

在今日举办的第四届中国计算机学会集成电路与自动化学术会议(CCF DAC)上,一份名为《集成芯片与芯粒技术白皮书(2023版)》的白皮书重磅发布。刘明院士和孙凝晖院士等国内多位集成芯片和芯粒领域专家参与了讨论和编写。这份白皮书不仅剖析了集成芯片和芯粒领域的重要技术,而且包含了本领域的趋势判断分析,为我国集成芯片与芯粒领域的技术攻关和发展规划提供了重要参考。
说 明:本白皮书基于“集成芯片前沿技术科学基础”专家组组织的多次讨论内容,由秘书组全体成员共同整理和编写而成。在编写过程中,为了更全面地呈现本领域相关技术,编写组增加了部分技术调研内容和趋势判断分析。集成芯片作为一个新兴领域,其涉及的概念和技术仍处于不断发展之中,我们也意识到本白皮书中可能存在内容阐述不够充分、不够系统的问题,也诚恳欢迎提出宝贵建议。
**1、前言 **
1.1 背景
集成电路是现代信息技术的产业核心和基础。随着信息技术的不断发展,人工智能、自动驾驶、云计算等应用通常要分析和处理海量数据,这对计算装置的算力提出了全新的要求。例如,在人工智能领域,人工智能大模型的算力需求在以每 3-4 个月翻倍的速度增长。然而,集成电路设计遇到“功耗墙”、“存储墙”、“面积墙”,传统集成电路尺寸微缩的技术途径难以推动算力持续增长。另一方面,在“万物智能”和“万物互联”的背景下,产业应用呈现出“碎片化”特点,需要探索新的芯片与系统的设计方法学,满足应用对芯片敏捷设计的要求。
在这样的背景下,需要一种新的技术途径,可以进一步突破芯片算力极限、降低芯片设计复杂度。集成芯片是芯粒级半导体制造集成技术,通过半导体技术将若干芯粒集成在一起,形成新的高性能、功能丰富的芯片。通过芯粒的复用和组合,可快速满足多种多样的应用需求,带来芯片设计、制造、下游需求等全产业链的变革。 对于我国而言,集成芯片技术对于集成电路产业具有更加重要意义。由于我国在集成电路产业的一些先进装备、材料、EDA 以及成套工艺等方面被限制,导致我国短期内难以持续发展尺寸微缩的技术路线。集成芯片技术提供了一条利用自主集成电路工艺研制跨越 1-2 个工艺节点性能的高端芯片技术路线。同时,我国集成电路产业具有庞大市场规模优势,基于现有工艺制程发展集成芯片技术可以满足中短期的基本需求,并可借助大规模的市场需求刺激集成芯片技术的快速进步,走出我国集成电路产业发展特色,并带动尺寸微缩路径和新原理器件路径的共同发展。
本技术白皮书邀请了集成芯片与芯粒领域的优势研究力量,详实分析了集成芯片的技术途径和国内外发展现状,总结了我国在集成芯片领域的基础优势和面临的挑战,希望能够为技术规划、技术攻关、产业政策等提供参考。在撰写过程中,有很多未尽之处和编委们的知识所限,也请批评指正。
1.2 本白皮书意义
本白皮书阐述了集成芯片与芯粒的内涵、集成芯片架构与电路设计技术、集成芯片 EDA 和多物理场仿真技术、集成芯片的工艺原理,最后介绍了集成芯片的设计挑战与机遇。具体结构如下:
- 第一章介绍了发展集成芯片和芯粒的重要意义以及本技术白皮书的内容。
- 第二章概述了集成芯片与芯粒的内涵。
- 第三章分析了集成芯片架构与电路设计技术,详细阐述集成芯片设计方法、多芯粒并行架构、芯 粒互连接口协议以及芯粒间高速接口电路等关键技术。
- 第四章分析了集成芯片 EDA 和多物理场仿真的相关技术,包括集成芯片布局布线 EDA、芯粒尺 度的电 - 热 - 力多场耦合仿真以及集成芯片的可测性与测试技术。
- 第五章分析了集成芯片的工艺原理,包括 RDL/ 硅基板(Interposer)制造工艺、高密度凸点键 合和集成工艺、基于半导体精密制造的散热工艺等。
- 第六章讨论了集成芯片的设计挑战与机遇,为未来集成芯片的发展提供参考路径。
在高性能芯片发展受制的背景下,从我国的产业现状出发,发展集成芯片——这条不单纯依赖尺寸微缩的新路径,是我国集成电路领域的重要的发展方向。本白皮书希望学术界和产业界更广泛而深入地了解集成芯片和芯粒技术,共同推进集成芯片技术蓬勃发展。
2、集成芯片的内涵
2.1 集成芯片与芯粒的定义
传统集成电路是通过将大量晶体管集成制造在一个硅衬底的二维平面上形成的芯片。集成芯片是指先将晶体管集成制造为特定功能的芯粒(Chiplet),再按照应用需求将芯粒通过半导体技术集成制造为芯片。其中,芯粒(Chiplet)是指预先制造好、具有特定功能、可组合集成的晶片(Die),也有称为“小芯片”,其功能可包括通用处理器、存储器、图形处理器、加密引擎、网络接口等 [1]-[10]。硅基板(Silicon Interposer),是指在集成芯片中位于芯粒和封装基板(Substrate)之间连接多个芯粒且基于硅工艺制造的载体,也有称为“硅转接板”、“中介层”。硅基板通常包含多层、高密度互连线网络、硅通孔 (Through Silicon Via, TSV) 和微凸点 (Micro Bump),保证了电源、数据信号在芯粒之间和封装内外的传输,而且可以集成电容、电感等无源元件和晶体管等有源电路。

图 2.1 集成芯片与芯粒的定义
集成芯片的概念源于 2010 年台积电的蒋尚义博士提出的“先进封装”概念,他提出可以通过半导体互连技术连接两颗芯片,从而解决单芯片制造的面积上限,解决板级连接的带宽极限问题。而后,时任美国美满电子公司总裁的周秀文博士(Sehat Sutrardja)将“模块化”设计思想与方法进一步融入。经过多年学术界和企业的发展,“先进封装”已无法涵盖多芯粒集成后所形成的新系统的科学与技术,于是在 2022 年自然科学基金委召开的双清论坛上,孙凝晖院士、刘明院士以及蒋尚义先生等我国学者在凝练相关基础技术后提出“集成芯片(Integrated Chips)”这一概念替代“先进封装”、“芯粒”等称谓,用于表达其在体系结构、设计方法学、数理基础理论、工程材料制造等领域中更丰富的含义。**集成芯片设计对比传统的集成电路单芯片设计可实现如下突破:**首先,它可实现更大的芯片尺寸,突破目前的制造面积局限,推动芯片集成度和算力持续提升;其次,它通过引入半导体制造工艺技术,突破传统封装的互连带宽、封装瓶颈;最后,它通过芯粒级的 IP 复用 / 芯粒预制组合,突破规模爆炸下的设计周期制约,实现芯片的敏捷设计。除了上述技术突破外,集成芯片还能获得成本上的收益。传统的单一芯片制造尺寸越大,制造过程中的缺陷率和成本越高。而芯粒技术允许将一个大尺寸的芯片拆分为多个小尺寸的芯粒,每个芯粒独立进行制造。由于芯粒尺寸相对较小,可以更好地控制制造过程,减少制造缺陷率和成本。另外,不同芯粒可用不同的工艺制程完成,突破单一工艺的局限。例如,可以将传统的电子芯片与光电子器件集成在同一芯片上,实现光电混合芯片。这种光电混合芯片结合了电子和光子的优势,可以在高速数据传输、光通信、光计算等领域发挥重要作用。上述技术也能够实现更多种类的新型芯片。例如,集成传感器、处理器、无线通信模块和人工智能加速器等多种功能,可以构建出具备感知-存储-计算通信 - 控制一体的智能芯片。在集成芯片发展过程中,有一些并行发展的概念。集成芯片和封装、微系统主要区别在于设计方法与制造技术。集成芯片是自上而下的构造设计方法,芯粒的功能是由应用分解得到的,而不是基于现有模组、通过堆叠设计方法实现性能和功能的扩展。集成芯片基于半导体制造技术实现集成,无论连接和延迟,都接近于芯片而不是 PCB 或者有机基板,因此最早做集成芯片工作的是台积电等芯片制造厂商。另外,我国科学家也提出了晶上系统[13] 和集成系统 [14] 等概念,在技术理念上与集成芯片有很多类似之处,相比而言,集成芯片更侧重于综合性和面向芯片形态。2.2 集成芯片是集成电路性能提升的三条路径从技术上看,目前主要有三条提升芯片性能的发展路径,如图 2.2 所示,三条技术路径从不同维度共同推动集成电路的发展。
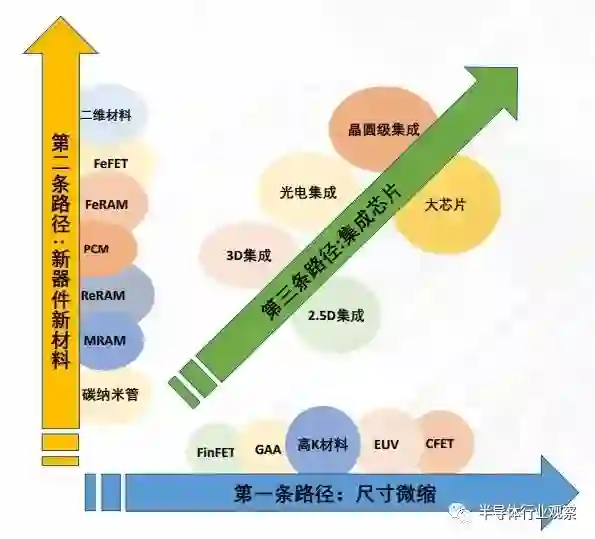
第一条路径是通过将晶体管的尺寸不断微缩实现集成密度和性能的指数式提升,也被称为遵循“摩尔定律”的发展路径。1965 年戈登·摩尔指出,集成电路的晶体管数目大约每 18-24 个月增加一倍。摩尔定律、登纳德缩放定律、以及同时期的体系架构创新,包括指令级并行、多核架构等,共同推动了芯片性能随工艺尺寸微缩的指数式提升。
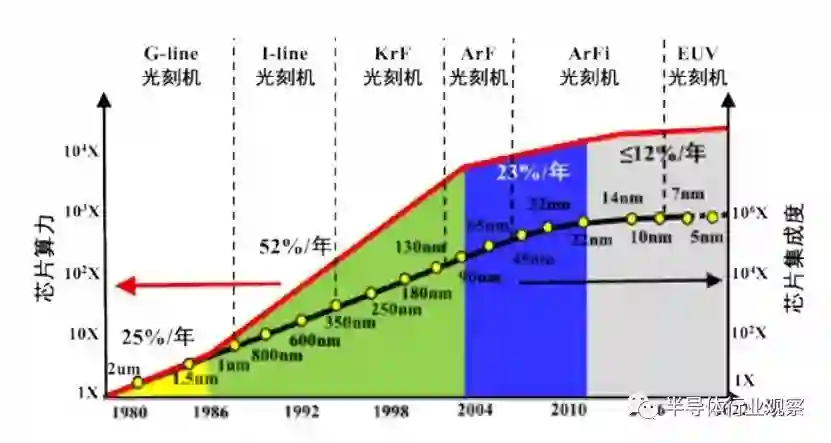
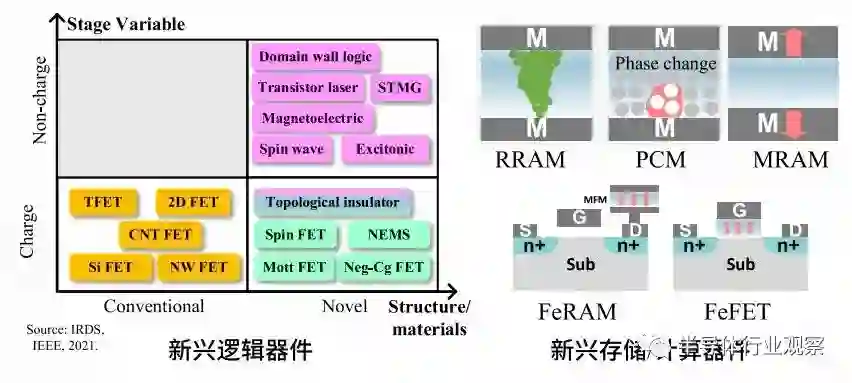
随着集成电路工艺进入 5nm 以下,尺寸微缩接近物理极限,单纯依靠缩小晶体管尺寸提高芯片性能的空间变小,同时带来了成本与复杂度的快速提高。芯片散热能力、传输带宽、制造良率等多种因素共同影响,形成了芯片功耗墙、存储墙、面积墙等瓶颈,限制了单颗芯片的性能提升。可以说,摩尔定律的放缓已成为国际和我国集成电路发展的重大挑战。第二条路径是通过发展新原理器件,研发新材料,实现单个晶体管器件的性能提升。随着铁电存储器 FeRAM、阻变存储器 RRAM、磁存储器 MRAM、相变存储器 PCM、铁电晶体管 FeFET 等多种新原理器件的发展,结合宽禁带半导体、二维材料、碳纳米管等新材料的研究,探索超越传统CMOS 器件性能 / 能效的新型器件和突破冯诺依曼架构的新型计算范式成为一个重要的研究领域。然而,新原理器件是面向未来的芯片性能提升发展路径,从科学研究到实际应用的周期通常较长,难以在短时间内解决当前高性能集成电路芯片受限的挑战。
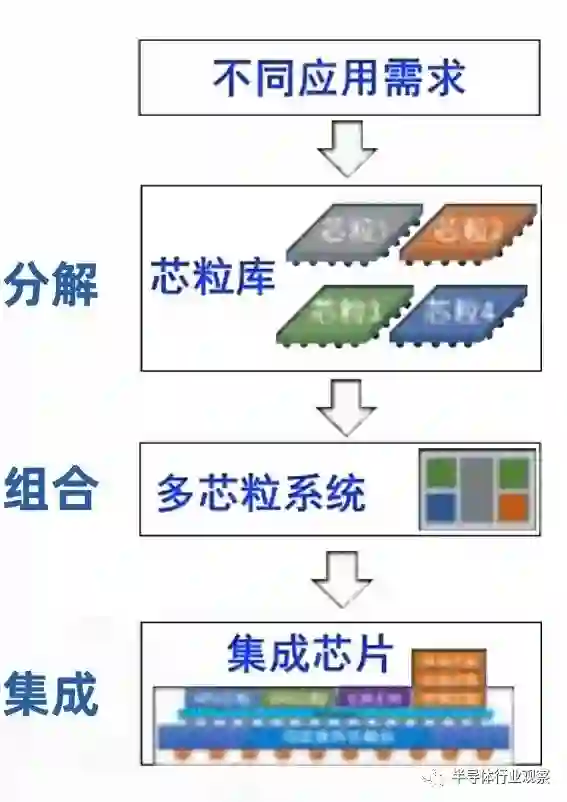
随着技术体系和产业生态逐渐构建,集成芯片将发展为芯片性能提升的第三条主路径。芯片的性能主要取决于芯片集成的晶体管规模,而晶体管规模又取决于芯片制造面积。集成芯片路径能够有效突破芯片制造的面积墙瓶颈。芯片的“面积墙”,是指单颗芯片的制造面积受限于光刻机可处理的极限尺寸和良率。一方面,最先进的高性能芯片(如 NVIDIA H100 GPU 等)面积正在接近光刻面积极限。同时,单芯片良率随面积增长快速下降,在高成本的先进工艺下,该问题更加具有挑战性。集成芯片能够通过多颗芯粒与基板的 2.5D/3D 集成,突破单芯片光刻面积的限制和成品率随面积下降的问题,成为进一步提升芯片性能的可行路径。另外一方面,集成芯片技术是一条不单纯依赖尺寸微缩路线提升芯片性能的重要途径,在短期内难以突破自主 EUV 光刻机和先进节点制造工艺的情况下,可以提供一条利用自主低世代集成电路工艺实现跨越 1-2 个工艺节点的高端芯片性能的技术路线。集成芯片这一第三条路径与尺寸微缩、新原理器件的前两条路径并不互斥。三条路径分别从不同的维度提升芯片性能,并能够相辅相成。集成芯片能够根据应用的性能、功耗、成本等需求进行合理的功能划分,最优化各个芯粒的工艺节点。尺寸微缩路径为集成芯片中单个芯粒的性能提升和芯粒间互连带宽的提升提供了一个重要的设计维度;在制造工艺较为成熟之后,基于新原理器件的特定功能芯粒也可以引入到集成芯片中,为进一步的性能和功能提升提供发展驱动力。2.3 集成芯片将引导集成电路设计的新范式系统工程学中,即使元器件性能相对落后,通过复杂系统跨学科优化,也可以实现高性能系统,或者反过来“如果一个一个局部构件彼此不协调,那么,即使这些构件的设计和制造从局部看是很先进的,但这部机器的总体性能还是不合格的”。集成芯片采用系统工程学的原理,发展自上而下构造法的集成电路设计新范式。自上而下意味着芯片结构适配应用特征,自上而下采用“分解 - 组合 - 集成”的方法。根据应用特征,抽象分解成若干标准的芯粒预制件,将众多芯粒预制件,按照结构组合成不同应用领域的芯片,将芯片制造分解为芯粒预制件的制造和多芯粒集成。下例展示了处理器芯片采用集成芯片范式后的新流程:
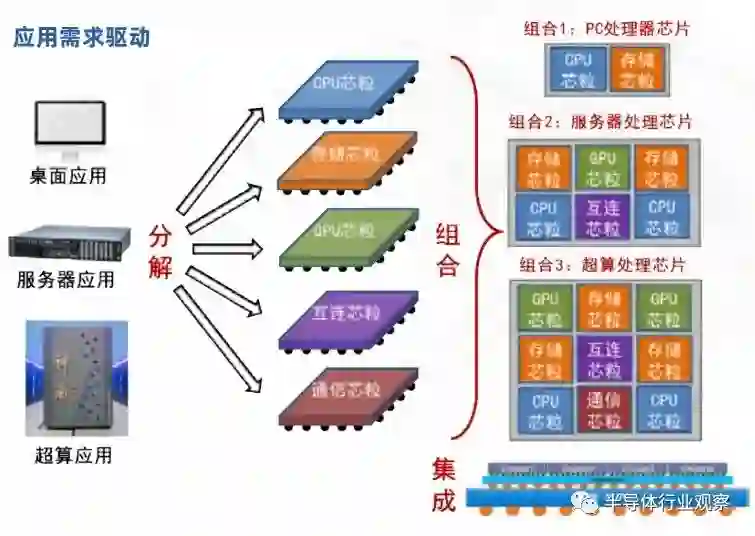
图 2.5 自上而下的“分解 - 组合 - 集成”设计范式在处理器芯片上的示例
集成芯片将带来基于芯粒复用的芯片敏捷设计方法。未来,芯片的发展需要应对物端计算系统碎片化,多样性的挑战 [11];同时,每个芯片对应的市场都较小,难以实现如 PC、手机芯片大的出货量,这个矛盾现象也被称为“昆虫纲悖论”——系统个性化和通用性的矛盾 [12]。随着芯片制程的不断微缩,基于越先进的工艺制程来设计物端芯片面临的复杂度和设计成本将进一步加剧上述问题。现有的物端芯片的设计方法,是将大量第三方 IP 与专有 IP 整合形成 SoC,并在采用同一个制程工艺进行制造。典型的 IP 包括 CPU、模拟传感器、存储器、加速器、接口驱动等。上述在一个单芯片上集成的方案在设计复杂度和商业成本上难以解决昆虫纲悖论。集成芯片技术为解决昆虫纲悖论提供了一条新思路。除了具有核心优势的专用“芯粒”外,集成芯片设计厂商可以选择第三方的“芯粒” 预制件形式提供的 IP,通过半导体集成工艺将芯粒在一个封装体内相连接。上述方案能够降低芯片设计难度,提升灵活性和效率,适应各种碎片化应用场景。商业上,上述方案仅对芯粒预制件的出货量提出需求,如 CPU,蓝牙 /Wifi 模组等核心模块,可以大大降低商业成本,并规避单一芯片厂商可能造成的垄断风险。集成芯片为碎片化的万物智能、万物互连的人机物三元融合时代提供一种新的设计范式。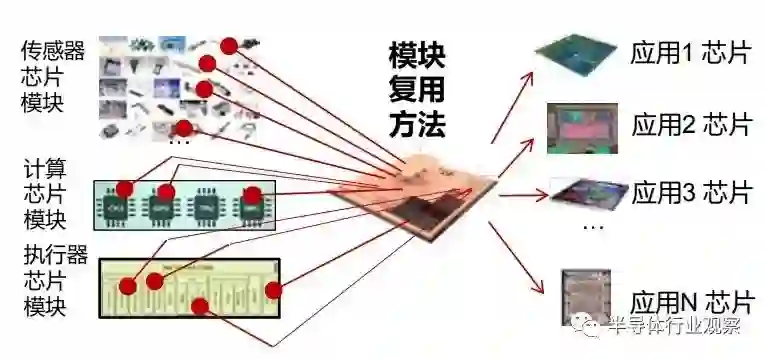
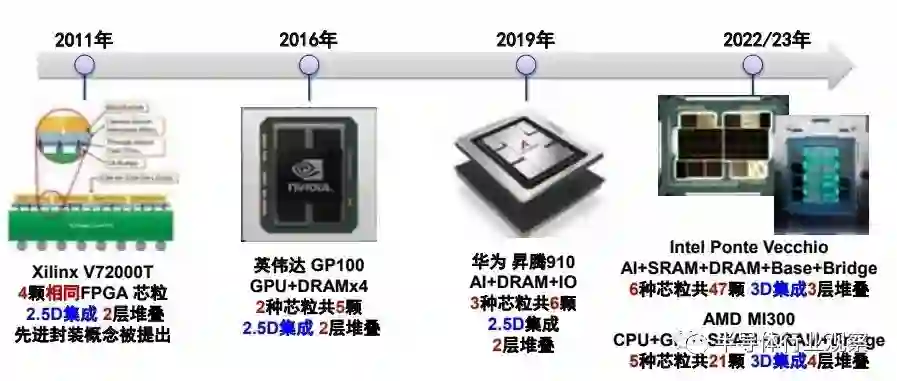
图 2.7 集成芯片朝向更多数量和种类的大规模方向
近年来,随着 TSV、铜 - 铜混合键合等工艺的成熟,3D 集成芯片成为了高性能处理器领域新的发展趋势。美国 AMD 和 Intel 公司均基于 3D 集成芯片技术,设计了面向超算的高性能超算处理器芯片。上述产品将将 6-8 种,超过 20 个芯粒的芯粒集成在一个系统中,最终实现了更大规模(千亿以上规模数量级晶体管)、更复杂的集成。在 2.5D 集成上,基于重分布层(Re-Distribution Layer)的扇出工艺(FanOut)可以实现更大规模的芯粒集成,美国 Tesla 公司基于 FanOut 工艺开发面向人工智能的训练处理器集成芯片 DOJO,RDL 基板的总面积达到 20000mm²,包含 25 个 D1 多核处理器芯粒和光电融合的通信芯粒。我国研发机构在高集成度上取得了进展。比较有代表性的包含,2022 年中科院计算所智能计算机中心和之江实验室联合开发了“之江大芯片一号”,该芯片成果集成了 16 个芯粒,每个芯粒含 16个 CPU 核,无论是集成的芯粒数和体系结构上的计算核心数,都实现了突破,从体系架构和设计方法学上,验证了利用集成芯片突破单处理器芯片的算力极限技术途径。目前,正在开展“之江大芯片二号”的工作,集成度和性能将进一步提升。2022 年,复旦大学集成芯片与系统全国重点实验室基于集成扇出封装工艺实现了存算一体 2.5D 芯片,采用片间按层流水的可扩展架构实现了系统算力与存储规模的按芯粒比例的线性增长,避免了“一系统一设计”的高复杂度问题。此外,阿里达摩院联合紫光国芯研发基于 3D 混合键合工艺的智能加速器 -DRAM 堆叠集成芯片,豪威科技的采用三层堆叠工艺将图像传感器芯粒、模拟读出电路芯粒、图像信号处理与 AI 芯粒集成为一个组件,面向像素的不断提升,最小化芯粒间的通信开销。

图 2.8 (a) 之江大芯片 1 号;(2)存算一体 2.5D 芯片
集成芯片中,由于每个芯粒由不同的单位设计,因此接口的标准化是系统能够高效率组合的关键因素。在 Intel 的主导下,2022 年 3 月,通用高速接口联盟(Universal Chiplet Interconnect Express,UCIe)正式成立,旨在构建芯粒技术在芯片上的互联标准。在我国,中国计算机互连技术联盟的《小芯片接口总线技术要求》和中关村高性能芯片互联技术联盟的《芯粒互联接口规范》等接口规范也已公布。 3、集成芯片的架构与电路设计3.1 从集成芯片到芯粒:分解与组合的难题集成芯片采用了“分解 - 组合 - 集成”的新设计范式。“分解”是指根据不同应用的特征,抽象出若干标准的芯粒预制件;“组合”指将众多的芯粒预制构件按照某种结构组合设计成不同应用领域所需要的专用芯片和系统。根据目标应用,构建最优的芯粒分解 - 组合设计方法是重要的技术难题。( 一 ) 芯粒分解研究出于成本、安全性、系统性能等多重因素的考量,学术界和工业界持续关注芯粒分解技术。成本因素。摩尔定律的放缓与日益增长的性能需求导致芯片面积日益增长。这不仅引发了芯片良率的下降,还降低了晶圆的利用率,拉高了芯片的制造成本。学术界对芯粒系统的成本进行了分析建模,它由 RE 成本(Recurring Engineering Cost)与 NRE 成本(Non-Recurring Engineering Cost)构成。RE 成本是每片芯片制造都要支付的成本,包括晶圆、封装、测试的成本等。NRE 成本指研发、制造芯片产品时所支付的一次性费用,包括人力成本、IP 授权费用、光罩成本等。UCSB 提出的模型表明 RE 成本受到芯粒工艺、系统规模、封装良率等多重因素的影响 [18]。清华大学的模型 [19] 将 NRE 成本表示为系统总体、各个芯粒、芯粒中包含模块的 NRE 成本之和。
安全性因素。Fabless 的模式带来了诸如版图泄露、硬件木马植入等安全风险。分离制造 [15] 通过将芯片分为多个部件分别交于不同的晶圆厂,使晶圆厂无法获得芯片的全部信息,来保护信息不被泄露。而基于分解的芯粒技术天然地具有分离制造的特性,并且相较于传统的基于金属层过孔的分离制造方法,芯粒使用标准的片间通信接口,在工艺上降低了封装的难度。此外,芯粒分解需要从系统角度综合考虑。芯粒分解虽然能够降低成本、提高芯片良率和安全性,但是会引入芯粒间通信的功耗、性能开销以及额外面积开销。因此,芯粒分解不能仅关注单个芯粒构件的设计,需要对整条产品线进行分析,以发掘芯粒在多个产品中的复用机会。工业界目前已经出现多个将复杂功能芯片分解为多个芯粒构件的工作:AMD 在第二代 EPYC 架构中将计算与 IO 部分拆分为不同的芯粒 [7];海思基于 LEGO 理念,将 SoC 分解为 CPU 计算、计算 I/O、AI 计算等少量的芯粒,并利用它们组合出多种产品 [8];Intel 也将芯粒技术应用到了 FPGA、CPU、GPU 等产品上,其中 Ponte Vecchio GPU 被分解为计算、存储、通信等芯粒,数量高达 47 块 [9]。现有的芯粒分解方案往往依赖于设计人员的经验,这种手工的分解方式难以穷尽所有的设计空间,产生的效益、开销也往往不是最优的 [20]。因此,当前亟需自动化芯粒分解技术。目前已有一些简单的划分策略,如将设计拆分为多个相同芯粒的均匀划分方式 [18],与基于最小割算法的均衡划分方式[21]。这些技术缺乏对成本、性能、功耗的综合优化,也没有在多个硬件设计中寻找可重用芯粒的能力。( 二 ) 芯粒组合研究芯粒组合过程中,设计人员根据用户输入的应用与优化目标,从芯粒库中选出最优芯粒并组合。工业界和学术界对这一问题也开展了探索:zGlue[22] 提供了包含 MCU、传感器等芯粒的库,用户可以根据自己的需求手动地选择集成的芯粒;海思利用 CPU 芯粒 +I/O 芯粒组合出服务器所需的芯片,利用 AI 计算芯粒 + 计算 /IO 芯粒组合出针对 AI 训练的芯片 [8];通过使用不同数量的 CPU 计算芯粒,AMD 组合出了包含不同核数的服务器芯片 [7]。由于缺乏统一的接口标准,目前工业界的实践主要为in-house 芯粒的组合。现有的芯粒组合方案 [8][9] 往往是手动设计的,集成效率低且缺乏深层优化,这也催生了自动化芯粒组合的研究。UCLA 提出了面向处理器的芯粒组合框架 [23],用以寻找针对多个应用负载的最优芯粒系统集合,其优化目标为系统功耗、性能、成本等。计算所提出了一套敏捷芯粒集成框架 [24],可以自动根据用户输入的应用描述,从芯粒库中选择出性能、面积、成本等指标最优的芯粒组合,并且完成应用任务在芯粒上的映射。无论是面向通用应用的多 CPU 芯粒 [7] 与多 GPU 芯粒 [25] 的组合,还是面向专用领域的芯粒组合,均可以通过集成不同数量的芯粒来获得不同性能的系统。如图 3.2 所示,面向 AI 领域的 Simba[27] 系统以被灵活拓展,形成适用于各个场景的产品,也有学者提出了能搜索针对单个应用和多个特定应用的芯粒组合框架 [23][24]。

图 3.2 AI 系统性能与芯粒数量组合的关系 [27]
无论是芯粒分解还是芯粒组合,都是复杂的优化问题,依靠人力难以应对庞大的搜索空间,这也给予了设计自动化工具和大规模集成芯片仿真器新的机遇。在芯粒时代,我们需要更高效的 EDA 工具来更进一步地优化系统成本,降低集成开销,促进芯粒生态繁荣。3.2 芯粒间互连网络与片上网络(Network-on-Chihp)相对应,基板上网络(Network-on-Interposer)实现芯粒间互连互通,作为各处理单元间的数据传输基础设施,是影响数据通信性能和功耗的关键,包含互连拓扑、路由和容错机制三个关键技术。(一) 互连拓扑从互连网络的通信效率进行考虑,网络拓扑结构从固定、简单的通用拓扑结构演进到不规则和可重构拓扑结构,以适配不同的应用数据传输需求。通用互连网络的拓扑结构设计简便,适用于多种数据通信场景。但是通用性和性能互为制约,通用拓扑结构设计并不能提供最高的通信效率。因此,不规则和可重构的互连拓扑结构以降低通用性为代价,提供了更高性能的互连解决方案。网格(Mesh)以及环形曲面(Torus)等基础网络结构,由于其结构简单规则,是芯粒间网络中最为广泛使用的通用拓扑,典型拓扑网格结构如图 3.3 所示。采用通用拓扑构成互连网络的有NVIDIA 的 Simba[27] ,其芯粒内与芯粒间均采用了网格型拓扑,Conical-Fishbone 时钟域网络中使用的无缓冲网格拓扑。MCM-3D-NoC[29] 架构基于有源基板,芯粒间采用芯粒堆叠互连的三维(3D)堆叠拓扑结构。此外,POPSTAR[30][31] 基于光电连接的芯粒间环形(Ring)结构,以及无缓冲多环(Multi-Ring)结构 [32] 属于通用拓扑。
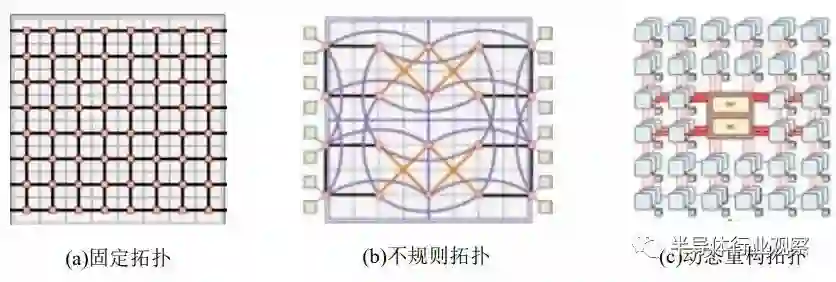
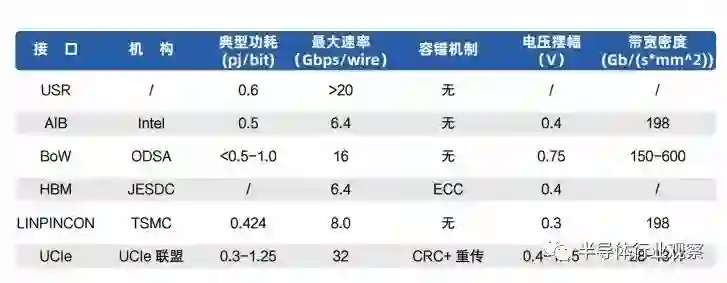
图 3.3 典型的拓扑网络 [35][43]当网络流量不均衡或动态变化,通用、规则的拓扑结构无法适配当前流量需求将导致拥塞,而不规则拓扑结构则可以根据相应流量特征优化网络链路或结构,以获得更高性能。Kite 拓扑系列 [35]基于基板上网络(Network-on-Interposer)和片上网络(NoC)的频率异质性,在频率限制下最大化有效链长,减少跳数降低延迟,提高网络吞吐量。与常见通用拓扑结构相比,Kite 拓扑结构中使用了更多不同长度和不同方向的链路,提高通信效率。此外,除有线链路的不规则设计外,也有一些设计方案基于多芯粒无线接口互连技术 [36][37][38],支持芯粒间多方式互连,可实现多种不规则网络拓扑。不规则拓扑结构针对应用的通信流量需求进行了优化,然而不同应用的流量特征差异极大且存在动态时变特征,因此出现了能够根据应用流量动态变化的可重构拓扑结构,动态地根据应用需求进行重配置。Adapt-NoC[39] 架构采用 SMART[40] 构建自适应芯粒路由,可重构链路设计 [41] 在有源基板中连接子网络,并且动态分配链路带宽以提高网络吞吐量,采用 Panthre[42] 技术进行网络拓扑重配置,将网络划分为多个子网络,使每个子网络可以根据通信需求提供不同的网络拓扑。中科院计算所提出了可重构基板网络(NoI)设计方法 [43] 基于胖树生成适应各种分布式训练模式的拓扑,可适应各种神经网络应用,特别采用了环和树结合的拓扑结构适用于数据并行中的数据交换。可重构拓扑允许根据应用数据传输需求进行动态配置和调整,提供了高灵活性、高适应性、高性能的解决方案。然而,如何实现更大规模的动态可重构互连拓扑结构设计和容错机制,并实现互连架构的准确性能评估,仍是芯粒间互连网络拓扑结构设计的重要挑战。(二) 路由路由算法是影响集成系统通信开销的另一重要因素,其决定了数据传输的路径长度和可靠性。为了能够适配多种复杂的互连网络方案,同时考虑芯粒互连集成设计方案的立体化趋势,需要面向芯粒集成的系统特性进行路由算法设计。芯粒集成系统的路由算法需要满足以下特性:1)拓扑无关性,路由算法应该能够适用于通用和不规则的拓扑结构,而不仅限于特定的拓扑。这样可以适应不同芯粒集成方案中可能存在的多样化互连网络拓扑。2)完全可达性,若源和目的地之间存在路径,路由算法应该始终能够找到该条可行的路径。即使是复杂的垂直堆叠和基板互连结构,路由算法也应确保算法能够指出能够从源芯粒传输到目的芯粒的可行路径。3)故障独立性,路由算法需要具备对节点或链路故障的容错能力。当发生故障时,路由算法应该能够重新计算路径,绕过故障节点或链路,保证数据传输的可靠性和连通性。4)可扩展性,路由算法引入的开销应是独立的,或者仅随着网络规模的变化而变化。无论系统中有多少个芯粒或多复杂的堆叠结构,路由算法都应该能够高效地处理通信需求,而不会导致性能下降或通信开销过大。在设计面向芯粒集成的系统的路由算法时,需要根据具体的集成方案和系统需求进行算法的优化和定制,这样可以实现高效可靠的数据传输,适应复杂的互连网络结构,并充分发挥芯粒集成技术的优势。(三) 容错机制在面向芯粒集成的互连网络设计中,考虑到单个芯粒内集成了更高数量级的晶体管和先进制程的不完善,因此故障率相对较高。为了应对永久性故障带来的系统性能损失,可以采取以下优化措施提升系统的容错性能:容错拓扑设计和容错路由。容错拓扑是指在芯粒间的互连设计中,通过采用能够容忍故障和提供冗余路径的结构布局方式,提升系统的容错性能。容错拓扑可以采取以下策略:(1)冗余网络。使用多条路径建立芯粒之间的通信连接,如果某条路径发生故障,可以通过其他路径进行通信,保证数据传输的可靠性和连通性。(2)高连接性网络。高连接性网络的目标是确保大多数节点具有较高的节点基数,从而为网络提供路径多样性,并以此增强系统的容错能力,对于次要节点,可以适当的降低节点基数以减小硬件开销。容错路由是指在芯粒间的互连设计中,通过设计能够应对永久性故障导致的网络变化的路由算法,提升系统的容错性能。当网络中出现错误时,路由算法需要具备适应网络变化的能力,并自适应的执行不同的路由策略以绕过或避免故障区域的通信,这也是容错路由的重要研究方向。为了提升错误处理能力,容错路由算法可以采取以下策略:(1)动态路径选择。路由算法可以根据实时的网络状态和错误信息,动态选择最佳路径来绕过故障区域。这可以通过监测链路状态、节点负载、延迟等指标来实现。路由算法可以基于这些信息做出即时的路由决策,将数据流量导向可用的路径。(2)基于负载均衡的路由。当网络中出现故障时,路由算法可以考虑负载均衡策略来选择路径。它可以根据节点的负载状况,选择相对较空闲的路径进行通信,以避免将更多的流量导向已经过载或故障的区域。国内中科院计算所早期在研究 3D TSV 设计时,针对 TSV 提出了复用容错的技术思路 [44]和容错 NOC 设计 [50],清华大学、合肥工业大学等也有相关研究 [51][52]。3.3 芯粒互连的接口协议现有面向芯粒的接口协议主要分为两类:物理层接口协议和完整的协议栈。大多数物理层接口协议或标准主要关注引脚定义、电气特性、bump map 等基础特性,可以保证数据比特流的点对点传输。在此基础上,协议栈对路由方式、数据结构、可靠传输机制、一致性、流量控制等做了更详细的规定,一般可以建立端到端的可靠数据传输。(一) 物理层美国英特尔公司率先提出了 AIB (Advanced Interface Bus),用于规范芯粒间互连的物理层协议,可适应不同制造和封装工艺 [45]。一个 AIB 接口由一个或多个 AIB 通道组成,每个通道包含 20-640根数据线,两对差分时钟以及用于初始化的边带信号。AIB 在单线极大的数据速率下,以扩展位宽的方式获得高带宽。此外,AIB 可以通过启用冗余的 bump 来规避封装缺陷,以此来实现一定程度的容错功能。由 Facebook、AMD 等企业共同发起的 ODSA(Open Domain-Specific Architecture)联盟提出了 BoW(Bunch of Wires)并行接口协议,BoW 的模块化的接口可对应标准封装和先进封装工艺 [46]。每个 BoW 模块包括 16 根数据线和一对差分时钟,BoW 复用主数据通路进行参数协商和初始化,无专用的边带信号。在 14nm 工艺下,Bow 以 16Gbps/wire 的传输速率以及 50mm 线长,可达到 0.7pj/bit 的较低功耗,误码率为 1E-15。与上述面向通用数据连接的接口不同,HBM(High Bandwidth Memory) 接口是 JEDEC(Joint Electron Device Engineering Council) 定义,专门用于连接 HBM 内存的并行总线接口 [47]。最新的HBM3 最多支持 16 个独立通道,每个通道的数据位宽为 64,包含 10 位行地址线和 8 位列地址线,最高数据速率为 6.4Gbps。此外,HBM 支持通过 4 位 ECC 进行纠错。此外,尽管 Chiplet 物理接口大多走的是并行化方向,但追求高速率的 Serdes 接口依靠着更高的带宽密度受到关注。USR(Ultra-Short-Reach)是一种主要面向chiplet片间互联的Serdes接口[48],可以使用单端信号或差分信号进行数据传输,在 20Gb/s 的传输速率下能够达到 0.6pj/bit 的功耗,相比于普通的 Serdes 接口有着很大优势。然而,相比于宽度更大的并行接口,USR 在带宽上存在劣势。随着 3D 封装的进展,单独支持 2.5D 的互连已经无法满足需求。因此,台积电提出了兼容 2.5D和 3D 的高能效 LIPINCON (Low-voltage-in-package-inter- connect) 互连接口协议 [49]。其可在0.8V 的电压和 0.3V 的电压摆幅下实现 0.84UI 的眼宽和 75% 摆幅的眼高,而其 256 的数据位宽和8Gbps/wire 的数据速率有待提升。(二) 协议栈芯粒间的数据传输有许多重要的功能需求,如对核间数据通信业务逻辑的详细规定、数据传输可靠性、缓存一致性、路由策略等。而物理层协议仅能保证通信双方物理电气特性上的互联互通,因此,构建完整的上层协议对芯粒接口至关重要。ODSA 首先注意到了完整协议栈的重要性,并于 2021 年提出了一种面向芯粒互连的协议架构,该架构由协议层、链路层和物理层构成。其中,物理层方案为 BoW 接口,建议在协议层复用现有协议,链路层通过 CRC 校验和重传机制实现可靠传输的基本思路。
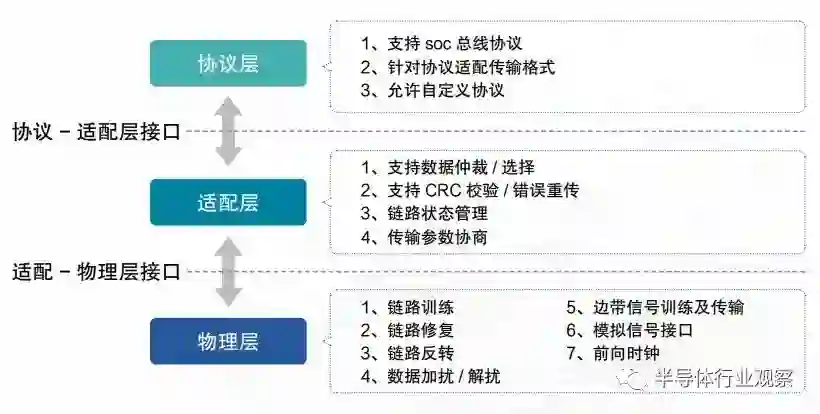
2022 年,UCIe(Universal Chiplet Interconnect Express)联盟公布了 UCIe 协议。与 ODSA 的架构类似,UCIe 由协议层、片间适配层和物理层构成。UCIe 协议层沿用成熟的 PCIe 和 CXL 协议以实现对现有生态的最大兼容,片间适配层则利用 CRC 校验以及重传机制保证数据传输的可靠性。UCIe 在物理层采用 AIB 接口,在电气特性上具有广泛兼容性的同时,可实现物理通道损坏的自动检测和通道重映射等功能。UCIe 是 chiplet 完整协议栈的典型代表,其物理层的模块化设计、容错功能、以及链路层的校验重传机制契合 chiplet 应用场景。因此,设计全新的上层协议——既定义面向chiplet 间数据传输的业务逻辑或许是以后 chiplet 接口协议发展的重点。在国内,由中科院计算所牵头的团标 T/CESA 1248—2023 是中国电子工业标准化技术协会于2023 年发布的面向 chiplet 的接口协议栈,由协议层、链路层和物理层组成。T/CESA 1248 的层次结构和功能划分与 UCIe 类似,既协议层使用 PCIe 和 CXL 实现业务逻辑,链路层实现可靠传输,物理层规定物理电气特性等。T/CESA 1248 是国内最早的面向芯粒接口的互联标准。当前面向芯粒的接口标准以并行接口为主,且强调物理接口的模块化,可以充分利用先进封装的高互连密度特性并最大化接口带宽。此外 AIB、BOW、HBM、UCIe 等主要接口协议均采用大宽度单端数据 + 随路时钟的方案,仅 USR 等少部分协议采用高速串行数据 + 时钟恢复方案。在芯粒技术带来的芯片设计积木化、敏捷化与定制化的场景下,芯粒互联协议需与厂商、架构、制造工艺解耦,拥有广泛的兼容性与开放性,才能适应芯粒异构互联、跨厂商互联的实际需求。
3.4 芯粒间的高速接口电路
芯粒间通信是基于高速接口电路完成的 , 它和传统的 PCB 级高速链路之间有一些相似之处,但也存在着关键的区别:1)超短距离:在一个封装体内,芯粒间互连距离通常小于 1 厘米,甚至可以小于 1 毫米,信道的损耗迅速降低,更利于高带宽设计;2)高密度:采用半导体制造工艺(光刻、蚀刻),芯粒间互连线间距可以在微米级,在单位面积下可以更高并行度;3)低功耗与低延迟:芯片粒间互连重点关注功耗效率、延迟和性能优化进行。芯粒间的高速接口电路包括以下几类:1)面向 2.5D/3D 集成工艺的有线(Wireline)并行通信接口;2)基于电感耦合的无线互连通信接口;3)高带宽光电互连接口。并行互连接口技术通过大量信道同时进行并行传输,以达到 Tbps 级别的传输带宽。因此,它不追求单线绝对速率与带宽,在 UCIe/AIB 等协议中,每根线的传输速率也仅为 32Gbps。实际设计中,芯片设计企业可以根据系统要求设计信道并行数量和单线速率。因此可以在不使用连续时间线性均衡器(CTLE)、时钟数据恢复电路(CDR)等大功耗模拟电路模块的情况下实现信号的传输。并行电路的时钟信号可以通过独立的信道进行传输,同时利用数控延时单元(DCDL)、相位插值器(PI)和占空比调节器(DCC)来实现数据和时钟信号的校准,这些电路的结构相对简单,由于多个数据信道可以共用一组时钟线,因此对整个收发电路的面积影响也较小。相较于传统串行接口,并行互联具有能效高(<1 pJ/bit)、延迟低、设计简单的优点,能够实现更高的集成芯片互联密度和更高效的芯粒间互联。无线互连接口也是芯粒间互联的一种解决方案。它的优势是不依赖先进封装工艺特别是 TSV,可以完全兼容现有的 CMOS 工艺。其互连是通过芯粒间电感耦合实现的。基于电感的互连接口在两个芯粒上各放置一个线圈,通过线圈间的电磁耦合传递无线信号,如图 3.12 所示。但是考虑到在电感的面积,无线互连的能效和速率方面相对于有线互连方案并无优势。此外,无线互连只适用于 3D的封装堆叠方式,不适用于 2.5D 等其它形式的集成芯片。光互连接口是更前瞻的芯粒间的接口方案,它通过集成在硅晶圆上的八波长分布式反馈(DFB)激光器阵列和光波导,可以实现单线低功耗、高性能、太比特每秒(TBps)的互连速率,较电互连高出一个数量级。但是在芯粒种实现光互连还需解决很多问题,比如集成激光器阵列如何缩小体积、降低成本、如何兼容现有 CMOS 工艺,完成异质封装。
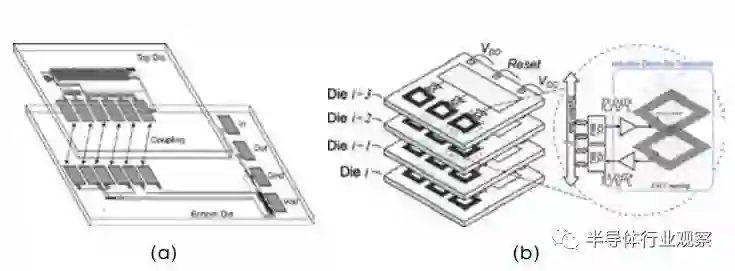
图 3.12 基于 (a) 电容耦合 (b) 电感耦合的芯粒间无线互联方式在芯粒互连的高速接口上,仍然存在这多个科学问题,如突破功耗瓶颈的新电路,兼容不同信道的可重构收发机,自适应检测与校正机制、接口电路的跨工艺自动化迁移等。应对这些挑战需要多学科交叉研究,涉及电路设计、电磁场信号完整性分析、热管理、制造工艺等领域的专业知识。
3.5 多芯粒系统的存储架构
系集成芯片中,多芯粒的存储结构是影响集成芯片的访存性能和功耗的重要因素。集成芯片的存储结构与传统的众核或服务器芯片存储结构有较多相似性,主要的优化目标为提高访存性能、降低目录等开销。因此,多芯粒系统的存储架构主要从多级存储结构的组织方式和存储管理两方面进行优化。多芯粒系统的访存性能受限于物理结构所提供的带宽,随着平面存储结构的带宽和性能已接近极限,多芯粒系统存储结构的组织方式也逐渐从平面存储结构向垂直存储结构发展。与传统的水平存储方式相比,它在垂直方向上堆叠存储单元,从而实现更高的存储密度和容量。其核心思想是充分利用垂直方向的空间增加存储单元的数量。在垂直存储中,存储单元以垂直方向堆叠在一起,形成多层结构。每一层都包含多个存储单元,通过垂直连接结构进行数据传输和访问。这种垂直堆叠的方式大大减小了存储器的占地面积,使得在相同的面积下,相比于水平排布的存储形式,可以容纳更多的存储单元,从而提供更大的存储容量。由于存储单元之间更近的距离,数据的传输路径更短,因此可以实现更快的数据访问速度和更低的访问延迟。此外,垂直存储结构还可以提供更高的数据带宽,允许同时访问多个存储层,从而进一步提升数据访问性能。垂直存储技术已经在各种领域得到应用,例如,在 3D NAND 中,多层存储单元沿各层之间的互连以垂直的形式进行叠加。在实现更短的整体连接的同时,提高了存储的容量,并减小了存储硬件占用的空间相较于传统的 2D NAND,每字节的存储成本也更低。Zen3[64] 在垂直方向上引入高速缓存3D V-Cache,额外的缓存层可以提供更高的缓存容量与更低的延迟,从而提升访存性能。处理器内的核心可以更频繁地访问高速缓存中的数据,从而减少对主内存的访问,提高数据访问速度。这些方案利用垂直存储的优势,实现了更高的存储容量、更快的数据访问速度和更可靠的数据存储。

多芯粒系统的存储通常采用非一致内存访问结构(Non-Uniform Memory Access,NUMA),NUMA 结构提供了高效的共享数据方式和灵活的资源分配方案,但相应地需要解决如何加速跨核心的数据访问、提升维持数据一致性的通信速度。层次化缓存一致性协议和目录已被广泛研究用于芯片多处理器 [53][54] 和多芯粒服务器 (multi-socket) 系统 [55]。在全局数据访问中,芯粒间缓存一致性管理访存开销较大。因此,降低缓存一致性开销的方法可以分为减少维护一致性的数据流量和针对互连结构优化一致性协议两类。减少一致性流量的根本原理在于发掘和消除一致性流量中的冗余,当连续写入的次数达到阈值时,通过执行一次写更新来优化传统的多次写入更新协议可减少写缓存的开销[57]。另外,由于不同存储层级的开销不同,因此可将共享读写缓存行移动到更低级别的缓存以减少上级缓存的写无效流量 [56]。针对互连结构优化一致性协议也是降低一致性开销的重要方法。考虑到多芯粒系统在芯粒间和芯粒内具有不同的通信结构和开销,使用 Snoop 与目录式混合的缓存一致性协议 [58],通过全局协议和本地目录协议分别实现芯粒间和芯粒内的缓存一致性可以大幅降低一致性开销。新的互连方式也为一致性协议提供了新的优化空间,WiDir[61] 结合片上无线网络技术来增强传统的基于无效目录的缓存一致性协议,以程序员透明的方式,根据访问模式,有线和无线一致性事务之间进行无缝转换。相比于传统的电网络,基于硅光子技术的互连网络有望实现更高宽带和更低延迟。PCCN[59] 作为一种基于光子缓存一致性网络的物理集中式逻辑分布式目录协议,采用带有竞争的机制解决信道共享问题,实现高效的长距离一致性相关数据包的传输。小型低成本硅光子 CAMON 芯粒 [60] 可以有效缓解多核处理器的通信瓶颈问题,提高数据移动的能效,在多芯粒系统尤其是大规模系统中发挥了重要作用。
3.6 集成芯片大功率供电电路
随着芯粒集成规模的提升,集成芯片的供电系统面临新的挑战。目前单颗高性能芯片的功耗大约在百瓦量级,例如 Intel 13 代 CPU 的 PL2 TDP 为 219W,NVIDIA H100 GPU TDP 为 350W。面向未来百芯粒规模的集成芯片,其供电需求将达到数千瓦甚至万瓦级。结合集成芯片的特点,研发新型万瓦级供电电路,是大规模芯粒集成必须解决的关键难题。集成芯片的供电系统面临多方面的约束。集成芯片对外的接口数量有限,部分芯粒完全集成在系统内部,没有直接对外的接口,因此需要在集成芯片的内部进行整个系统的电源管理。大规模芯粒集成能够采用 TSV 进行芯粒间的供电传输,但 TSV 的电流密度受限,万瓦级供电所需的 TSV 数量将严重影响整个集成芯片系统的面积。大量芯粒在不同的供电电压和电流下同时工作,需要设计高效的电源分配网络,解决芯粒间供电电流不均衡和动态变化等问题,保障芯粒稳定工作并提高能效比。同时,供电电路需要集成大面积的电容、电感等无源器件保持供电稳定,传统封装可以在 PCB 板级集成这些无源器件,而在高集成度的集成芯片系统中,如何在内部集成这些无源器件是一个新的挑战。为实现集成芯片万瓦级供电的技术路线,需要研究包括多级供电架构、电源分配网络和无源器件集成等多种技术。多级供电电路在第一级采用较高的供电电压(如 12V),在相同供电功率下通过提高电压解决 TSV 电流密度受限的问题。在后级供电电路采用高效率的 DC-DC 电路,将高供电电压转换为芯粒内部所需的较低工作电压(如 1V)。多级供电电路的一个重要挑战是如何在较先进工艺节点实现高电压的供电电路,并针对负载功率大幅跳变的情况实现快速响应。为实现高效的电源分配网络,需要研究电源网络受到供电电压、传输路径长度、寄生效应等的影响关系,探索三维垂直供电架构和动态电源分配技术等。同时,针对供电电路中大面积无源器件在集成芯片内部的集成,一种技术方案是利用 TSV 的电感特性,并在大面积基板上实现电容、电感等无源器件,实现内部集成。集成芯片的万瓦级供电是大规模芯粒集成必须解决的关键技术。需要从多级供电架构、电源分配网络和无源器件集成等多个方面开展研究,保障集成芯片的供电稳定性,提升供电效率,并缩减供电系统的体积。万瓦级供电需要与集成芯片的散热技术进行联合设计优化。同时,可以结合单芯粒的背面供电(如 Intel PowerVia)等技术实现更高的供电效率。
4、集成芯片EDA和多物理场仿真**
4.1 集成芯片对自动化设计方法与EDA工具的新需求**集成芯片的规模远远大于普通的单芯片规模,若芯片设计的复杂度与晶体管数量成比例关系,那么集成芯片的设计面临复杂度指数级发展的困境。因此,面向集成芯片设计,需要更多的自动化设计EDA 工具。
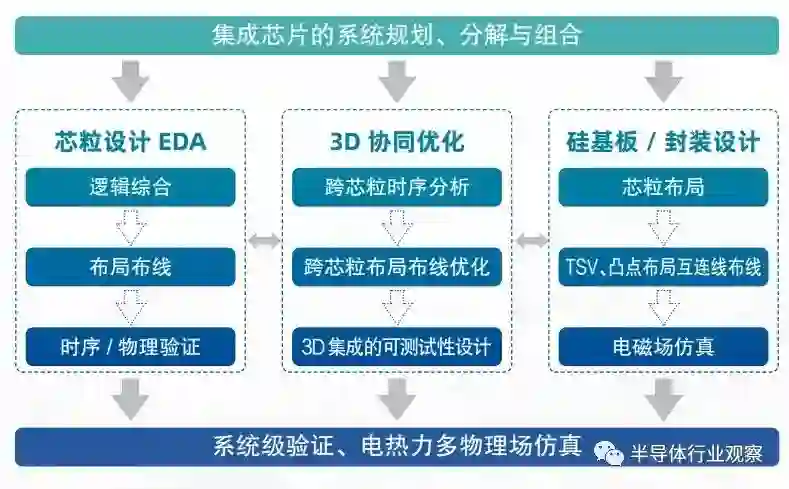
图 4.1 归纳了集成芯片对自动化设计方法的 EDA 工具的新需求,具体包括: (一)集成芯片的系统规划与分解组合:用于在具体设计之前的集成芯片的系统设计规划,完成各个功能的功能与性能的初步设计空间探索;(二)芯粒设计:与典型的 VLSI 设计方法和 EDA 类似,包含逻辑综合、布局布线与时序 / 物理设计的验证等部分;(三)硅基板(Interposer)和封装设计:用于实现芯粒间互连,需要解决芯粒的布局优化,芯粒间互连线布线、TSV/ 微凸点 / 植球的布局等物理设计,对于有源硅基板还要覆盖芯粒的 EDA 设计工具完成其电路部分的设计;
**(四)3D 协同优化设计:用于在芯粒和基板封装设计后的协同优化与验证,如芯粒 - 基板互连后的跨芯粒时序分析、布局布线优化,同时还需要考虑 3D 集成的可测性设计,因为在 3D 集成后部分芯粒已无对外直接可测的引脚,需专用方案;****(五)系统级验证与多物理场仿真:用于准确捕获和分析系统内电—热—力发生的复杂交互和现象,需要将多个物理场集成到一个统一的仿真框架中,上述物理量的交互作用包括由于封装材料的热膨胀系数的差异和结构不匹配,在不同的工作负载下产生不同的热分布,并导致硅片的翘曲、封装裂纹和分层。**其中,互连线的电磁场仿真和自动化布线、电 - 热 - 力多物理场仿真和 3D 集成芯片的可测性设计是集成芯片设计的全新 EDA 问题。
4.2 芯粒间互连线的电磁场仿真与版图自动化
伴随着芯粒数量和种类的增加,芯粒间互连线数也急剧增加。可以预计,未来的芯粒间互连线数量将达到十万甚至百万量级规模,靠手工布线的可行性低。片上布线与芯粒间布线的基础电学约束上存在差异,导致已有的片上布线的 EDA 工具难以应用到集成芯片的片间。在单个芯片内,金属布线通常涉及更高密度的互连和更复杂的布线架构,一般在网格上根据延迟的约束条件实现自动化布线,还可以通过内插缓冲电路来避免过长(100 微米以上)的互连线。在芯粒间,互连线尺寸一般在微米级,并且无法内插缓冲器,因此需要将高速通信的信号完整性作为主要约束条件。精确且快速的电磁场仿真对于满足集成芯片的信号完整性约束起到重要支撑作用。2.5D/3D 集成工艺引入的微凸点、TSV 结构具有复杂的寄生效应,对信号的影响难以用 RLC 集总电路模型准确评估。因此需要使用电磁场计算方法得到 S 参数模型。增强电场积分方程方法(Enhanced Electric Field Integral Equation,EFIE)是一种针对分层互连线结构进行电磁仿真的有效方法。根据互连线的几何模型,将互连线离散化为有限个小单元。通过对离散化的小单元应用增强电场积分方程,可以建立一个线性方程组描述电磁场和电流的关系,该方法可以通过数值或者解析的方法求解。求解得到电流分布后,再将电流分布与增强电场积分方程中的格林函数相乘,可以计算互连线上的电场分布。EFIE 方程可通过矩量法 (Method of Method,MoM) 和有限元法(Finite Element Method,FEM)求解。矩量法是基于积分形式麦克斯韦方程的频域求解方法,它主要求解金属表面的电流分布,然后根据格林函数计算空间中任意点的电磁场。矩量法的优点是计算速度快,消耗资源少,适合求解三维层状结构。矩量法的缺点是对非均匀介质和任意形状的结构求解效率低,精度受限于网格划分和格林函数选择,不适合求解大信号和非线性问题。相比之下,有限元等其基于微分形式麦克斯韦方程的频域求解方法,虽然可求解任意形状和材料的结构,精度高,但是计算速度慢,消耗资源多,需要对整个空间进行网格划分,不适合求解开放空间和时变问题。伴随集成芯片芯粒数和互连线数规模急剧增长,现有的电磁场 S 参数模型的提取效率低,严重拖慢了仿真速度,影响集成芯片的设计和迭代过程。同时,由于芯粒间互连线的约束条件为电磁场,因此由电磁场驱动的芯粒间互连线的版图自动化算法与 EDA 工具成为了集成芯片领域新的科学问题。在考虑仿真精度的前提下,缩短信号完整分析仿真时间的新算法是可以攻克上述问题的重要方向。除了互连线的自动化物理设计外, 3D 集成芯片的布局布线也迎来了新的机遇和挑战。在下图所示的平面芯片三维堆叠集成芯片的比较中,我们可以看到,在单芯片内长距离的全局连线可以被堆叠后的短距离的垂直线所替代。因此,堆叠后的短距离线较长距离线有望从毫米级缩小到百微米量级,显著提升互连线的负责和驱动功耗。然而,上述性能的提升是建立在高维度布局布线优化算法的基础上的。传统的布局布线优化方法,如模拟退火(Simulated Annealing),迷宫路由(Maze Routing)、遗传算法等还未从理论个上突破平面维度的限制。目前,三维堆叠芯片的布局布线 EDA工具仅支持粗粒度优化——将存储宏单元和逻辑宏单元分布在不同的芯粒上,根据最小化距离优化宏单元的布局布线。更细粒度的三维布局布线方法需要新更进一步的探索。
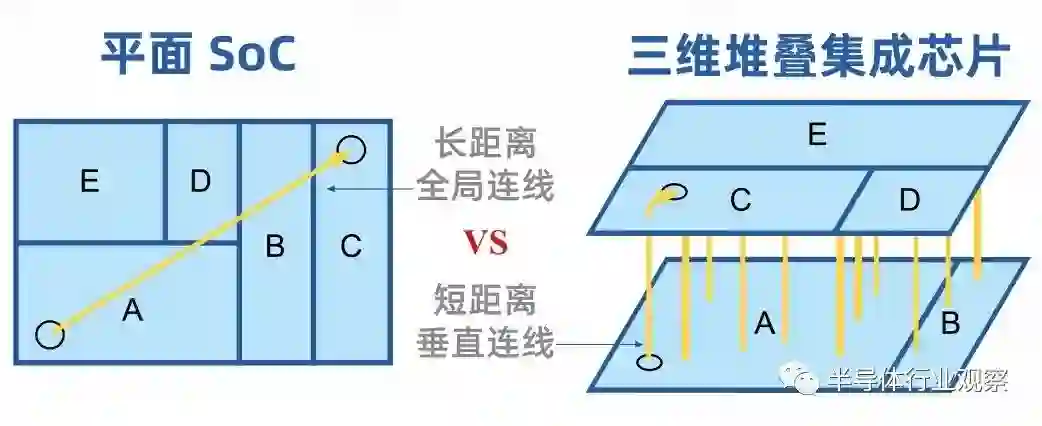
图 4.2 平面芯片与三维堆叠集成芯片的对比
4.3 芯粒尺度的电—热—力多场耦合仿真
随着集成电路的发展,芯片与系统越来越小型化、紧凑化,系统集成度也越来越高。面向未来集成芯片中大规模芯粒集成的需求,芯粒尺度的电 - 热 - 力多场耦合仿真也愈发重要。集成芯片集成非常复杂,需要协同考虑电磁场、热管理和机械应力耦合作用,并进行综合优化。芯粒尺度的多物理场仿真是揭示芯粒和集成芯片在多物理场(例如电磁、热、力场)同时耦合作用下,提高性能的有效手段。为了实现对芯粒尺度集成的高保真模拟,必须同时考虑具有多尺度、非线性场相关材料的特性和非线性界面条件的精细 3D 几何形状。如何构建芯粒尺度多物理场的基础理论及其准确仿真工具是集成芯片可制造性的重要挑战。
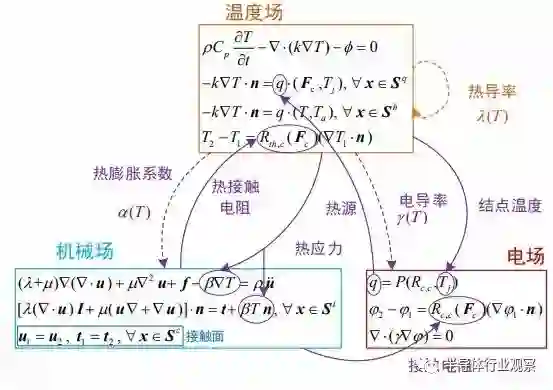
封装技术的发展推动着芯片系统向更高频率和更高功率发展。电路特征尺寸的不断减小和封装系统复杂性的增加(例如集成芯片技术),对封装设计提出了新的挑战,必须解决高频、高功率、应力变化条件下的电磁分布效应、热效应和力学效应问题。随着特征尺寸减小和功率增加,温度显著升高,尤其是在热点处,会降低电子封装的性能和使用寿命,并通过电迁移导致金属化失效。大的温度梯度和不匹配的热膨胀系数会产生诱导热应力,可能导致芯粒的机械故障,例如分层和剥离等。由于高温引起的材料电磁特性的变化会导致信号完整性和电源完整性问题,例如时钟偏移、意外压降以及滤波器和谐振器的频谱偏移。因此,需要一种基于电 - 热 - 力多物理场耦合的计算机辅助设计方法来同时解决电气问题和热问题。图 4.3 展示了用于分析集成芯片电 - 热 - 力多物理场耦合关系的示意图。建立足够准确和宽适用范围的多物理场耦合模型进行数值计算,是在激励或边界条件等真实工况下模拟芯粒尺度先进封装的基础。多物理场仿真中的关键问题包括由偏微分方程 (PDE) 或代数方程制定的多物理场耦合机制、考虑多个场强相互作用的材料本构关系模型、耦合 PDE 和传递机制的数值离散化以及有效求解复杂代数方程问题等 [66][67]。电 - 热 - 力多场耦合仿真技术的复杂性呈指数增长,对先进封装技术 [65]和相关的设计技术(如数值模拟)提出了更高的要求。在封装技术的设计过程中,包括材料参数、对象和布局尺寸的选择,尽早采用数值模拟方法进行探索和试错,可以显著降低试验成本。综上所述,随着集成电路技术的发展和芯片系统集成度的提升,面向集成芯片的可制造性需求,芯粒尺度的电 - 热 - 力多场耦合仿真技术愈发重要。多物理场仿真可以帮助评估芯粒设计性能参数、调查故障机制、提高可靠性并改进封装方法。多物理场耦合求解的主要问题和最终目标是实现稳定、可靠、快速和准确的数值计算。这种计算的前提是数学模型本身的清晰合理的发展,以及对物理过程基本原理的理解。为了提高模拟结果的准确性和可靠性,未来的研究重点包括先进的数值模拟优化算法和加速求解方法,开发更精确的材料模型,结合更全面的环境条件,通过实验验证实现对多物理场耦合效应的准确模拟。
4.4 集成芯片的可测性和测试集成芯片的可测性和测试技术相比传统芯片面临许多新的挑战。
集成芯片的制造良率需要考虑两部分:单颗芯粒自身的良率和多芯粒封装过程的良率。为保证集成芯片的良率,需要对每一颗芯粒进行缺陷测试,并对芯粒封装过程进行良率测试。如果存在缺陷的芯粒在基板上集成,或者封装过程中产生缺陷,整个集成芯片将无法实现预期功能。如图 4.4 所示,针对集成芯片测试,需要从单颗芯粒的测试技术和封装互连的测试技术两方面开展新的探索。针对单颗芯粒的测试技术,通过使用探针台结合单个芯粒的 DFT(Design for Testing)结构进行测试 [69]。为了提升集成芯片的良率,还需要进行 KGD(Known Good Die) 测试以及基板互连测试 [70]。由于芯粒种类繁多,不同芯粒可能采用不同的接口协议、不同的 I/O 管脚速率约束以及不同的植球方式,需要对芯粒测试提供一个最大公约测试集,基于该测试集标准,所有的芯粒生产厂商均应提供符合该标准的测试向量。针对封装互连的测试技术,由于集成芯片中包含大量的芯粒间并行传输总线结构,先进封装工艺的良率问题可能导致某些互连总线发生桥接 / 短路故障,或者导致信号偏移率过大,无法满足高速数据传输的时序要求。集成芯片先进封装与传统 PCB 板级封装有显著区别,一旦有互连线或互连部件发生故障,很难对其进行替换。因此需要研究并行传输总线结构的可测性设计和互连线层面的冗余设计,设计在线的互连线修复机制和数据传输协议修复机制。根据故障发生的模式,对数据发送和接收端口进行动态重配置,保证接口功能和时序的正确性。
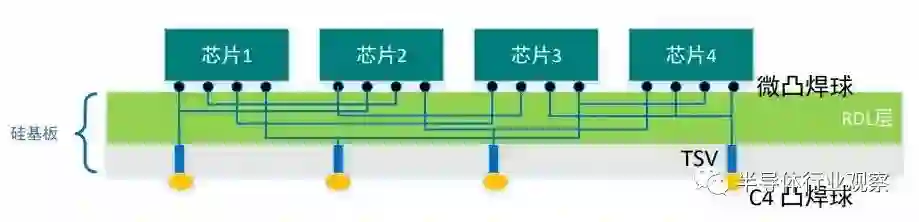
图 4.4 针对集成芯片的可测性,需要研究可测性设计结构将各个芯粒有效隔离,以提升集成芯片的鲁棒性。如果采用传统芯片菊花链式的可测性设计,一旦其中一个芯粒发生故障,整个可测性设计结构就无法正常工作,也无法准确定位缺陷位置。为此需要将关键信号或者线网直接连接到凸植球,并通过基板连接到封装的引脚,便于对这些关键信号进行测试和观察。此外需要对传统的可测性设计结构进行改进,增加芯粒级内部信号状态的可测性。例如对于时钟和复位等信号,需要设置单独的锁相环 DFT 结构,使内部寄存器状态可以在单独的锁相环驱动下进行外部输出。需要配置专门的模拟信号监测模块,用于监测各个芯粒内部的供电噪声和纹波。为了更有效地测试芯粒间互连故障,还需要研究类似 IEEE1149.1 标准的回环测试,将互连总线两端的芯粒进行配对,形成回环,对数据发送端和接收端进行单独测试,更有效地定位互连总线故障。在生产制造环节的测试之外,针对集成芯片整个生命周期的工作状态检测和可靠性也是亟待解决的关键问题。需要研究集成芯片生命周期管理技术,例如在芯粒内部或基板上配置传感器,对器件参数偏移、供电电压以及环境温度进行监测,并根据芯粒的工况和老化情况进行新的协议或时序配置,延长集成芯片的使用寿命。探索利用 DFT 中的冗余设计,对某些芯粒或互连线老化效应超过阈值的部分进行替换或修复。相比无源硅基板,有源基板能够实现更高的灵活性和可扩展性。如何对基于有源基板的集成芯片进行测试和可测性设计成为新的问题。由传统的 JTAG 测试结构扩展的 IJTAG 1687 可以用于有源基板集成芯片的层次化测试。通过对 TAP 控制器的重配置,可以将每个芯粒配置成旁路模式或者测试模式。根据测试时机不同,IJTAG 测试标准可以用于芯粒封装前的绑定前测试,封装过程中的绑定中测试,以及封装完成之后的绑定后测试。综上所述,集成芯片的可测性和测试技术对提升集成芯片制造良率、定位缺陷位置、提升集成芯片可靠性具有重要意义。需要研究面向集成芯片的最大公约芯粒测试集、互连线冗余和协议修复机制、可测试性结构设计、全生命周期管理、有源硅基板测试等关键技术,实现缺陷的快速检测、替换或修复,提升集成芯片制造良率并降低制造成本。 5、集成芯片的工艺原理****5.1 RDL/ 硅基板(Interposer)制造工艺与传统封装基板(Substrate)级 2D 互联相比,集成芯片工艺引入了铜互连工艺等芯片制造技术,也因此形成了一些新形态,新功能的芯粒。其中,最具有代表性的就是2.5D集成中硅基板(Interposer)。图 5.1 展示了利用硅通孔 (Through Silicon Via, TSV) 技术实现的,基于硅基板的 2.5D 封装集成芯片结构。 
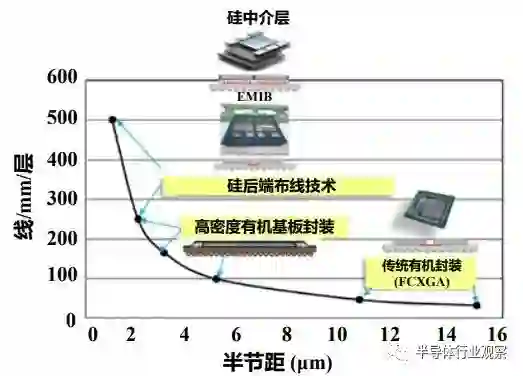
硅基板与上层芯粒、底层封装基板通过微凸点(Micro-bump)和 C4 凸点(C4 bump)实现电信号连接。Interposer 可以用于提高芯片的性能和带宽,使芯片更加紧凑。芯粒间的互连线是在硅基板上的多层铜互连金属工艺实现,因此可以实现微米级的间距布线。当工艺设备受限时,也可以采用重分布层(Redistribution Layer,RDL)工艺取代铜互连工艺,实现较高密度互连。硅通孔(TSV)是硅基板工艺相比一般 CMOS 芯片工艺新增的工艺。TSV 的制造工艺是通过激光钻孔或深反应离子刻蚀(Deep Reactive Ion Etching,DRIE)在硅基片上形成垂直穿孔结构。这些孔可穿透多个层次,连接不同的电路层,然后进行衬底沉积(通常是一层绝缘材料,如二氧化硅),以提供电隔离和机械支撑。再通过物理蒸镀或电化学填充等技术,在 TSV 孔中沉积导电金属(如铜),以建立电连接。最后,使用化学机械抛光(Chemical Mechanical Planarization,CMP)等技术,将金属填充的表面与基片表面平坦化,以便后道工续。由于 TSV 的深度一般小于硅片的厚度,还要将硅基板减薄后才能将 TSV 露头。为了保证高性能芯片的电源完整性,在硅基板中还会制造高深宽比、高电容密度的的深槽电容(Deep Trench Capacitor,DTC)用于对电源的退耦。其原理是,在硅槽中一个顶部电极层和一个底部电极层之间填充电容高介电常数材料,通过将深沟槽(DT)蚀刻到硅衬底中而形成三维垂直电容器。DTC 的电容密度为 300nF/mm2。不难发现,在 2.5D 集成芯片中,硅基板的面积决定了集成芯片的面积。因此,突破硅基板的面积上限是一项重要的挑战。台积电对未来的硅基板面积扩大已制定了明确的技术规划。一般地,单芯片制造的最大面积上限由光刻机的光罩尺寸(reticle)决定,如何实现超过 3-4 个光罩尺寸的硅基板是一项重要的课题。

图 5.2 TSMC 对硅基板面积的技术路线图
在大尺寸硅基板的制造上,仍然存在这多个科学问题有待攻克。最具代表性的翘曲与应力建模。由于 TSV 的深度一般小于硅片的厚度,因此需要将硅基板减薄到 100 微米以下,此时大面积硅基板易发生翘曲,甚至断裂。建立合理的应力模型,准确预测在包含 TSV、DTC 等工艺后晶圆的翘曲程度将有助于突破硅基板的面积上限。但这一模型的科学基础需要力学、工程材料领域的交叉研究。此外,多次曝光 / 拼接缝合(stiching)技术、高密度高深宽比的 TSV 工艺也是硅基板制造中的难题。5.2 高密度凸点键合和集成工艺“一代芯片需要一代封装”,目前半导体先进制程纷纷迈入了 7nm、5nm,开始朝 3nm 和 2nm迈进,晶体管尺寸不断接近物理极限,先进制程的持续微缩难度越来越高,迫切的需求刺激业界寻求新的解决方案,封装集成的重要性不断显著。在集成芯片中,互连密度已由传统的百微米级节距演进至微米级节距,并快速向亚微米级节距发展。针对大规模芯粒及封装结构高度复杂、高密度互连和超高密度键合,其封装设计中缺陷预测与抑制难度激增,亟需研究高密度高可靠凸点键合和集成工艺。
在三维空间内,芯片 / 芯粒间互连可分为三类:(1)芯粒表面与外界的垂直互连通道,包括传统的凸点、微凸点和新兴的混合键合互连界面;(2)芯粒间水平互连导线,主要指基板或重布线层的导线阵列;(3)芯粒内部的垂直通孔结构,即硅通孔,主要实现多层芯粒堆叠中的互连。如图 5.3所示,随着系统性能对互连密度要求的不断提高,不仅传统二维平面内互连线节距不断微缩,而且穿过芯粒内部的硅通孔垂直连接也应运而生。三种互连共同组成了先进封装中的三维互连网络。在快速发展的先进封装技术中,上述三类互连结构都在快速微缩。后两类互连,互连导线和硅通孔节距已经进入了 10 微米以下。在第一类互连中,传统的凸点键合方式已逼近 10 微米的物理极限。混合键合可有效突破 10 微米极限,向亚微米级节距进行快速微缩。当前比利时 imec 研究所已实现 0.8 微米混合键合技术的成功研发,美国 Intel 公司已实现面向量产的 3 微米节距混合键合技术的验证。混合键合技术是将两片需要键合在一起的晶圆,各自完成制程最后一步的金属连线层并实现熔合键合,此层上只有两种材质:铜及介电质。与凸点键合相比,混合键合具有结构、材料上根本的革新,并带来显著的性能优势:(1)采用内嵌式超平表面铜接口,避免了键合对准过程中接口倒塌变形、键合空洞及相应失效风险;(2)采用预填充式无机介电层,相比于传统有机底填料,显著提高了热稳定性。因此,混合键合不仅可以支撑互连节距向亚微米节距持续微缩,且对于封装系统整体的电性能和热机械性能具有显著提升作用 [73]。但是,实现混合键合对于工艺和材料提出了新的挑战,需要传统的晶圆制造企业和封装企业紧密协同,研发新型专用工艺。挑战包括:(1)从当前芯片后道工艺(BEoL)大马士革工艺出发,制造适合混合键合的顶部金属 - 介电层,保证高键合强度;(2)开发面向混合键合的高精度高洁净度划片技术,保证键合前后芯片边缘无崩边、隐裂;(3)控制晶圆整体翘曲和表面平整度,实现整片晶圆或芯片的无空洞完整键合。高密度凸点键合和集成工艺是在系统集成密度、系统的复杂程度以及元件的集成度提高需求下带来的的先进封装技术需求。其工艺相对简单,集成密度高,能够同时实现电学连接和物理支撑,是集成芯片先进封装领域研究和发展的重点。为了实现高密度凸点键合和集成工艺,仍然需要大量研究工作,包括优化设计和工艺参数,提高晶圆对准精度,实现低温退火以及降低成本等。随着集成芯片的发展,芯粒集成度(种类和数量)不断提升的需求将进一步推动先进封装和集成工艺的发展,进一步缩小互连节距,提升互连密度和互连带宽。
**5.3 **基于半导体精密制造的散热工艺
高性能、高集成度已成为现代电子芯片的发展趋势,超高功率芯粒的高密度异质异构集成将导致其热耗和热流密度急剧攀升,给芯粒集成芯片热管理提出了重大挑战。在高运行温度下,芯片内各种轻微物理缺陷造成的故障更容易显现出来,高温会使芯片内延时增加,降低 CPU 的工作效率。同时,随着芯片温度升高,芯片漏电流增大,由于 IR Drop 导致工作电压降低,容易出现可靠性降低甚至失效的问题。芯片热管理技术路线主要可分为以下三个阶段 [75](如图 5.4 所示):第一阶段主要采用逐层散热的方法,芯片封装外壳下方是基板,基板下方布置微通道热沉冷板,各界面间涂覆热界面材料,散热能力可达 200 W/cm²。第二阶段将组件壳体集成于流道侧面,冷却液直接进入组件壳体,传热路径为芯片→热沉→组件壳体,减少了传热环节,消除了组件与冷板之间的接触热阻和冷板热阻,热流密度可提升至 500 W/cm²。第三阶段,近结点冷却技术,它采用高效对流 - 蒸发传热特性的微通道直接集成到基底材料内部或非常靠近发热元件以实现高效散热,并集成微泵、微传感器和微换热器等微热控元件,实现芯片一体化闭式废热排散的冷却循环,如图 5.5 所示。近结点冷却通过引入微纳工艺,大幅减小了散热过程中的传热路径和环节,散热能力可达 1000 W/cm²以上 [76][77]。 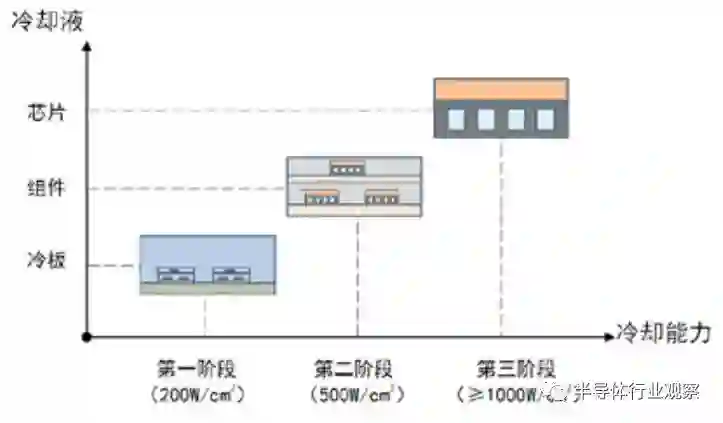
集成芯片的功率未来将达到数 kW 甚至十几 kW,芯片热流密度将超过数百 W/cm²,芯片热点的热流密度将突破 kW/cm²量级。近结点微通道散热技术将是重要的技术发展方向,不仅可以实现高热流密度芯片的高效散热,突破芯片热耗墙,同时还可以将热管理系统微型化,集成到芯粒芯片中,大幅提升芯片集成化程度。在工艺实现上,目前微通道散热技术主要有两种方案,如图 5.5 所示:图 5.5(a)给出了转接板集成微通道的近结点微通道散热系统架构,图 5.5(b)给出了晶圆级集成微通道的近结点微通道散热系统架构。转接板集成微通道的散热架构集成封装更为简单,无需对 Die( 裸片 )进行调整,但是其散热性能相对有限;而晶圆级集成微通道的近结点散热系统架构,冷却工质直接引入到 Die 的背面,散热通道与热源的距离从 mm 级缩小至 μm 级,散热性能极大提升,但是其集成封装较为复杂,需要在 Die 设计时就要考虑微流道结构设计。 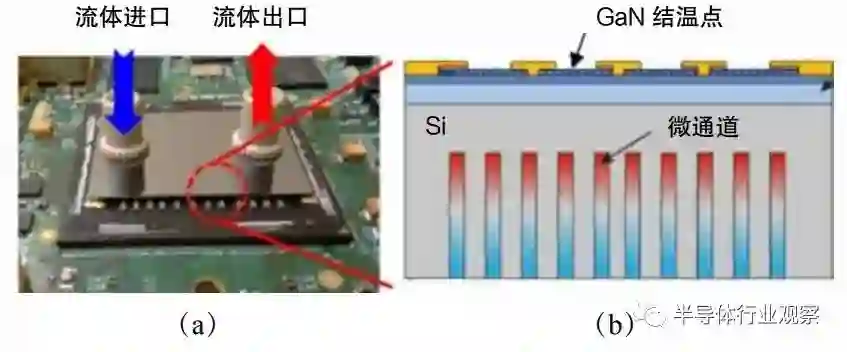
与传统的热沉冷板技术相比,上述两种技术架构不仅需要综合考虑材料的导热能力、热膨胀特性、电学特性和材料的加工制造能力等因素,以实现流-固-热-力-电的良好兼容,而且芯片上元件众多,材料属性差异显著,往往还需在芯片级集成微阀、连接管道等部件,三维堆叠芯片内的流体与电学连接更加复杂,亟待突破近结点微通道设计优化与强化换热方法、多层异质界面封装集成方法、芯粒集成芯片热 - 电 - 力 - 流一体化协同设计等关键技术。
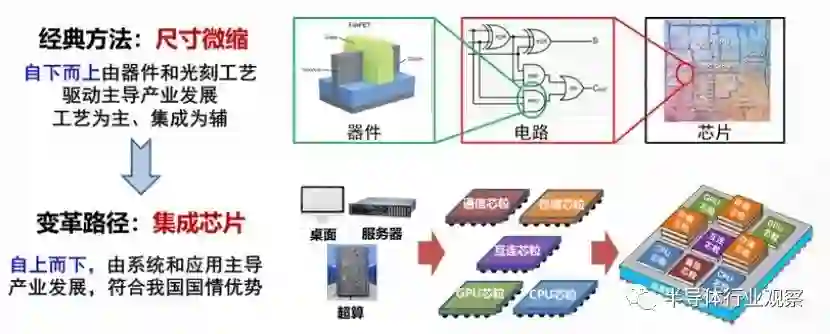
6、白皮书观点:集成芯片的机遇与挑战****6.1从堆叠法到构造法的集成芯片,是符合我国国情和产业现状的一条现实发展道路在摩尔定律尺寸微缩的经典路径指导下,当前集成电路设计采用自下而上的堆叠法,核心是基础器件与制造工艺。如图 6.1,芯片设计是基于 EDA 工具,将器件集成到电路,再发展到完整芯片的过程。随着经典摩尔定律的发展路径,芯片规模和集成度不断提升,工艺主导的行业局面越来越凸显,国外持续向“尺寸微缩”注力,为延续光刻机、EDA 等关键瓶颈提供技术保障,以此来控制整个产业链。因此,国外集成芯片发展路径,仍然是一条工艺为主、集成为辅的发展路径。例如苹果最新的M1 Ultra 芯片,利用 5nm 的先进制造技术,进行了两个芯粒的集成,促成了高性能新产品的发布。
与自下而上的堆叠法不同,集成芯片采用自上而下的构造法这一可行的发展路线。面向集成度进一步提升的集成芯片设计,构造法从整体系统的角度出发,自上而下研究芯粒的分解与组合优化理论。为了对应芯粒构件这一新层次,如图 6.2 所示。参考物理、化学、生物等学科,除了微观、宏观理论,也部署了介观理论。介观理论对集成芯片的构造法研究具有重要意义。芯片的介观形态是区别于微观的晶体管 / 基础部件、宏观的集成芯片 / 系统芯片的中间形态,介观更多表现在芯粒、IP 层次。从功能描述来看,微观的布尔逻辑、宏观的复杂系统都已经有扎实的数学基础和物理描述;从设计方法学角度来看,逻辑门综合、高层次系统综合已能对芯片的微观和宏观进行描述。而在芯片介观形态和构造上,都缺乏相应的数学、物理基础,在设计方法学、体系结构以及制造工艺等都存在科学与技术挑战。自上而下的构造法能够通过介观芯粒解耦,实现应用 - 集成 - 设计 - 工艺协同,从系统和应用需求出发,依靠自上而下的方法学,可以发展出费效比低的系统。
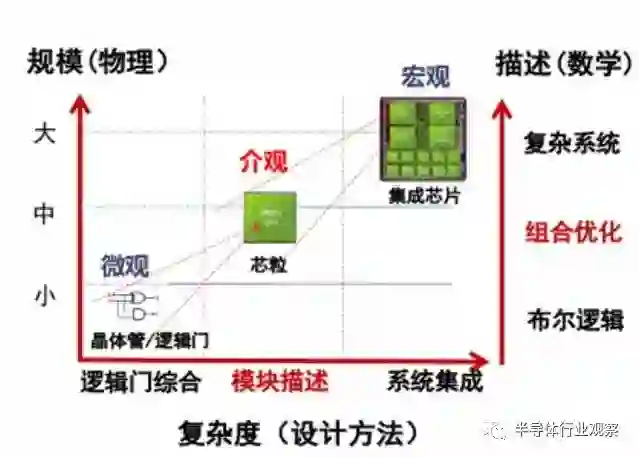
图 6.2 集成芯片的介观理论
采用构造法设计集成芯片是符合我国国情和当前产业现状的一条现实发展道路。从中短期来看,中国集成电路产业无法在短时间内破解 EUV 光刻机瓶颈,实现 7nm 以下自主制造工艺难度很大。我国的产业优势在于庞大的市场规模,集成芯片技术可以基本满足我国的中短期需求,并利用大规模的市场需求来刺激技术进步,同时带动其它路径发展。市场规模庞大带来的另外一个特点是应用需求的种类多、碎片化,传统的芯片设计制造成本高,无法满足种类繁多的应用需求。而集成芯片可以利用其模块化的芯粒复用技术,大幅降低成本,从而满足更多行业的芯片需求。同时,从整个集成电路的产业链来看,我国在封装测试环节占据一定的比例,具有一定的产业优势。对我国而言,依托庞大的市场需求和领先的先进封装产业,以集成为主的构造法方案可基于国内现有产业链实现高性能芯片,技术上可行且能解决当下的市场需求。自上而下的构造法是一条由系统和应用主导产业发展的集成芯片发展新路径,符合我国国情和当前产业特点。6.2 集成芯片的三大科学问题与十大技术难题集成芯片的发展仍处于初级阶段,目前国内外的商业化集成芯片产品普遍面临集成度低的问题,如芯粒数量一般少于 10 个、芯粒种类少于 5 种,远远未能发挥该设计应有的性能优势。我们认为:集成芯片的集成度(种类和规模)的提升,是推动集成芯片技术体系的主要驱动力量。集成度的大幅提升,将引发从芯片设计方法学、体系结构、仿真工具到底层工艺制备等一系列的科学问题。**科学问题一:**芯粒的数学描述和组合优化理论。面向分解中的数学问题,目的是解决如何将复杂的功能需求,分解并映射到大规模的芯粒构件上。在少量芯粒集成时,映射关系较为简洁,而将复杂功能分解到大量芯粒时,则需要借助数学运算来完成和优化。传统集成电路针对微观晶体管的数学描述并不适用于芯粒尺度,因此亟需建立新的数学理论。传统集成电路设计依靠的布尔代数、符号逻辑等方法,不适用于介观尺度的芯粒功能分解。这一理论不是简单的 Top-Down 的宏观系统拆分方法的迁移,需要探究应用场景下芯粒的抽象表达,为大规模集成芯片的分解提供理论基础。**科学问题二:**大规模芯粒并行架构和设计自动化。面向芯粒组合并行挑战的信息科学问题,解决随着芯粒的数量和种类大幅提升,怎样应对芯片设计复杂度的爆炸式增长问题。需要设计超越多核架构的高并行效率新架构,充分释放芯粒组合并行的算力潜能,破解阿梅达尔定律和计算 - 通信屋顶曲线模型等带来的扩展性和并行极限难题。另一方面,少量芯粒集成时由于涉及的芯粒种类少、复用率低、空间维度小,现有 EDA 工具主要用于以晶体管为单元的二维电路设计,无法辅助以芯粒为单元的三维布局开发。因此需要突破芯粒层面的设计语言和综合问题,探索新布局布线方法,形成集成芯片 EDA 新工具,大幅降低集成芯片设计周期。**科学问题三:**芯粒尺度的热力电多场耦合机制与界面理论。面向集成挑战的物理科学问题,目的是解决不同功能和种类的芯粒在形成界面时,如何优化热、电传导,避免应力破坏等问题。大规模芯粒集成将扩展到三维空间,多层堆叠结构带来了复杂界面的物理量传导耦合问题。集成芯片需要准确预测系统在多物理场中运行状态,特别是电磁场、热和应力翘曲,并在跨尺度下形成较为完整的研究体系。然而,现有的宏观结构力学、工程热学与量子器件的微观表面力学等理论缺乏深层次耦合交互。以热仿真为例,微观层面上在器件、量子尺度的热仿真理论采用波尔茨曼输运理论等,宏观层面上在大封装尺度的热理论采用热传导、扩散方程等,在芯粒尺度的热界面理论不完善;在集成芯片须明晰多芯粒系统中的电磁、热和应力的相互作用,探索跨尺度的多物理场交互的仿真方法与工具。在以上集成芯片的科学问题基础上,集成芯片前沿技术科学基础专家组进一步提出十大技术难题(2023 版),见下图,希望这些问题能为集成芯片的发展起到牵引作用。

