

一幅图像可以传达千言万语,但一段视频——由数百或数千帧图像组成——讲述的是一个更为复杂的故事。
尽管多模态大型语言模型(MLLMs)取得了显著进展,生成长视频仍然是一个艰巨的挑战。截至本文撰写时,OpenAI 的 Sora [110],当前的最先进系统,仍然仅限于生成最长为一分钟的视频。这一限制源于长视频生成的复杂性,生成长视频不仅仅需要生成 AI 技术来逼近密度函数,还需要解决诸如规划、故事发展以及保持空间和时间一致性等关键问题,这些问题增加了额外的难度。将生成 AI 与分而治之的方法相结合,能够提高生成更长视频的可扩展性,同时提供更大的控制力。在本综述中,我们审视了长视频生成的当前研究现状,涵盖了基础技术,如生成对抗网络(GANs)和扩散模型、视频生成策略、大规模训练数据集、长视频评估的质量指标以及未来研究方向,以解决现有视频生成能力的局限性。我们相信,这将作为一个全面的基础,为未来长视频生成领域的进展和研究提供丰富的信息。

1 引言
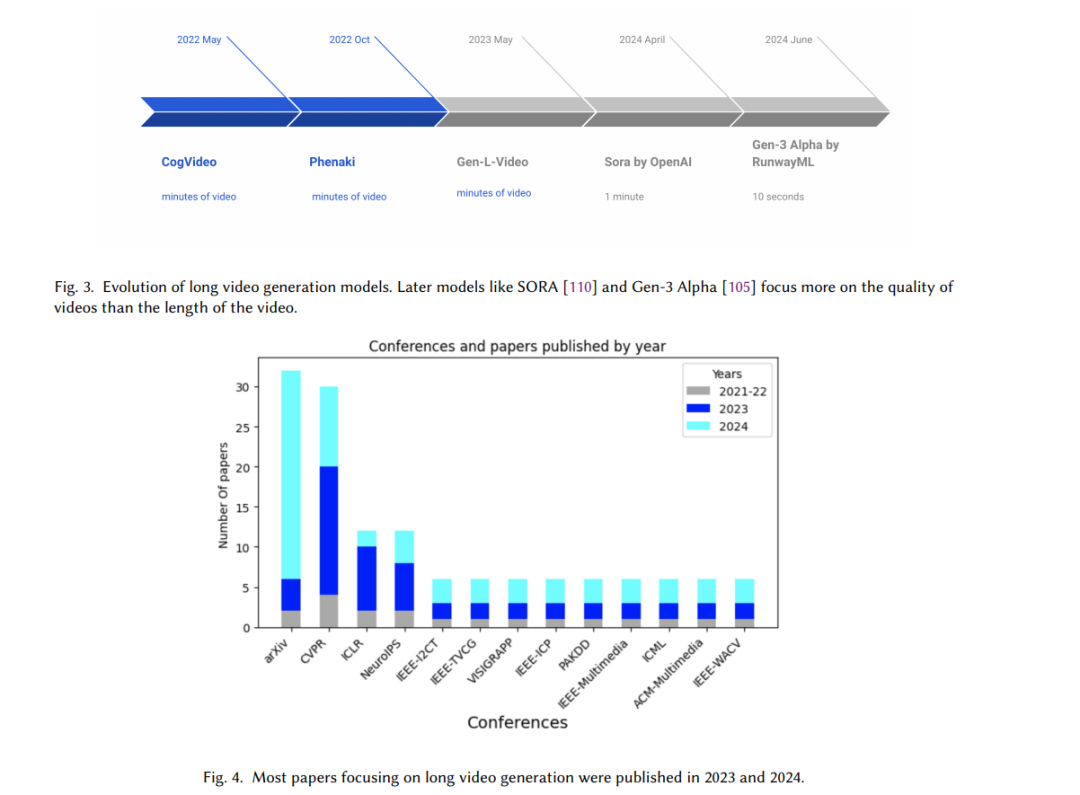
2022年标志着生成式人工智能领域的一个重要里程碑,随着ChatGPT的发布[108]。ChatGPT是一个先进的语言模型,能够根据用户输入生成类似人类的文本,支持回答问题、创意写作和对话等任务。该技术使用复杂的深度神经网络,基于大量文本数据训练的大型语言模型,捕捉复杂的语言模式和上下文细微差别,从而实现精确的文本生成与理解。自那时以来,主要的科技公司相继推出了各自的大型语言模型(LLMs),如Facebook的LLama系列[103]、Google的Gemini[102]以及其他一些值得注意的模型,包括Claude[101]和Mistral[107]。 随着大型语言模型的成功,图像生成领域也迎来了变革性的突破。DALL-E 2[79]代表了一个重要的飞跃,超越了传统的生成对抗网络(GAN)和变分自编码器(VAE)模型,凭借其解读自然语言并渲染各种概念和风格的能力。它在从现实和富有想象力的提示中生成照片级真实图像方面表现出色。其他领先的生成式AI系统,如Stable Diffusion 3[19]和MidJourney[106],也展示了在基于真实与想象的创意生成照片级视觉效果方面的卓越能力。 生成视频远比生成文本或图像具有更大的挑战。与静态图像或文本不同,视频是动态的,包含变化的摄像机角度、运动、形变和遮挡模式。生成真实感强的长时间视频需要不断生成新内容,同时保持一致性。视频由多帧组成,每一帧的语义内容都会随着视频进程而变化。在这里,"语义内容"指的是一帧图像的概念性地图,表示该帧中的各个元素(如物体、动作和互动)如何共同贡献于对视频的整体理解。例如,图1展示了一个单场景视频,视频中一个女孩在静止的背景前重复舞动。这个例子突出了帧之间语义内容的最小变化,没有引入新角色或动作。这样的短视频片段可以被分类为单一场景,其语义内容在整个过程中保持不变或大致一致。相比之下,图2展示了一个多场景视频的例子,在后续的帧中物体的数量发生了变化,并且出现了新的演员。在这种情况下,随着视频的推进,帧的语义内容发生了变化。 由于动态场景的复杂性,早期的视频生成模型仅限于生成持续几秒钟的短视频,这些视频通常只对一个静态帧进行动画化,而没有引入变化的背景或物体。例如,Make-A-Video[88]和RunwayML Gen-2[104]生成了4-5秒钟的视频,使用一个动画帧,语义内容变化很小。CogVideo[35]是最早的长视频生成模型之一,它使用自回归变压器生成扩展视频。然而,它基于单一提示,并且视频的语义内容变化很小。Phenaki[120]采用自回归视频变压器,是最早的可以基于多个提示生成具有动态语义内容的长视频的模型之一。同样,Gen-L-Video[124]使用扩散模型将短视频片段组合成一个连续的视频。最近,Sora[110]在视频生成中建立了新的最先进技术。它利用扩散变压器和从压缩的时空表示中采样,生成视觉效果惊艳且语义内容丰富的视频。RunwayML的Gen-3 Alpha[105]是另一种在长视频生成中达到最先进水平的模型。它是一个商业模型,可以生成最长10秒的照片级真实视频,同样基于扩散变压器。图3展示了这些长视频生成技术的演变,相较于人类制作的商业视频,尤其在视频长度和叙事组织方面,这些技术仍处于初级阶段。 1.1 综述贡献 — 总结长视频生成方法的必要性
长视频生成面临许多挑战,不仅仅是制作和维持场景之间一致的故事情节。这些挑战还包括缺乏带有详细说明的大规模视频数据集和对大量计算资源的需求。尽管存在这些困难,长视频生成已经成为生成式人工智能领域的新前沿,并在娱乐、教育、医疗、营销和游戏等领域具有潜在应用。这一领域的研究引起了广泛的关注,导致相关研究的数量迅速增加。如图4所示,大多数关于长视频生成的论文都是在过去两年内发表的。 由于这些兴趣和机会,正是时候总结长视频生成领域的最新进展,并讨论相关的挑战、进展和未来发展方向,以支持该领域的进一步发展。根据我们的了解,目前只有两篇相关的长视频生成综述[50]和[154]。前者[50]深入探讨了长视频生成的最新趋势,强调了“分治法”和“自回归方法”作为两个主要主题,并审视了像VAE、GAN和基于扩散的生成模型等生成范式。然而,尽管它突出了分治法这一简化长视频复杂性的方法——通过将视频拆分成更小、可管理的部分,但它并未详细探讨这一方法论,尤其是如何将短视频无缝地整合成更长的叙事视频。我们的工作旨在弥补这一空白,通过全面分析分治策略的各个方面及其在解决长视频生成挑战中的作用。与此不同,后者[154]提供了关于视频生成领域的更广泛概述,涵盖了长视频、视频编辑、超分辨率、数据集和评估标准等话题。然而,长视频生成仅是其中讨论的众多主题之一,突出了对长视频生成进行集中、深入研究的需求。我们的贡献正是针对这一需求,全面分析这一新兴领域,突出关键方法、挑战和未来前景。 本工作的贡献在于填补现有文献中的空白,通过整合最新的研究,全面分析分治法的应用。具体来说,我们聚焦于一些未被充分探索的方面,如基于代理的网络和从短视频到长视频过渡的方法,而这些内容在当前的综述中并未涉及。此外,我们还扩展了对不属于分治法和自回归类别的研究和最新进展的讨论,这些内容此前的综述未曾覆盖。我们深入研究了相关文献,强调了生成长视频时使用的算法、模型和输入控制技术,提供了该领域更为全面和详细的视角。
1.2 综述重点 — 长视频生成中的技术、挑战和关键问题
视频生成采用了多种技术,例如从潜在空间采样[57]、创建小视频片段或图像、生成中间帧(“分治法”)[3.2]、采用自回归方法[3.1]根据初始帧预测未来帧,以及增强长视频的潜在状态表示。训练视频生成模型面临的挑战包括更高的计算要求和更大的内存需求,尤其是对于视频数据集。许多视频生成模型基于预训练的图像模型[37][62][5],增强了注意力机制,以确保相邻帧之间的一致性,因为视频本质上是帧的序列。 一些长视频模型是通过扩展短视频生成模型[147][11][124]并改善控制机制以适应更长内容来发展的。视频生成的另一个重要方面是输入引导[4.1][4.3][4.2]。与图像或短视频生成不同,引导对长视频生成至关重要,通常基于类似CLIP[76]的文本嵌入。LLMs[3.2.1]在引导视频生成过程中发挥了关键作用,通过理解世界动态、物体轨迹和动作分组,利用其广泛的知识来指导视频的创作。 在评估生成视频的质量时[6.1][6.2][6.3][6.4],需要评估单帧的质量、运动流畅性以及整体美学吸引力。确保生成的视频与输入文本一致,并在视频中保持实体一致性,如汽车和演员等,这一点尤为重要。这引发了在该领域研究创新方向的兴趣,并推动了以下相关研究问题的探讨:
- 如何生成包含多个语义片段的长视频,这些片段具有不同的演员、动作和物体?
- 如何确保长视频片段之间的语义一致性,例如保持物体模型(如汽车)的一致性?
- 如何管理长视频训练和推理过程中的资源需求?
- 如何处理扩展视频序列的控制信号(条件)?
我们的综述文章围绕这些关键问题展开,提供了有益的见解,指导研究人员和从业人员解决这些挑战。
1.3 综述方法
在本次综述中,我们进行了多项会议的检索,包括但不限于ICCV、ECCV、CVPR、ICLR、ICML、IEEE、TPAMI、IEEE Neural Networks、AAAI、WACV、ICIP、NeurIPS、KDD、ACCV、IJCV、AI Open和CVIU。我们使用了“视频生成”、“长视频生成”和“LLM引导的视频生成”等关键词。此外,我们还搜索了学术数据库,包括Google Scholar、IEEE Xplore、ACM Transactions和Scopus,重点关注“长视频生成”这一术语。 我们的综述覆盖了2021年至2024年8月期间发表的论文,重点关注“视频生成”和“生成式人工智能”。我们通过滚雪球采样收集了100多篇文章,使用了诸如文本到视频、生成式人工智能、视觉解读和扩展视频生成等关键词。
1.4 综述结构
我们将首先讨论视频生成的基础框架,包括嵌入和LLMs,为更高级的主题奠定基础。目标是让读者熟悉这些基本组件,以便根据他们的专业水平进一步探索这些构建块。接下来,我们将探讨视频生成的核心机制,如分治法、自回归和全局增强。我们将探索输入引导机制,包括LLM引导策略,并根据LLM控制深度的不同将其分类。我们还将讨论扩散模型所需的图像和视频模型修改,以促进这种控制。接着,我们将讨论训练视频生成模型所需的数据集。然后,我们将探讨用来衡量生成视频质量的评估标准。最后,我们将讨论未来趋势和开放挑战。