

语言生成和推理领域的快速发展得益于围绕大型语言模型的用户友好库的普及。这些解决方案通常依赖于Seq2Seq范式,将所有问题视为文本到文本的转换。尽管这种方法方便,但在实际部署中存在局限性:处理复杂问题时的脆弱性、缺乏反馈机制以及内在的黑箱性质阻碍了模型的可解释性。
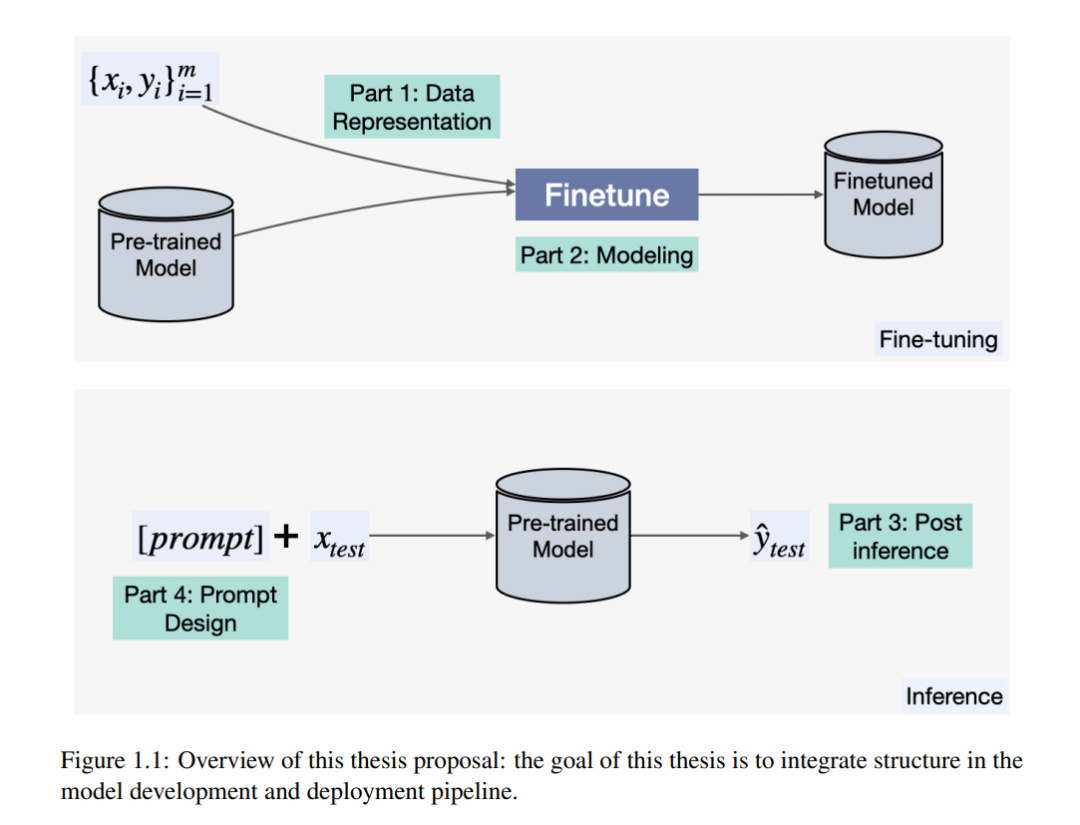
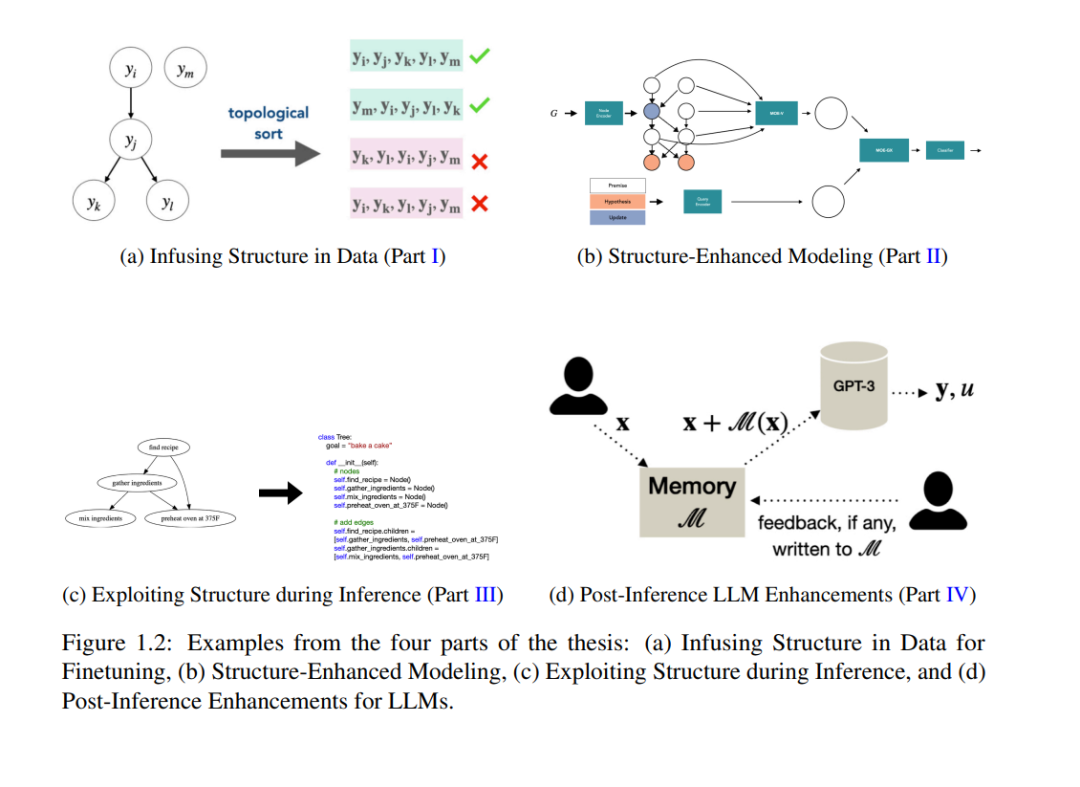
本文提出了通过在语言模型的设计和操作中整合结构化元素来解决这些局限性的方法。在此背景下,结构被定义为数据的系统性、层次性或关系性组织和表示,以及在学习和推理过程中引入结构约束。这些元素在模型开发和部署的不同阶段被整合:训练、推理和推理后。在训练阶段,我们提出了训练图辅助问答模型的技术,并发现有助于有效生成序列集的顺序。在推理阶段,我们提出了利用代码作为中间表示来整合结构的技术。在推理后阶段,我们介绍了整合记忆的方法,使模型能够利用反馈而无需额外训练。
这些技术共同表明,传统的文本输入-文本输出解决方案可能无法利用对模型利益相关者显而易见的有益结构属性。在模型开发过程中整合结构需要仔细审视问题设置,但通常相对简单的实现可以带来显著的回报——一点结构就可以产生很大作用。
最后,我们提出下一代AI系统将把大型语言模型视为强大的内核,在其上构建灵活的推理程序以增强复杂推理。这种由推理时间计算概念驱动的方法,有望显著提高AI的解决问题能力。
1.1 背景和动机
下一个词的预测能力令人惊讶地强大。从理论上讲,通过逐个生成一个片段或词元,可以逐步生成包括文本、代码和蛋白质在内的一系列复杂结构。
因此,不难理解,随着文本生成和推理的用户友好库的广泛普及,许多任务已成功地在seq2seq框架中实现 [Radford, 2018, Raffel et al., 2020a, Yangfeng Ji and Celikyilmaz, 2020]。这不仅扩展到对话生成和摘要生成等自然适合这些范式的任务 [Zhang et al., 2020b, Gehrmann et al., 2021b],还包括传统上与语言模型不相关的任务,如蛋白质序列预测 [Gomez-Bombarelli et al.´ , 2018]、图生成 [You et al., 2018]、程序合成 [Nijkamp et al., 2022a, Chen et al., 2021b, Wang et al., 2021] 和结构化常识推理 [Bosselut et al., 2019]。
尽管通常不建议将任务适配到现有工具 [Paszke et al., 2017, Wolf et al., 2019],但这些库的易用性和可访问性有时会导致忽视使用这些现成解决方案所带来的固有权衡和局限性。通常,开发人员只需按照规定的格式提供输入数据(例如,逗号分隔的输入和输出值文件),库就会处理其余步骤。这些库的简单性促进了快速实现和实验。然而,这种便利性是有代价的。
1.1.1 现有大型语言模型设置的局限性
在本文中,我们认为识别和解决这些权衡对于文本生成和推理框架的实际和具有挑战性的部署至关重要。这些缺点包括处理复杂问题时的脆弱性、缺乏接收反馈的机制以及其不透明的黑箱性质 [Ortega et al., 2021]。我们的目标是深入探讨这些问题,并探索能够在现实应用中增强文本生成和推理框架的实用性和鲁棒性的潜在解决方案。接下来,我们将详细讨论这些挑战。
(1) 提供反馈的能力:反馈对于根据用户偏好定制模型输出和改善整体用户体验至关重要。然而,当前的Seq2Seq模型并未设计为能够直接接收反馈,这使得用户难以影响或引导模型的输出 [Kreutzer et al., 2018, Jaques et al., 2019]。提供反馈的能力将使得结果更加互动和用户驱动,从而实现更好的定制和改进整体性能。例如,在一个对话系统中,用户寻找纽约市的意大利餐厅时,可能希望澄清或纠正Seq2Seq模型提供的信息。如果模型建议了错误的地点,用户没有简单的方法来提供反馈并引导模型找到正确答案。更糟糕的是,如果没有保留反馈的能力,模型将继续重复同样的错误。为了解决这个问题,已经提出了几种方法,例如从人类反馈中进行强化学习 [Kreutzer et al., 2018, Jaques et al., 2019],用于序列预测的演员-评论家算法 [Bahdanau et al., 2017],以及监督学习 [Stiennon et al., 2020, Ouyang et al., 2022b]。然而,这些方法通常需要额外的训练或大量数据,使其不太适合少样本学习或数据有限的场景。尽管有这些进展,在开发适用于少样本学习情境下的Seq2Seq模型的实际和高效反馈机制方面仍存在显著的研究空白。在本文中,我们旨在调查这一空白,并探索能够有效整合用户反馈而无需重新训练的新方法,从而增强Seq2Seq模型在数据有限的现实应用中的性能和适应性。
(2) 由于表示不匹配导致的脆弱性:Seq2Seq模型面临的主要挑战之一是处理与训练时遇到的文本数据显著不同的输入或输出时的脆弱性。这种局限性在应用于需要不同于训练期间所遇到表示的非常规任务或领域时,会导致性能不佳 [Lake et al., 2017, Ratner et al., 2017]。开发能够处理多样化和不匹配表示的模型,不仅会提高其泛化能力,还将扩大其在更广泛任务中的适用性。例如,训练在大量英语文本上的Seq2Seq模型可能不适合处理领域特定语言的输入或输出,如数学方程或计算机代码。解决处理不匹配表示的问题对于创建能够适应各种现实场景和任务的更通用和鲁棒的Seq2Seq模型至关重要 [Graber et al., 2018]。 (3) 未能利用数据中固有的结构:普通Seq2Seq模型的一个重大局限性是它们倾向于将输入和输出数据视为非结构化序列,往往忽略了可以利用的任何潜在结构或模式,以增强模型的理解和生成能力 [Bastings et al., 2017]。将领域特定的知识、结构或约束整合到模型架构或训练过程中,可以实现更准确、高效和连贯的输出生成,从而在专门任务或领域中表现更佳。
人类化文本生成和推理的关键能力
一个常见的观点认为下一个词预测目标的简单性类似于人类处理和生成语言的方式 [Heilbron et al., 2022]。然而,人类推理展现出当前模型难以复制的细微差别。以下几个例子突显了这些局限性:
生成多个候选项:人类常常会创建和评估多个选项,而标准的大型语言模型输出中并不固有这种过程。
迭代生成:在人类写作等任务中,人们会进行迭代审查和改进,而大型语言模型通常是一蹴而就的生成。
上下文和世界知识:人类交流依赖于超出即时文本数据的广泛知识和上下文信息。
工具使用:人类使用各种工具完成任务,关键在于人类能够意识到何时需要特定工具。
问题重构:人类常常会重新表述问题并重试。
优先处理简单任务:一种常见的人类解决问题策略是优先处理问题的简单部分。
这些例子共享一个共同主题:需要超越简单的输入/输出关系。大型语言模型具备显著的能力,但要解决完整的任务谱,它们需要增强更复杂的推理过程。这一需求体现在少样本提示技术的兴起中,其中策略如搜索、自我改进和工具使用被用来增强这些模型。许多这些技术隐含地引入了结构元素,接下来将对此进行解释。
1.1.2 注入结构:本文的贡献
某些问题可能具有内在结构,可以利用这些结构来提高可解释性或有效性。例如,在解决常识推理问题时,可能有必要基于捕捉相关关系和依赖性的知识图来调节结果 [Han et al., 2020]。解决这一差距并开发将结构信息整合到Seq2Seq模型中的方法,有可能显著提升其在广泛领域和任务中的性能和适用性 [Zhang et al., 2019a,c]。
结构是一个在AI领域中具有多重解释的模糊术语 [Newell et al., 1972, Russell, 2010]。在本文中,我们采用广义的结构视角,不仅包括其在组织训练数据中的使用 [Bengio et al., 2013, Schmidhuber, 2015],还包括其在整个模型开发和部署生命周期中的作用,从增强训练和推理结果 [Vaswani et al., 2017, Devlin et al., 2019, Lake et al., 2017],到提高最终结果有效性的推理后调整 [Nye et al., 2021b, Dohan et al., 2022]。
**定义1(结构)
在结构增强生成和推理的背景下,结构一词指:a. 数据、知识或信息的系统性、层次性或关系性的组织和表示 [Pearl et al., 2000, Bengio et al., 2013, Hovy et al., 2013]。这有助于捕捉不同元素之间的潜在关系和依赖性,使AI系统更容易理解、生成和使用自然语言进行推理。例如,组织一个知识图以表示领域内实体之间的关系。b. 利用数据或问题领域中固有的结构来优化结果 [Bahdanau et al., 2015a, Vaswani et al., 2017, Battaglia et al., 2018]。这涉及使用数据或知识的结构特性来改进推理、决策或生成,以及提高AI系统的效率、可解释性或可扩展性。例如,利用解析树的结构来指导生成语法正确的句子。
请注意,这一定义超越了传统聚焦于数据排列的结构定义,并将过程纳入定义中。因此,我们的结构定义既涵盖了数据的结构化,也包括了过程本身。




