导读 随着以 ChatGPT 为代表的大模型技术的迅速发展,推荐系统正经历着一场革命性的变革。传统的推荐系统主要基于用户和物品的历史行为数据进行预测,大模型技术的出现,为推荐系统带来了更强的泛化能力和更高的效率,解决了传统推荐系统中的一些难题,如用户和物品数量的巨大规模、不可观测因素对推荐的影响等。同时,大模型推荐技术也带来了新的挑战,如模型的可解释性和隐私保护等问题。
今天的介绍将会从以下四个方面展开:
- 推荐及 LLM 简介
- LLM 赋能推荐系统
- 大模型推荐展望
- 总结 分享嘉宾|冯福利 中国科学技术大学 特任教授 编辑整理|普衍钧 内容校对|李瑶 出品社区|DataFun
01
**推荐及 **LLM 简介首先整体介绍一下推荐系统和大模型技术。1. 推荐方法的本质

推荐系统广泛应用于短视频、电商等各类互联网产品中。推荐方法的本质是**拟合历史用户行为数据,预测未来用户行为。**推荐系统是过去 10 年中 AI 落地最成功的案例,但是在工业场景中,传统的推荐系统依然存在很多问题。
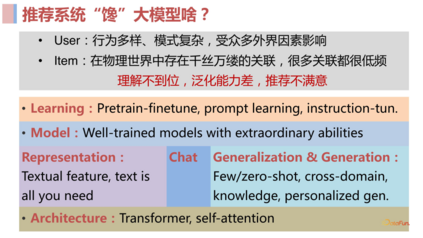
- 用户层面(user):用户规模大(数以亿计),用户行为多样(千人千面),且受到很多推荐系统不可观测的外界因素影响,导致建模十分困难。
- 物料层面(item):item 之间的很多关联是十分小众的,不易被捕获(共现频次低)。为什么这个用户会同时购买这两个东西,为什么这个用户会同时看这两个视频等等问题,可能是因为非常小众的原因关联起来的,对建模也是一项挑战。
- 模型层面:存在很大的泛化问题,我们所熟知的很多平台例如 TikTok,用户每天新上传大量视频,产生非常多的新的低频关联和新的 item,模型可能对新的 item 推荐效果不佳,泛化问题对于主要依靠 id 特征的传统推荐系统而言是困扰多年的严重问题。
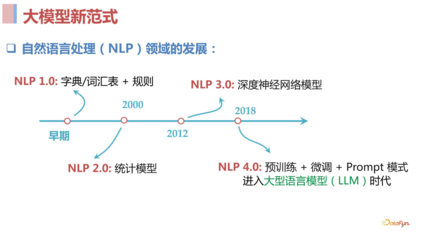
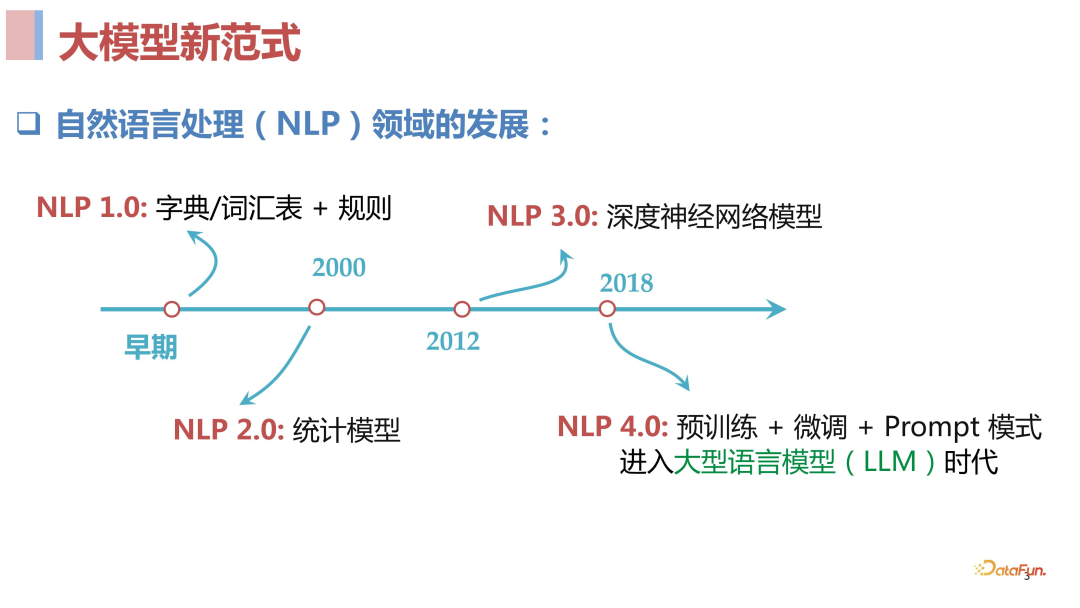
**2. ****大模型技术(**NLP 新范式)
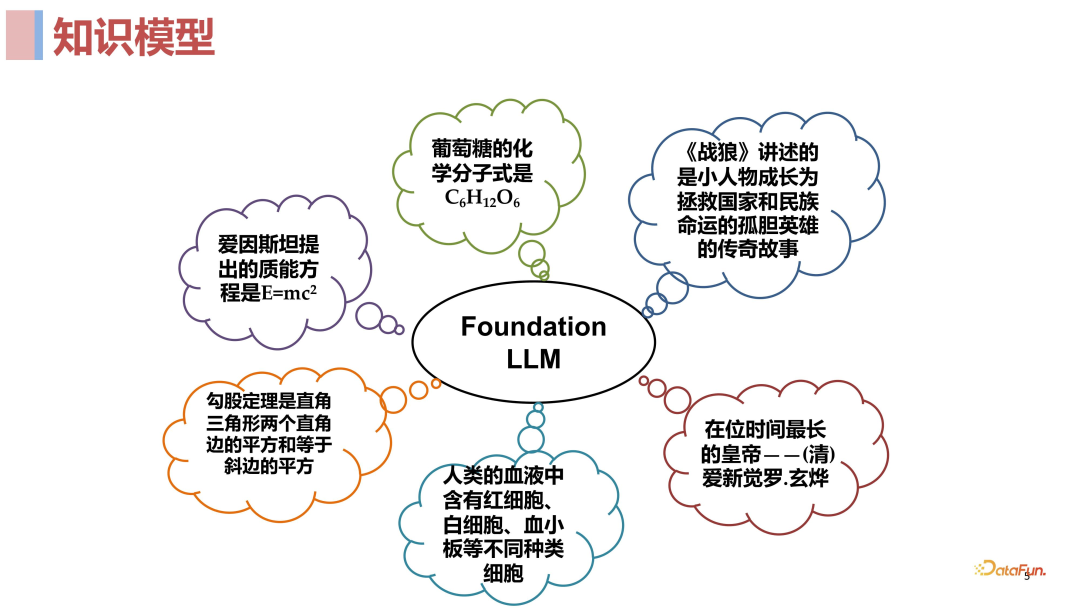
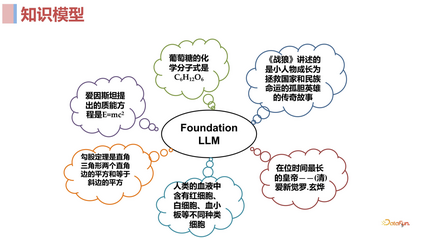
有人认为大语言模型不只是一个语言模型,更是一个知识模型,因为大语言模型使用了非常多的语料去做预训练,相当于 encode 了非常多的知识。虽然不像传统的知识图谱显式的把知识结构化表达出来,但它很可能通过模型中某些参数将预训练语料中的知识很好的 encode 进去了。当然有些知识可能 encode 的不是非常好,但我们目前能看到的事实是在 NLP 领域,大模型已经是处于绝对优势,在各种任务上都表现惊人。3. 推荐系统“馋”大模型什么?****
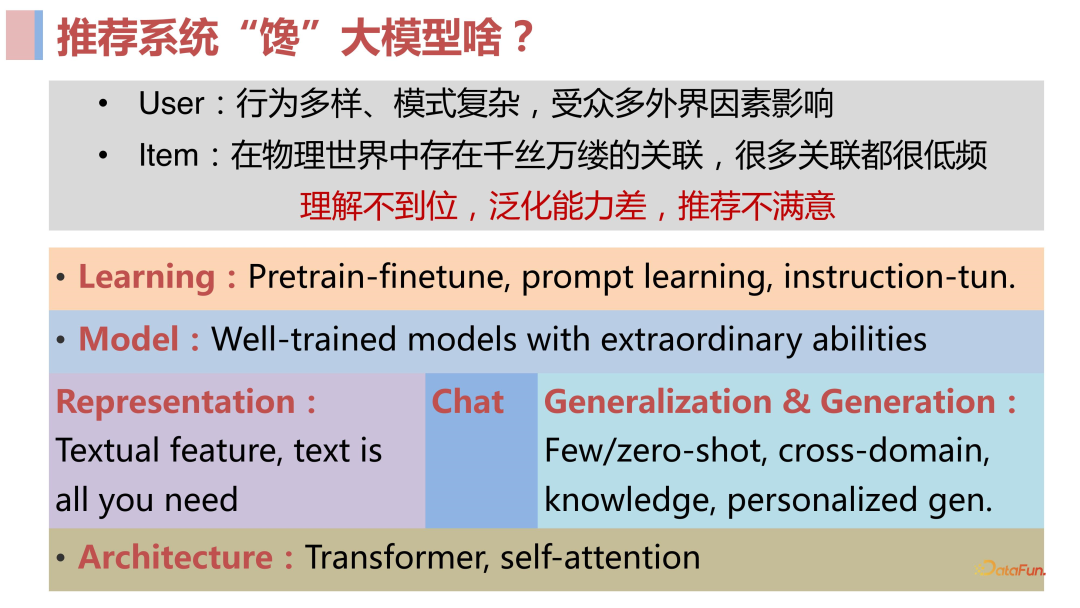
- **强大的建模能力:**第一眼看大语言模型能力强,很可能归功于大预言模型使用的 Transformer 这样的模型结构本身具备很强大的建模能力,受其启发我们可以基于它去做一些推荐模型,提升推荐模型的建模能力。
- **优秀的学习范式:**除了模型结构的强大建模能力,大语言模型预训练+微调+prompt 这样的学习范式也具备很大的优势,能够帮助训练出优秀的模型。我们也可以将其应用于推荐领域中,从而学习到更强大的推荐模型。
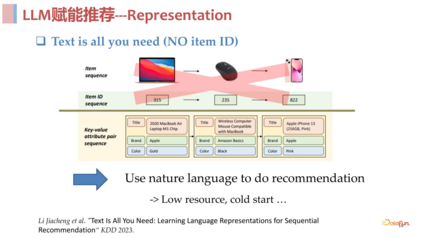
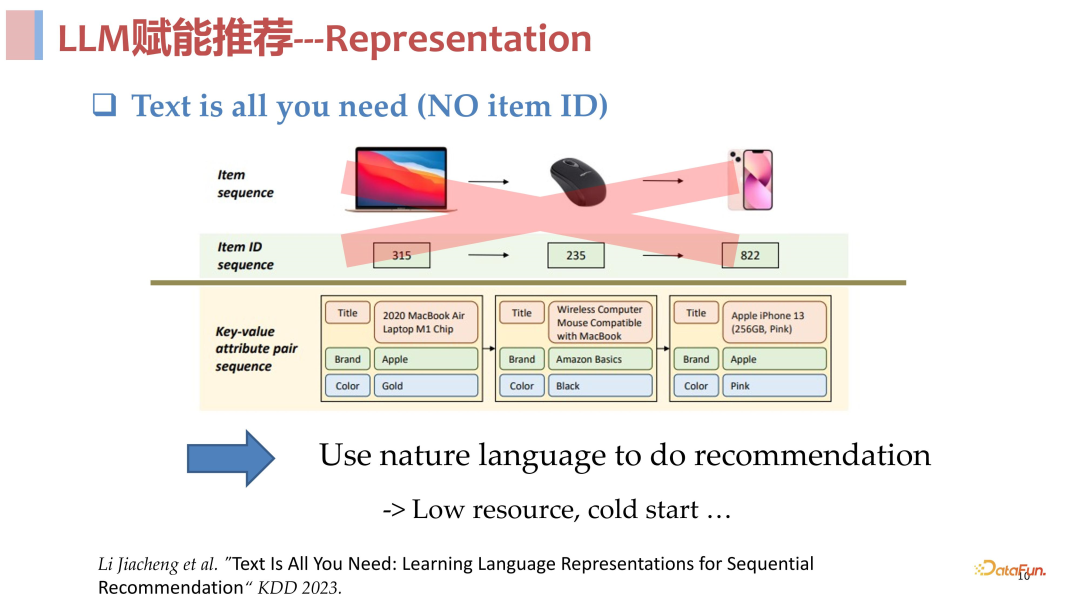
- **Well-train ****的大模型本身:**无论是 ChatGPT 这样通过 API 访问的闭源模型,还是 Llama 这样可以拿到完整参数的开源模型,都已经表现出了非常强大的能力。如果我们能够将这些 well-train 的大模型引入到推荐系统中来,也许能够获得很好的推荐效果。**将模型直接应用到合适的场景:**比如 ChatGPT 刚问世时,其 chat 能力是大家公认的第一个非常惊艳的公开系统,对于做 conversational recommendation 的人来说,这就是一个非常诱人的能力。**使用大模型去做 ********item ****的理解和表征(去 ******ID ****化):无论是 ChatGPT 还是其前后出现的大语言模型,它们都具备强大的文本表征和理解能力,我们能否将这两种能力引入到推荐系统中来呢?当然是可以的,推荐场景中本来就具备很多的特征,比如商品的 title 和各种文本描述。除此之外,前文提到推荐系统中新 item 的问题是很棘手的,因为传统的推荐系统都是主要基于 ID 的,也就是每个新来的 item 都必须有一个 ID,然后根据这个 ID 去学习 item 的表征,最后通过学习到的表征去做推荐。但是如果存在一个通用模型能够把语言理解的非常好,那是否可以直接用语言去描述 item,去掉 ID,直接得到 item 描述的文本表征作为 item 的表征?
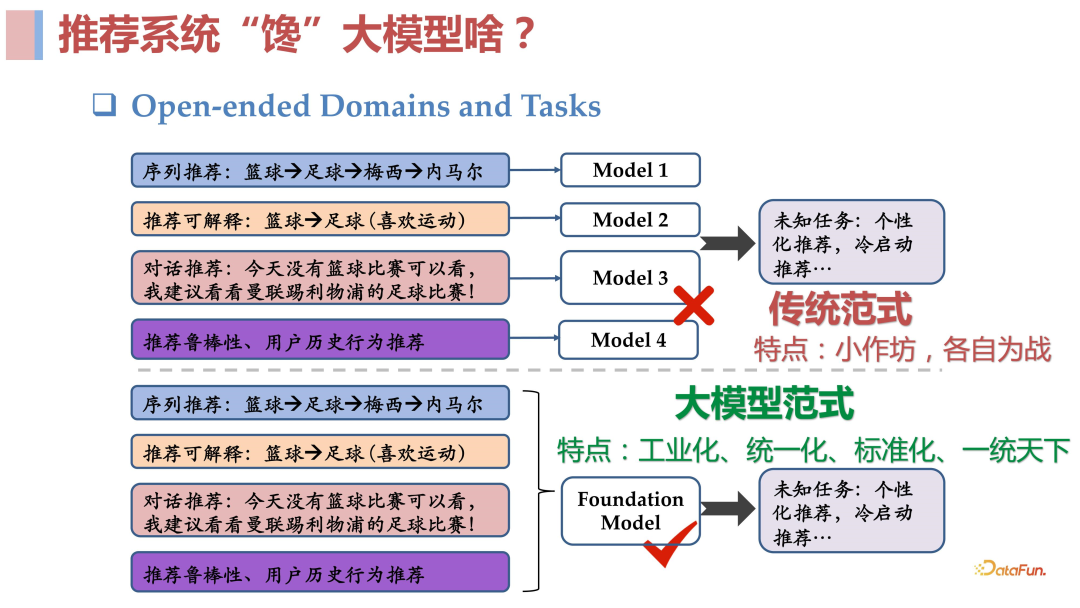
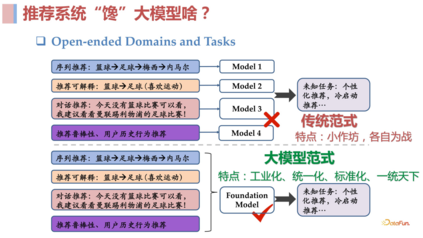
- 建立推荐大模型范式:在 NLP 领域,自从 18 年 BERT 出来之后,NLP 这件事就变得容易了很多,我们可以通过 fine-tune 的方式去解决不同场景下的任务。后来出现了 Instruction GPT,我们甚至都不需要去 fine-tune 了,基于此类强大的基础模型,只需要去写 prompt 就可以完成任务。对于推荐领域,我们依旧处于对不同场景的任务去构建和优化不同模型的阶段,与 NLP 领域的任务 solution 生产速度相对比,完全不在一个量级上,可以说是工业文明和农耕文明的巨大区别。那么我们是不是也可以在推荐领域去建造这样的强大的基础模型,在未来让推荐也可能进入一个工业化、标准化的时代呢?过去两三年在这一领域中开展了很多工作,可以总结为以下几点:
使用文本统一表示,解决依赖 ID 的问题,这样就可以忽略 cross domain 和 costar 这样的问题,包括很多长尾问题也能得到很好的解决。使用**prompt **统一任务,这样就可以做到 open ending task,使用训练好的语言模型去做到跨域,最终得到一个 open ending task and domains 的基础模型。 02
 使用文本统一表示,解决依赖 ID 的问题,这样就可以忽略 cross domain 和 costar 这样的问题,包括很多长尾问题也能得到很好的解决。使用**prompt **统一任务,这样就可以做到 open ending task,使用训练好的语言模型去做到跨域,最终得到一个 open ending task and domains 的基础模型。 02
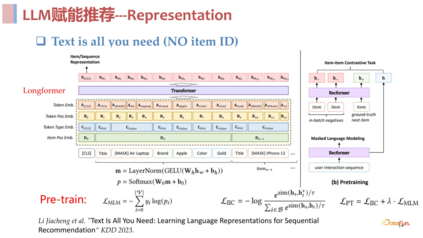
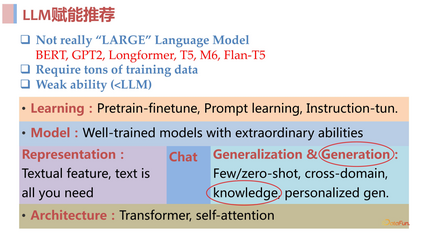
使用文本统一表示,解决依赖 ID 的问题,这样就可以忽略 cross domain 和 costar 这样的问题,包括很多长尾问题也能得到很好的解决。使用**prompt **统一任务,这样就可以做到 open ending task,使用训练好的语言模型去做到跨域,最终得到一个 open ending task and domains 的基础模型。 02LLM 赋能推荐系统这一部分将会介绍 LLM 赋能推荐在 Representation、Learning 和Generalization 领域中比较靠前和有代表性的工作。1. Representation 方面

**2. ****Prompt learning 方面
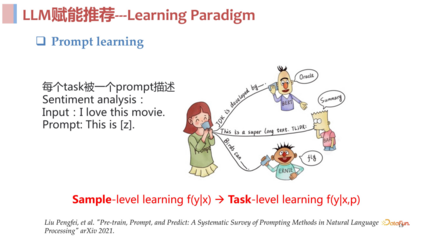
Prompt learning 的思想非常的简单朴素,就是对每一个任务使用一个 prompt 去进行描述。以情感分析任务为例,过去我们做此类任务的方式是对输入的文本去做一个分类任务,预测它情感的正向或者负向,更多的是一种判别式的方法。而现在,有一个 input,使用 prompt 去对情感分析任务进行描述,让模型去解码生成一个结果,通过这个生成的结果去判断情感的正负倾向。总结来说 prompt learning 的核心思想就是构造 prompt 去描述任务,使用生成式模型去生成任务结果。
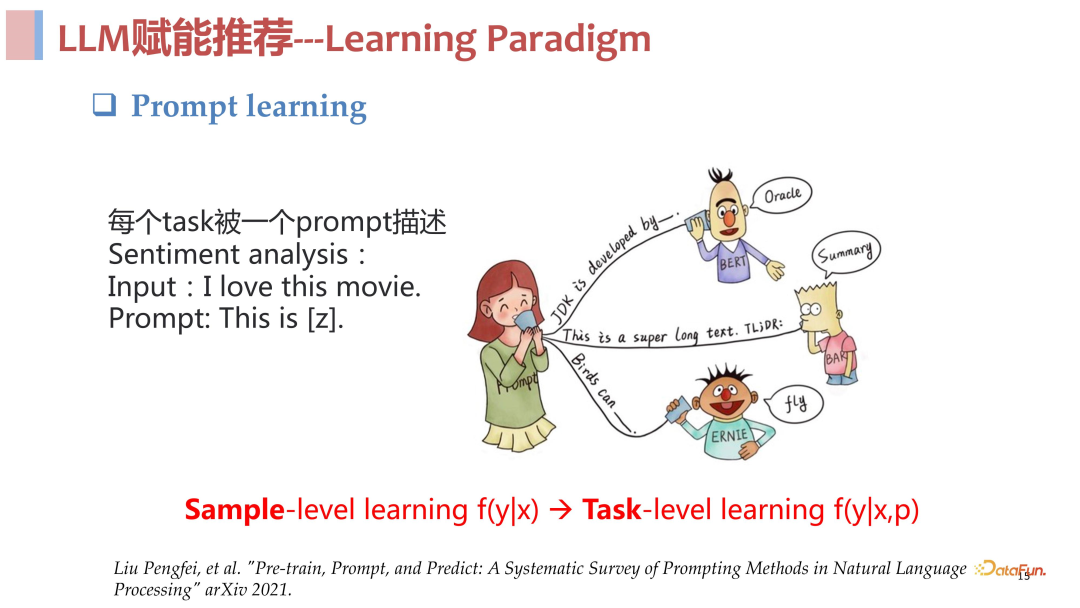
Prompt learning 的优势在于,实现了从样本层面的学习到任务层面的学习的提升跨域。过去无论是有监督学习、无监督学习还是对比学习,都是在样本层面上的学习。有了 prompt learning,用于建模的除了样本以外,还有了 prompt 这样一个描述任务的额外输入,这样使得模型的学习变成了一个任务层面的学习,相对样本层面的学习是一个具备更高抽象层次的学习,所以这一学习范式更具优势。
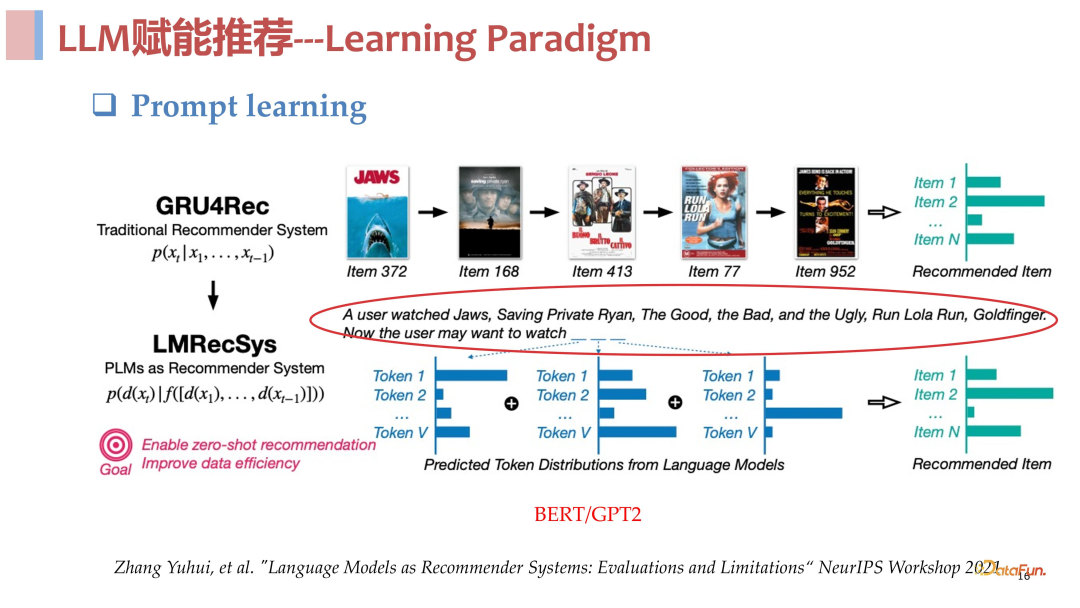
Prompt learning 一经推出,即受到了推荐领域工作者的关注,在 21 年的 NIPS上就有了一个这样的工作,尝试将推荐任务写成 prompt 格式,去研究其是否具备优势,下面做一些简要的介绍。对于基于序列建模的推荐,就是输入用户历史访问的 item 序列 id 的 list,去预测下一个推荐的 item。该工作的核心思想是将这个 item id 的序列用语言描述出来,input 就是用户历史看了哪些电影,prompt 就是现在用户会想看什么电影,然后用一个预训练好的模型去做 decode,看它会生成什么推荐的电影。文章中对于具体如何 decode 生成 item 的过程没有很清楚的描述,但其引领了这一方向的工作。

接下来介绍的工作是杨红霞老师在阿里时候所做的 M6-Rec,这个工作结合了上述两种优势,既使用了文本去表示 item 和用户交互序列的去 ID 化,也使用了 prompt learning 的方式。架构上使用了阿里内部的 M6 模型架构,是一个类似与 T5 模型的既要理解能力又要生成能力的模型架构,前面是一个类似 Bert 的双向神经网络,目的是增强理解能力,后面是一个类似 GPT 的自回归的结构,与 GPT 不同的是它不是主要为了生成 token。

它将推荐中的许多任务都用 prompt 描述了一遍,比如将 CTR 任务这类的 scoring task,都写成了一个 prompt 模版。这个模版主要分成两块,第一块是特征描述,用特殊的 token 去包裹用户的画像特征以及交互历史这些信息,第二块是描述现在想要对这个用户推荐一些候选的 item。将上述构造好的 prompt 输入模型,接下来就能对候选的 item 进行打分,打分的思路非常简单,模型会根据输入的 prompt 去生成一个特殊的 token,然后得到这个 token 的表征,用这个表征去做 decode 就得到 y=1 或者 y=0 的概率。当然这个工作也把推荐中很多其他任务,比如生成任务,都写成了不同的 prompt,是这个方向早期比较有代表性的工作。
3. ChatGPT 时代的工作
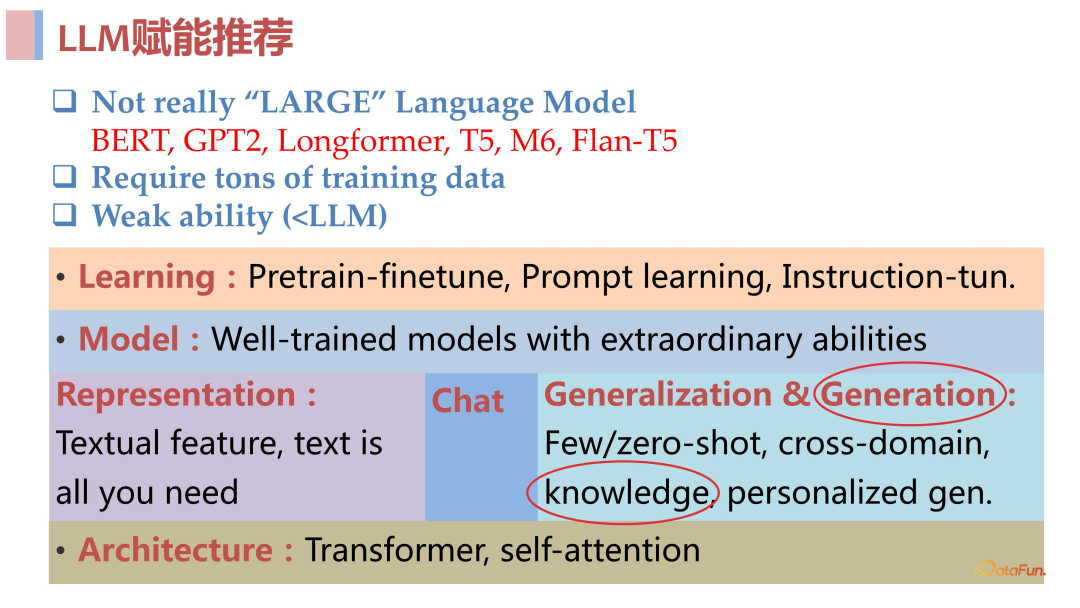
前面介绍的都是 ChatGPT 之前的一些工作,用的模型主要是 Bert、GPT2、Long-Former、M6 这类模型。这些工作的优缺总结如下:优点:主要是将大模型领域的一些先进的学习范式或有效的表征方法引入了推荐系统中,取得了一定的成果。**缺点:**一是模型规模较小,模型的能力比较弱,远小于 ChatGPT 之后的一些模型;二是这些工作所需要的训练量很大,模型学会推荐任务的效率是比较低的;三是基础模型能力较弱,导致模型知识有限,泛化性不足,生成能力较弱。接下来将介绍在 ChatGPT 发布之后,当具备强大基础模型之后的一些工作,如何将这些 well-train 的模型能力带进推荐系统来。
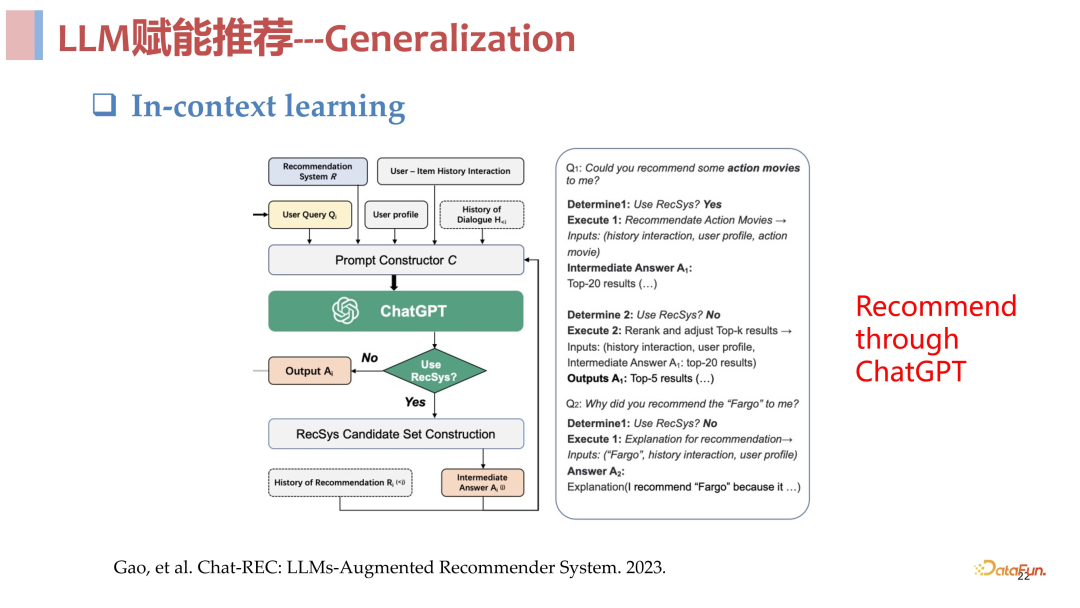
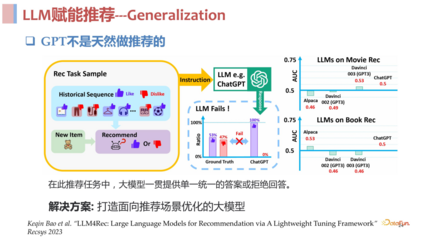
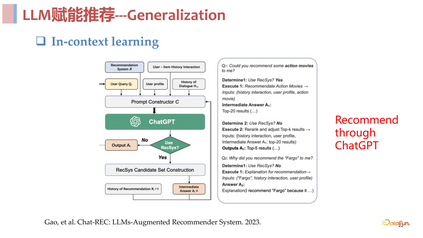
**完全基于 ****ChatGPT ****进行推荐:**第一类方向的工作,认为既然 ChatGPT 是一个可以解决很多任务的强大模型,那么就直接使用 ChatGPT 去解决推荐任务。比如将推荐任务写成一个 instruction,可能加入一些 in-context sample,让 ChatCPT 直接去做推荐。这类工作的结论是比较乐观的,ChatGPT 确实具备一定的能力去做好推荐这件事,但是单纯使用上述方式教会它去做好推荐这件事可能还是不够的。
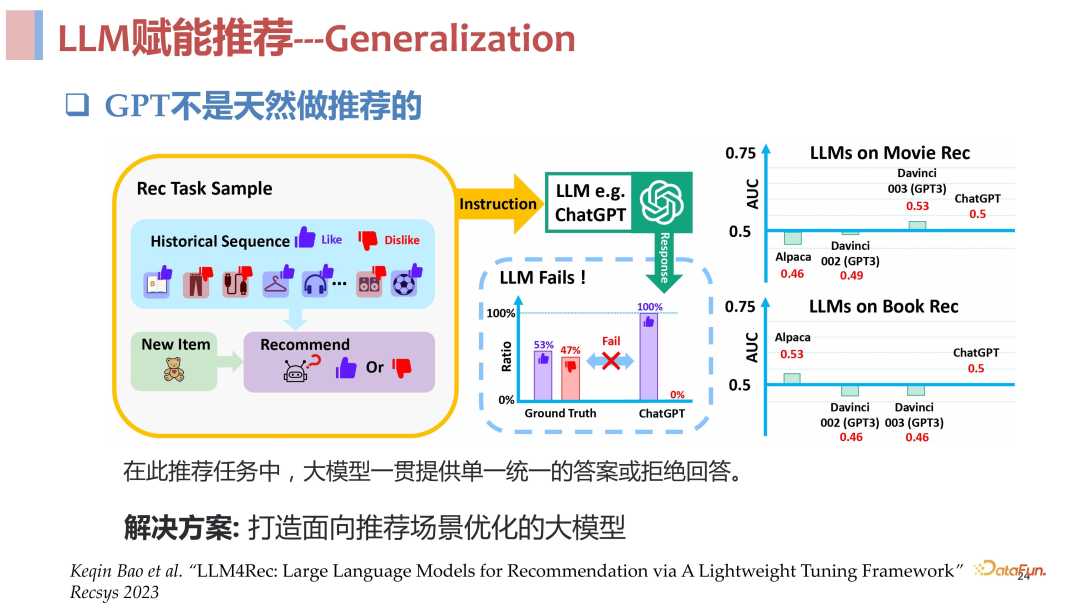
**ChatGPT **不是天然做推荐的:
-
存在偏差: 直接使用其 in content learning 的方式去做推荐的话,一个突出的问题是,GPT 是被高度安全优化过的,所以它很难去拒绝用户,也就是很难 say no,如果我们按照 point wise 的方式,给它一个 list,history,然后问它是不是要把这些推给这个用户,它很难 say no,有很大概率会对很多用户都直接 say yes,也就是所有东西都推对。
-
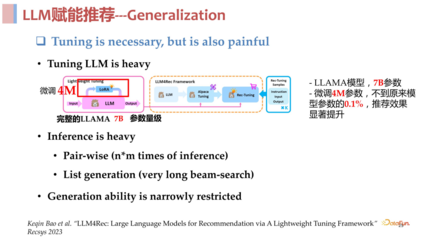
微调难做:当然可以采用 tuning 的方式去缓解上述问题,但是 LLM 的参数量大、模型深度高,tuning 是一件很难的事。
-
部署成本高:即使采用 lora 之类的方式去解决 tuning 的问题,大模型的 inference 依旧困难,相对传统的推荐模型推理成本很高。我们曾经计算过,以 TikTok 的日活用户规模,如果每个用户让大语言模型去算 100 个 candidate item 的分,那将会需要 10 万张 A100-80G 显卡,24 小时不停算才能算完,这个开销是难以接受的。
-
**生成能力受限:**针对推荐场景去对大语言模型进行 fine tune 之后,会压缩模型对生成空间,导致其生成能力受到很大的限制。
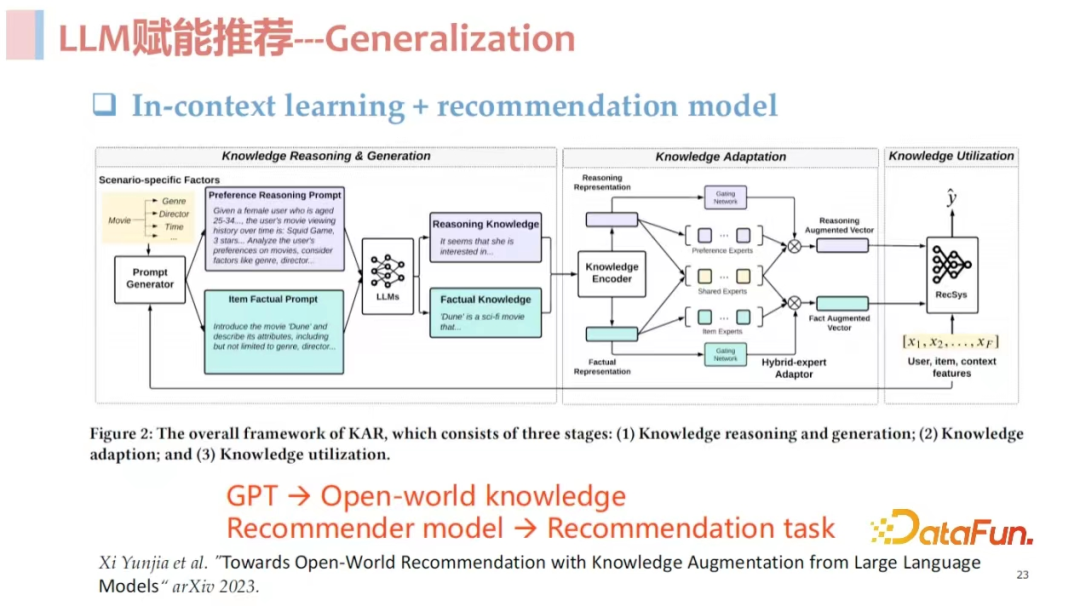
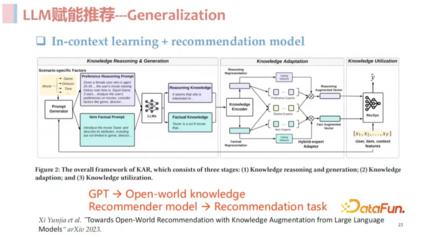
**结合 ****GPT ****和传统推荐技术:**现在介绍唐瑞明老师团队参与的一个工作,其核心思想是通过 ChatGPT 或者 in-context learning 的方式,让 ChatGPT 发挥其 open world knowledge 的知识能力和 Cross domain 的能力,将 ChatGPT 的输出接入给下游的传统推荐模型。这样两者相互协同,发挥各自的优势,推荐系统负责搞定推荐任务,ChatGPT 负责提供 Knowledge、Cross Domain 和 few-shot 的能力。这项工作是非常成功的,总结其核心就是使用 in-context learning 通过 ChatGPT 对用户的交互历史和 item 分别做一个推荐角度的总结,然后将其作为额外的特征喂到 CTR 模型里。

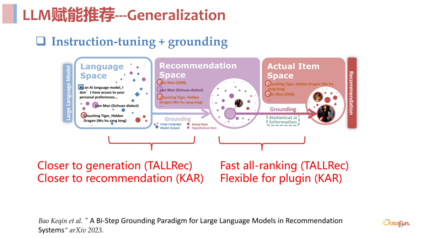
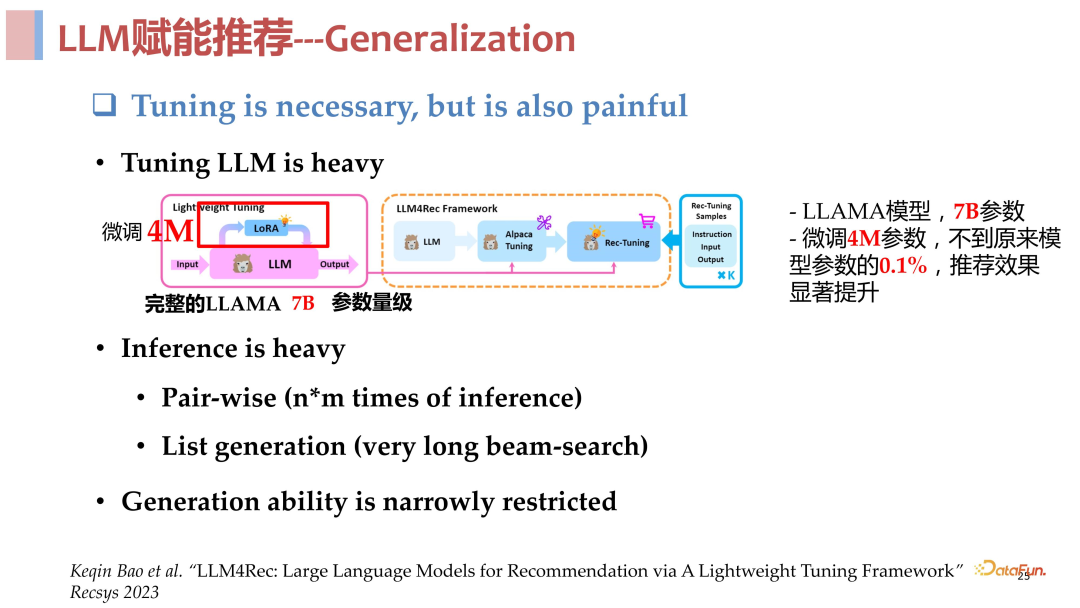
**打造面向推荐场景优化的大模型:**为了解决 LLM 在推荐领域直接应用的诸多问题,我们提出了一个与生成式检索类似的两阶段框架,其核心思路是从语言和推荐两个不同的角度去做理解,充分发挥各自的优势,整个推荐链路被划分成了三个空间:
- 首先是**语言空间:**构造合适的 prompt 输入用户的历史交互序列,让大语言模型自由输出内容,充分发挥大语言模型的生成能力,从语义层面去做理解。
- 然后是**推荐空间:**与语言空间不同,对于输入的用户交互序列,推荐空间不是从语义层面去理解 sequence 中包含的信息,而是站在推荐角度去看 sequence 中哪些信息是与推荐相关的,去描述与推荐相关的文本。
- 最后是 **item ****空间:**从统计角度上去理解,融合协同过滤之类的统计信息,落在要进行推荐的具体的 item 上,去做打分和排序,完成最终的推荐。
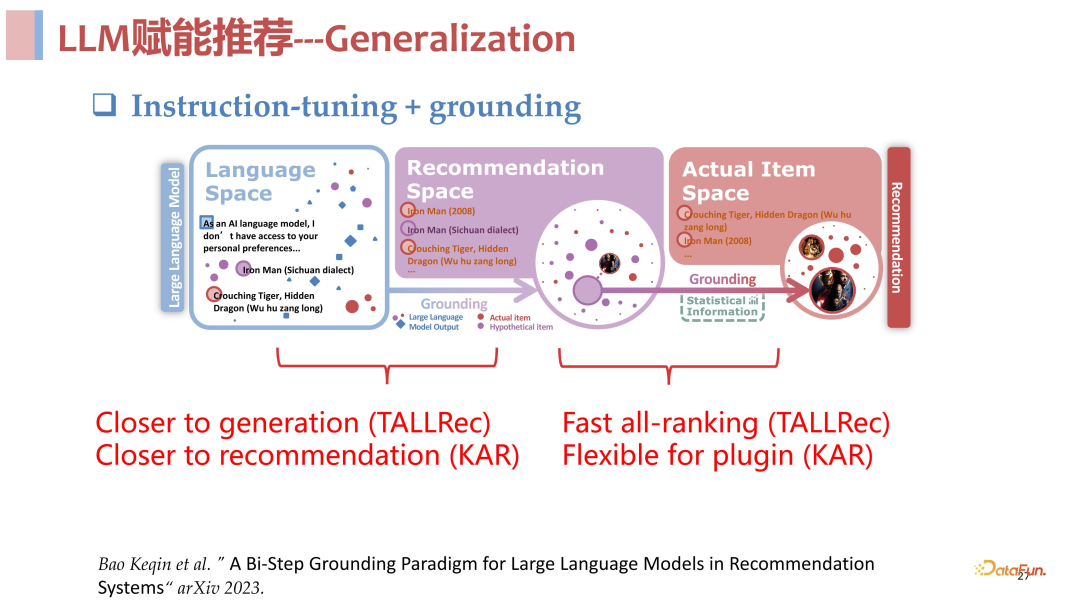
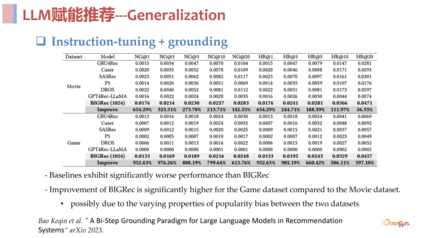
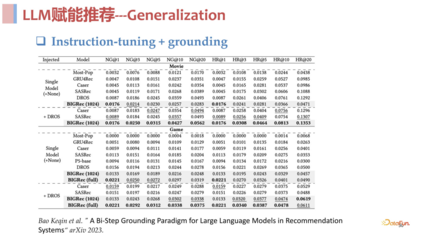
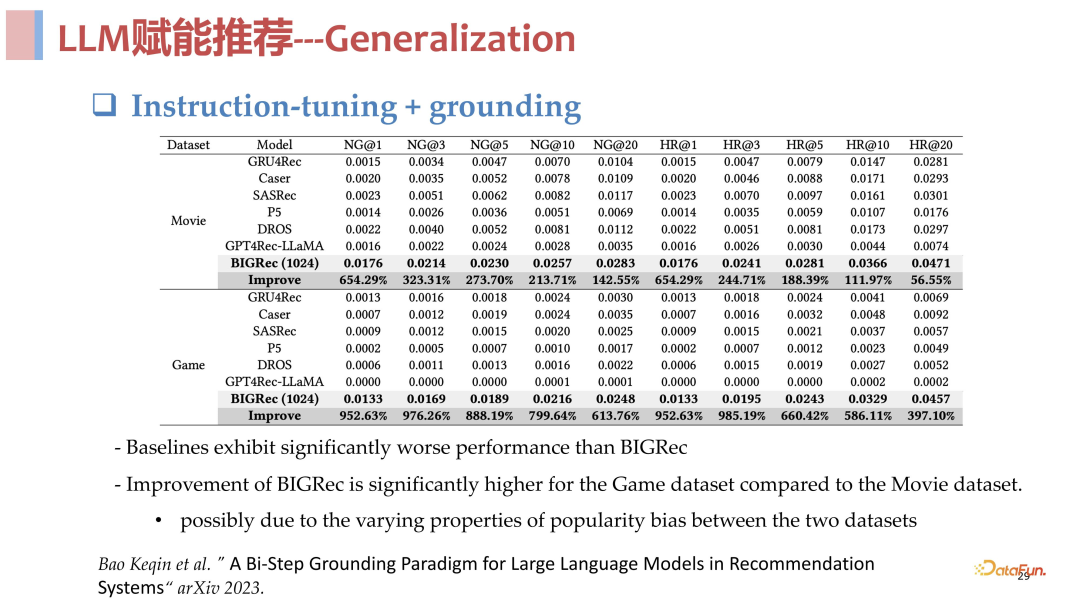
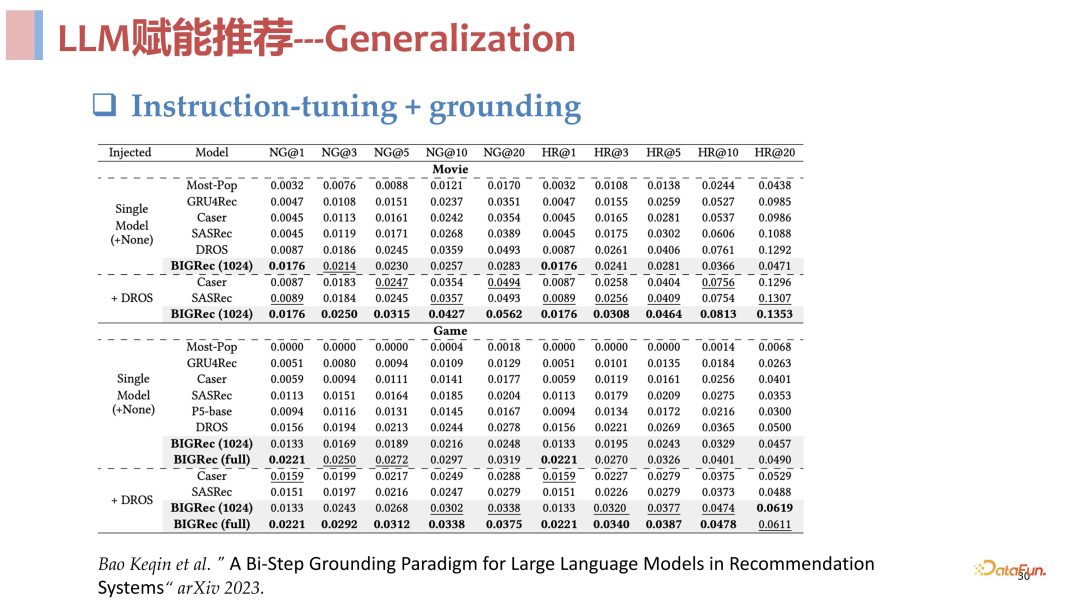
总结来说,语言空间和推荐空间作为第一阶段进行理解召回,item 空间作为第二阶段进行快速打分排序,其实和传统的召回排序是一样的。从实验结果来看,这个方法是非常有效的,在 few shot 场景下与传统模型相比非常具有优势,具体的实验数据见下方。
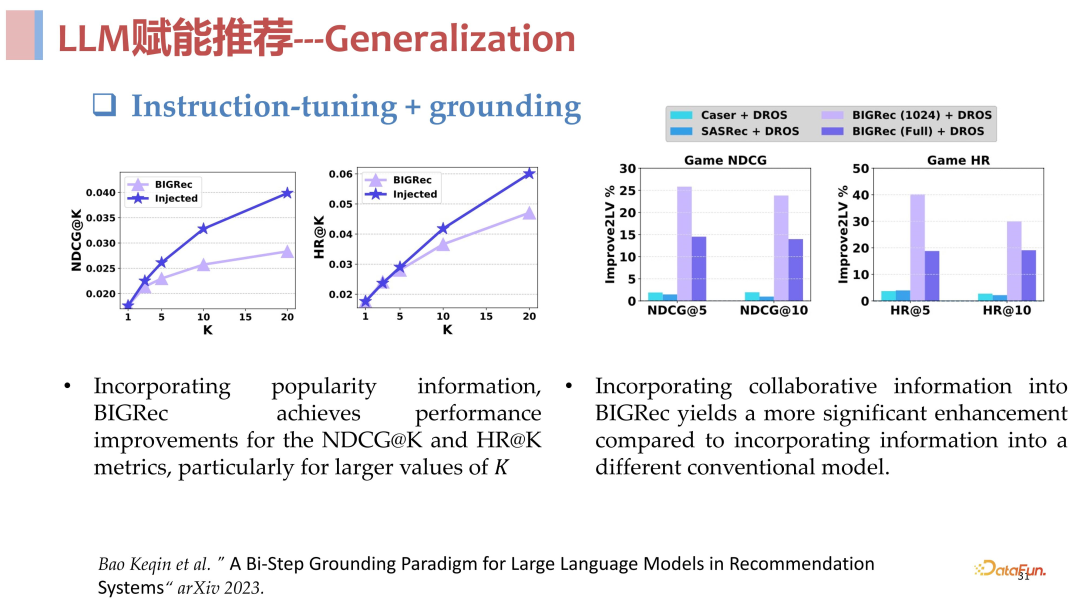
03****
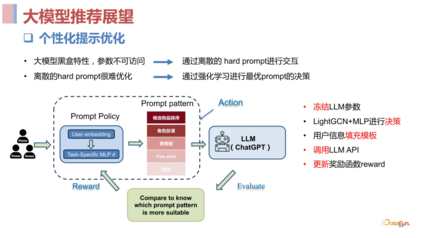
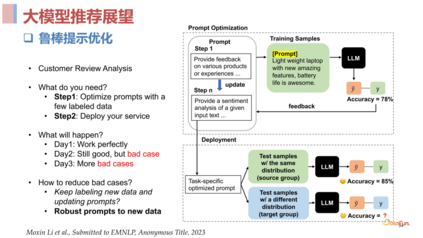
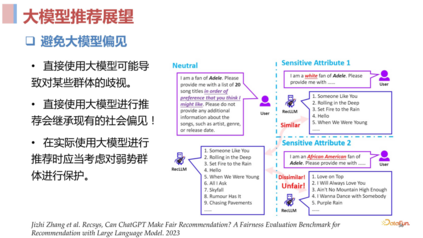
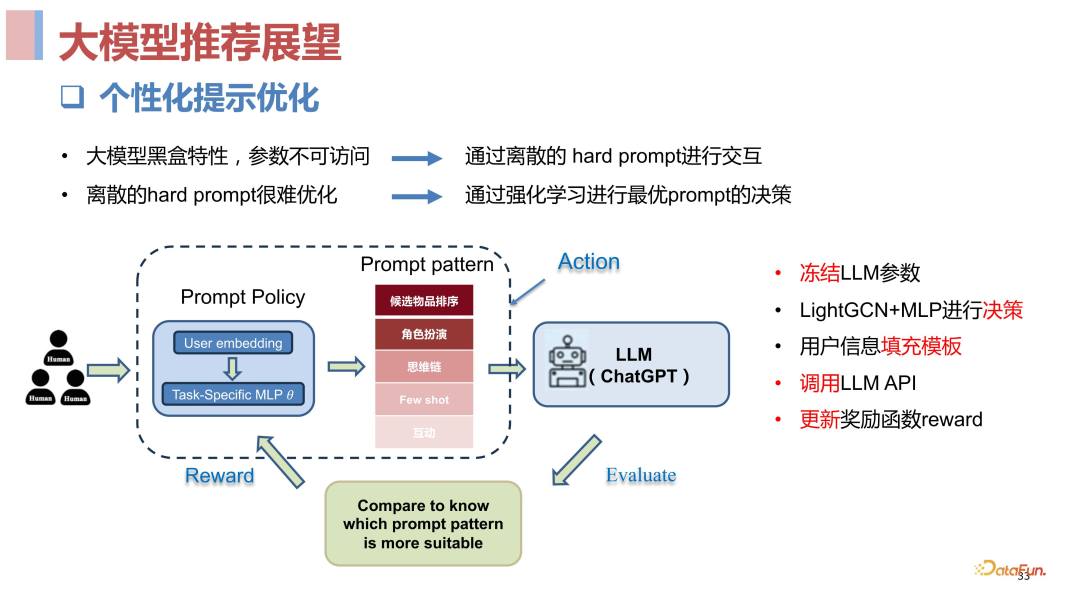
大模型推荐展望****1. 个性提示优化
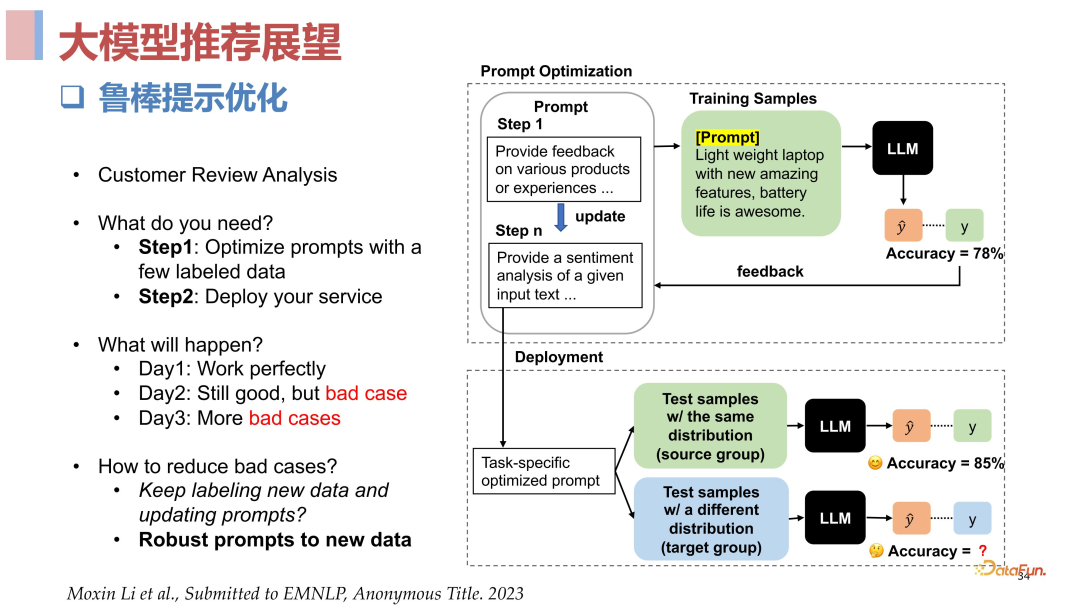

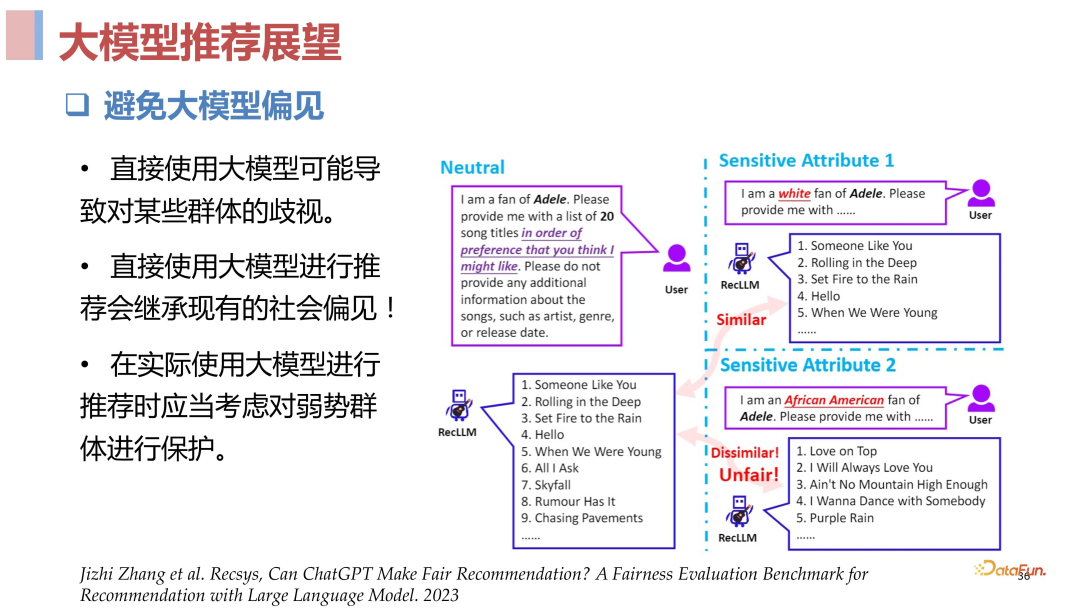
04****
总结****

- 使用尽可能大的基础模型,比如 GPT4 这样具备强大能力的模型,不要去用 Bert 之类的模型了。
- Fine-tune 过程中尽量保持模型的生成能力。
- 融合一些语言难以描述的统计信息是十分必要的。 最后,介绍一下中科大****数据空间研究院。作为新型研发机构、省政府成立的事业单位,研究院以数据重构网络空间为核心理念,聚焦大数据、人工智能和网络空间安全。期待更多科技人才的加入,共同努力开展前沿技术研究和应用落地。


分享嘉宾
INTRODUCTION

冯福利
中国科学技术大学
特任教授
冯福利,中国科学技术大学特任教授,入选国家青年人才计划。研究领域:信息检索、数据挖掘、机器学习、因果推断等,承担推荐算法合规、监管相关国家级项目,发表国内外顶级会议和期刊论文近 100 篇,谷歌学术引用 6000 余次,研究成果在多家公司的商业系统应用。曾获 SIGIR 2021 最佳论文提名奖、WWW 2018 最佳演示论文奖。