数据的模型的计划,这些模型利用了强大的Transformer模型架构。基于Transformer的多模态模型Flamingo (Alayrac et al. [2022]) 结合了图像和文本数据作为输入,在视觉语言任务上表现优异。这些结果促使了多模态领域的进一步发展,并鼓励了更多模态的整合 (Awadalla et al. [2023], Li et al. [2023a], Gong et al. [2023], Laurençon et al. [2024a], Ma et al. [2023])。
**在处理混合模态的众多研究工作中,采用了多种方法,包括增强大型语言模型(LLMs)以创建多模态架构 **(Alayrac et al. [2022], Gong et al. [2023], Zhang et al. [2023a], Gao et al. [2023], Wang et al. [2023a], Ye et al. [2023a], Chen et al. [2023a], Tian et al. [2024], Lin et al. [2024]),训练具有不同输入模态的编码器-解码器风格Transformer (Mizrahi et al. [2024], Lu et al. [2022a], Lu et al. [2023]),以及探索替代方法(见第2节)。大量研究使得有效监测模型架构的进展和识别新兴的下一代多模态模型设计趋势变得具有挑战性。我们审视了当前最先进的多模态模型的现状,并根据将输入融合到深度神经网络中的方法,识别了不同的多模态模型架构。主要将现有的多模态架构分为四大类,即类型A、B、C和D。在类型A和类型B架构中,通过在模型内部层中整合输入模态实现深度融合,而在类型C和类型D架构中,模态的早期融合发生在模型的输入阶段。这四种类型的详细内容在第3节中讨论。我们的贡献总结如下:
-
据我们所知,这是首个明确识别四大架构类型(类型A、B、C和D)的研究。图2展示了多模态模型架构的分类法。我们将最先进的模型与这些类型相关联,并概述了它们的优缺点,从而简化了对多模态模型架构的理解、可视化和选择。
-
此外,我们的工作还强调了构建任意模态多模态模型的主要架构类型,这在其他综述论文中无法找到,如 Zhang et al. [2024a], Yin et al. [2024], Caffagni et al. [2024], Wang et al. [2023b], Wu et al. [2023b], Guo et al. [2023]。
-
为了便于模型选择,本研究根据训练数据和计算需求、架构复杂性、可扩展性、整合模态的简便性以及任意模态能力等因素,重点介绍了每种架构类型的优缺点。

多模态模型架构:分类法
通过各种方法将多模态输入融合到深度神经网络中,产生了一系列的架构配置。本文分析了具有混合模态的模型架构,并根据模态融合将其分为四种不同的类型。我们可以识别出两个主要类别:深度融合,其中模态的融合发生在模型的内部层次;以及早期融合,其特点是模态在模型输入时就进行融合。
在每个类别中,我们观察到两个主要的集群。在深度融合领域,模态与内部层次的融合表现为:类型A使用标准的交叉注意力层,类型B则利用定制设计的层。相反,在早期融合领域,多模态输入主要有两种形式:非标记化的多模态输入作为类型C,以及离散标记化的多模态输入作为类型D。这些输入直接提供给变换器模型的输入端进行早期融合,可以是仅解码器或编码器-解码器样式。因此,我们在当前多模态模型的范畴内定义了四种不同类型的多模态模型架构:类型A 3.1,类型B 3.2,类型C 3.3和类型D 3.4。
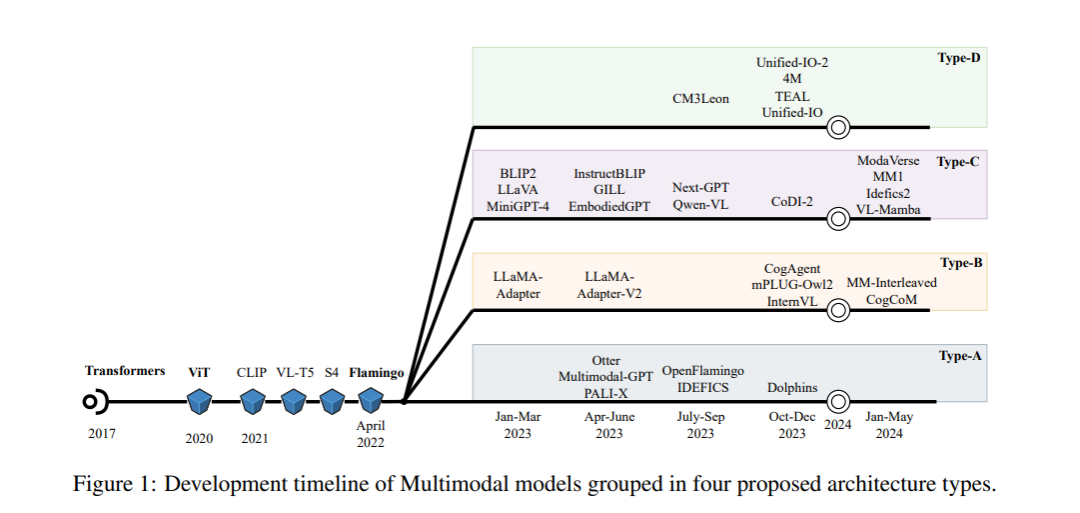
第3节全面概述了每种架构类型,包括其训练数据和计算需求。图2将多模态模型架构类型与相应的SOTA多模态模型结合在一起。图1描述了多模态模型发展的时间线。四种类型,即类型A、类型B、类型C和类型D,分别在第3.1、3.2、3.3和3.4节中描述。每种多模态模型架构类型的优缺点在第4节中列出。
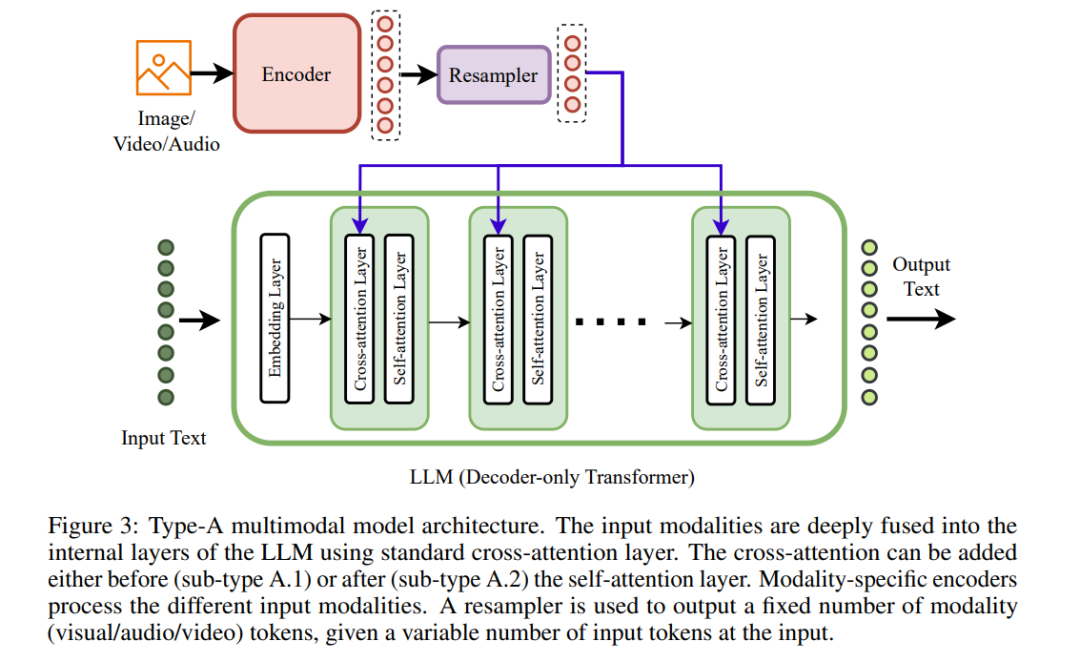
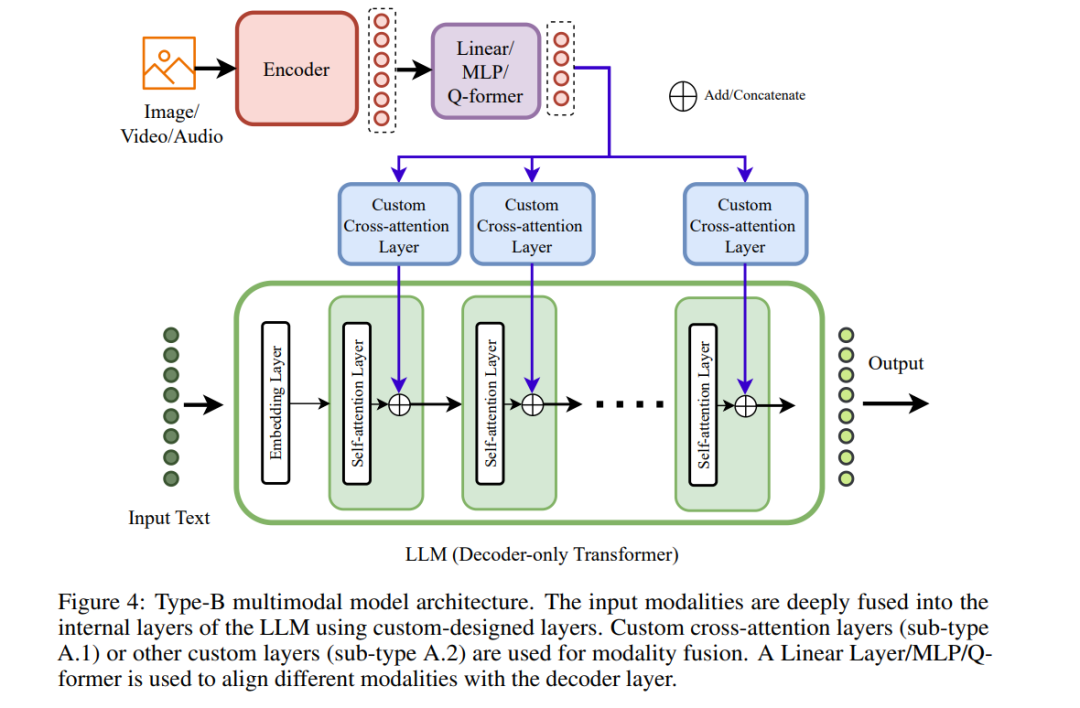
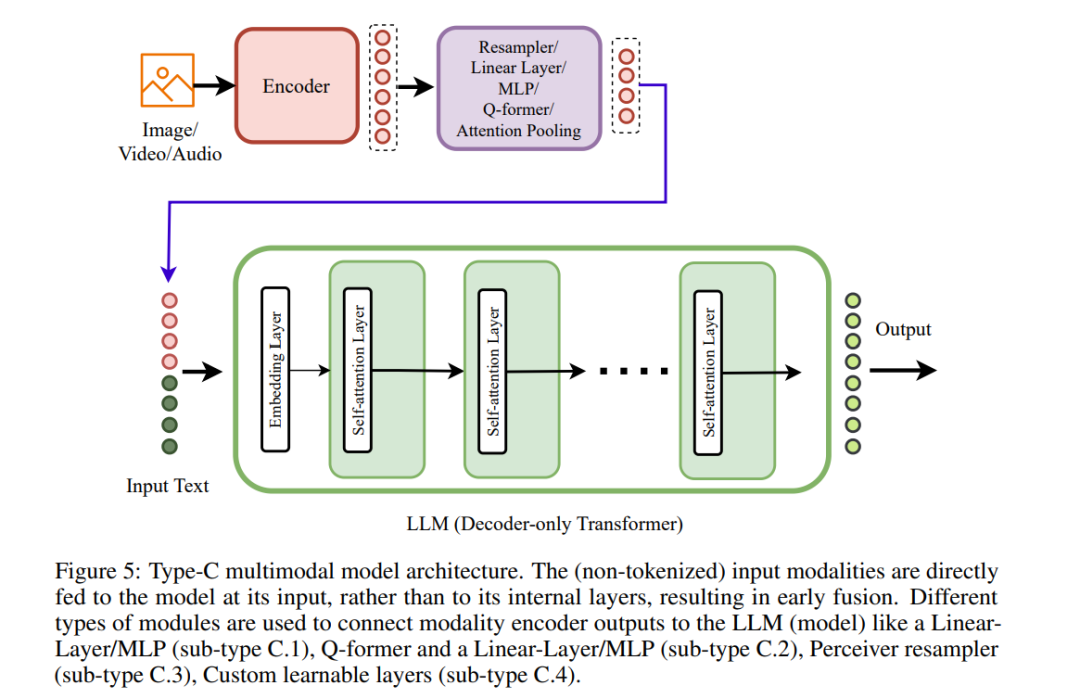
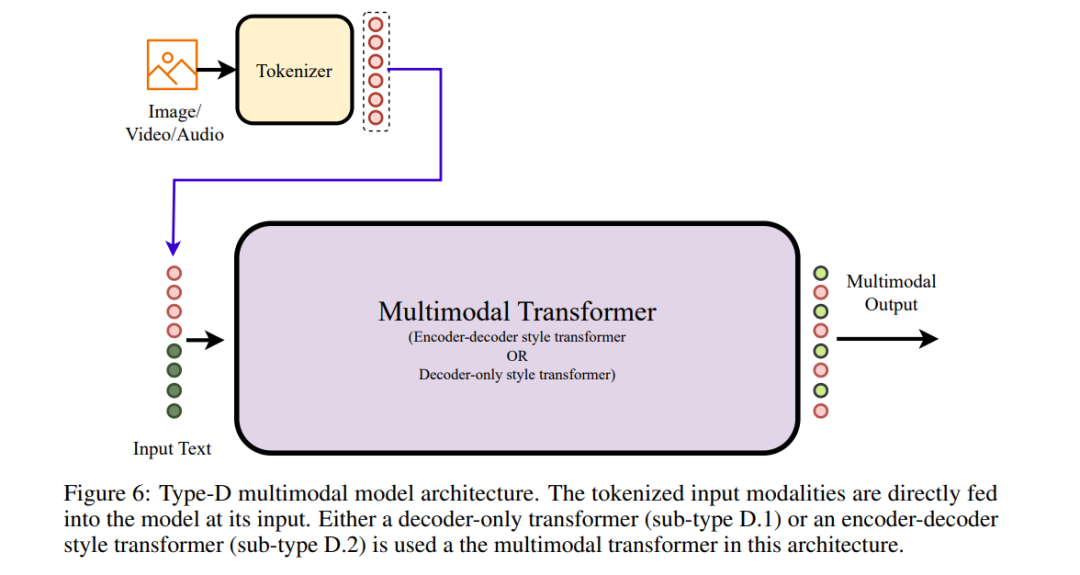
下一代多模态架构
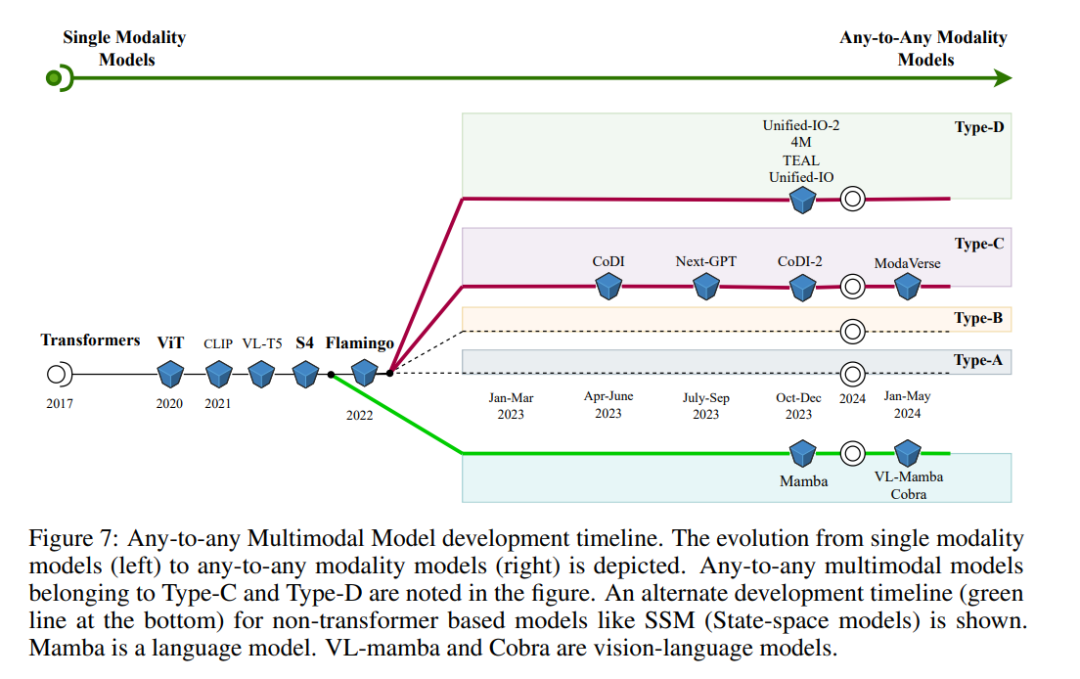
本节探讨了具有多模态输入和多模态输出的多模态模型。目前存在大量将任意输入模态转化为文本模态输出的模型。相比之下,能够生成非文本模态输出的多模态模型显著较少。多模态输出生成是多模态领域的主要挑战之一。类型C和类型D多模态架构在任意到任意多模态模型的发展前沿。代表性模型在图7中突出显示。这些主流的多模态模型架构解决了多模态生成的一些但并非全部的挑战性问题。 类型D通过利用输入标记化简化了训练过程,从而能够使用标准的自回归目标函数进行模型训练。然而,它在应对构建多模态生成模型所需的大数据量和计算需求方面仍然面临局限性。类型C通过利用预训练组件并将其与高效的连接器/适配器集成来解决与数据和资源相关的挑战。然而,由于模型架构中不同组件关联的目标函数多样化,训练过程仍然具有挑战性。