

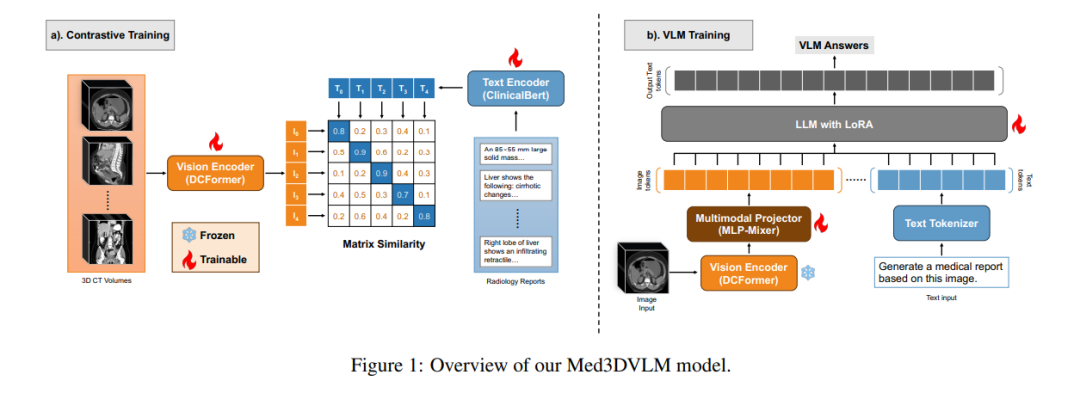
视觉-语言模型(VLMs)在二维医学图像分析中已展现出潜力,但将其扩展到三维领域仍面临挑战,主要源于体数据的高计算需求以及三维空间特征与临床文本的对齐困难。为此,我们提出Med3DVLM——一种通过三项关键创新解决这些难题的三维视觉-语言模型: 1. DCFormer编码器:采用分解式三维卷积的高效架构,可规模化捕捉细粒度空间特征; 1. SigLIP对比学习策略:基于成对Sigmoid损失的训练方法,无需依赖大批量负样本即可提升图文对齐效果; 1. 双流MLP-Mixer投影器:融合图像多层次特征与文本嵌入,生成更丰富的多模态表征。
我们在包含120,084例三维医学影像的M3D数据集(含放射学报告和视觉问答数据)上评估模型性能,结果显示Med3DVLM在多项基准测试中均取得突破: * 图文检索:在2,000样本上R@1达61.00%,显著超越当前最优模型M3D-LaMed(19.10%) * 报告生成:METEOR分数36.42%(基线14.38%) * 开放式视觉问答(VQA):METEOR 36.76%(基线33.58%) * 封闭式VQA:准确率79.95%(基线75.78%)
这些成果证明Med3DVLM能有效弥合三维影像与语言之间的鸿沟,为临床应用的规模化多任务推理提供支持。项目代码已开源:https://github.com/mirthAI/Med3DVLM。
成为VIP会员查看完整内容
相关内容
Arxiv
37+阅读 · 2023年4月19日
Arxiv
203+阅读 · 2023年4月7日
Arxiv
138+阅读 · 2023年3月29日
相关VIP内容
相关资讯
相关论文
Arxiv
37+阅读 · 2023年4月19日
Arxiv
203+阅读 · 2023年4月7日
Arxiv
138+阅读 · 2023年3月29日