
基于深度学习的事件抽取研究综述

事件抽取是从非结构化的自然语言文本中自动抽取用户感兴趣的事件信息,并以结构化的形式表示出来.事件抽取是自然语言处理与理解中的重要方向,在政府公共事务管理、金融业务、生物医学等不同领域有着很高的应用价值.根据对人工标注数据的依赖程度, 目前基于深度学习的事件抽取方法主要分为两类:有监督和远程监督学习方法.本文对当前深度学习中事件抽取技术进行了全面的综述. 围绕有监督中CNN、RNN、GAN、GCN与远程监督等方法,系统地总结了近几年的研究情况,并对不同的深度学习模型的性能进行了详细对比与分析.最后,对事件抽取面临的挑战进行了分析,针对研究趋势进行了展望.
引言
随着云计算与大数据时代的迅速推进,计算机已经是人们平时获取信息最重要的途径.从各种数据形式中获取最有用的、潜在的信息已成为人们关注的重点方向,信息抽取技术应运而生.信息抽取就是从海量的文本、图片和视频等数据里面自动抽取用户需要的结构化信息的过程.事件抽取作为信息抽取技术的主要分支之一, 同时还是该方向最有挑战性的任务之一.事件抽取一直吸引着许多研究机构和学者,如消息理解会议(MUC,Message Understanding Conference) [1]和自动内容抽取(ACE, Automatic Content Extraction) [2]就把事件抽取作为典型任务.
事件抽取任务研究是从非结构化的自然语言文本中自动抽取用户感兴趣的事件信息并以结构化的形式表示[3],融合了来自计算机科学、语言学、数据挖掘、人工智能和知识建模等多个领域的知识和经验,对人们了解社会有着深远的影响.事件抽取在不同领域中具有许多应用,例如结构化事件能够直接扩充知识库并进行逻辑推理.事件检测与监控一直是政府公共事务管理的重点,实时了解社会事件的爆发和演变有助于对其迅速做出反应并采取措施.在金融业务领域,事件抽取可以帮助公司快速发现产品的市场响应并推断信号以执行风险分析、评估等操作.在生物医学领域,事件抽取能够识别生物分子(例如基因或蛋白质)状态的变化,以及它们之间的相互作用.事件抽取在应用需求的推动下展开,由人工标注数据的依赖情况可以将目前基于深度学习的事件抽取方法主要分为两类:有监督和远程监督学习方法.本文首先简单介绍深度学习中事件抽取的发展,再从事件抽取研究的方法,对其发展状况和技术推进两个维度全面阐述事件抽取的工作,然后概述了深度学习中事件抽取的数据集及对评价指标进行分析,最后讨论了事件抽取中面临的挑战及研究趋势,并对其进行了总结和展望.
1 事件抽取的发展
20 世纪 80 年代末,事件抽取的研究开始蓬勃发展,其中耶鲁大学、MUC、ACE 和文本分析会议(TAC, TextAnalysis Conference) [4]的相关测评都推动着事件抽取技术的快速发展,情况如表1 所示.
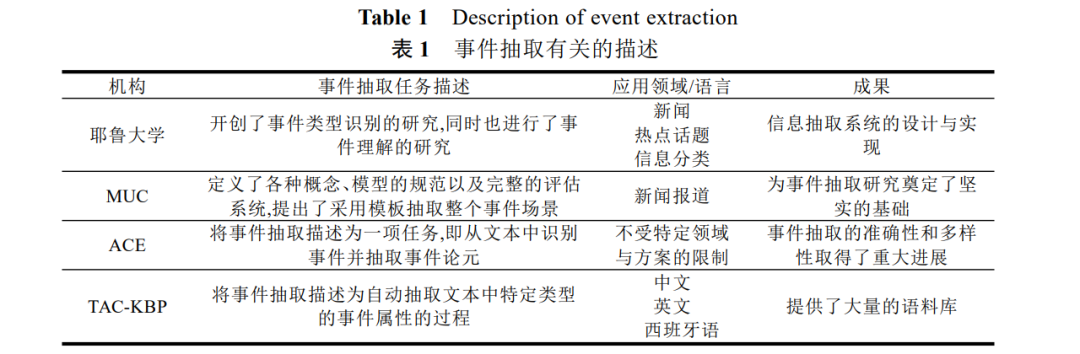
MUC 会议每两年举办一次,主要是美国国防高级研究计划委员会(DARPA,Defense AdvancedResearchProjects Agency) [1]赞助的.它从 1987-1997 年总共举办了 7 届,积极推动了事件抽取研究方向的确定与后续发展的方向. ACE 会议是 MUC 的延伸,在大量的应用需求下,1999 年美国国家标准技术研究院(NIST, National Instituteof Standards and Technology) [2]组织的 ACE 评测会议开始发展起来.ACE 从 2000 年到2007 年共举办了8届, 这是事件抽取领域最有影响力的评测会议. TAC 会议是 NIST 在 2008 年成立的,自 2009 年开始 ACE 就成为 TAC 中的一个子任务.随着云计算和大数据时代的到来,数据呈爆炸式增长,上述测评会议所发布的依靠人工标注方式获得的语料库已经无法满足需求.2014 年 TAC 增加了知识库生成 (KBP, Knowledge Base Population) [4]评测任务,同时也增加了事件抽取的任务.如今,事件抽取已成为 TAC-KBP 公开评测的主要任务,可以从大型文本语料库中自动抽取事件信息,完成对知识库中不足论元[5]的补充. 传统基于特征的方法是利用人工构建事件候选触发词与论元,这会导致模型的扩展性和移植性较差.而机器学习方法在特征提取过程容易出现误差传播问题,极大影响事件抽取模型的性能.随着深度学习的崛起,研究者们逐渐将深度学习方法引入事件抽取任务中,大量基于有监督的卷积神经网络(CNN, Convolutional NeuralNetworks) [6]、递归神经网络(RNN, Recurrent Neural Networks) [7]、生成对抗网络(GAN, Generative Adversarial Networks) [8]、图卷积网络 (GCN, Graph Convolutional Networks) [9]与远程监督方法的事件抽取模型被提出.
2 事件抽取研究的方法
近年来,深度学习技术已广泛用于复杂结构的建模,并验证了对许多 NLP 任务都有效,例如机器翻译[10]、关系抽取[11]和情感分析[12]等.双向长期短期记忆(Bi-LSTM, Bi-directional Long Short-TermMemory)模型[13]是一种双向 RNN,可以捕获前后上下文中每个单词的信息,同时利用其信息对单词表示进行建模.CNN是另一种有效的模型,可以提取事件语义表示同时捕获其结构特征. 事件抽取在应用需求的推动下展开,由人工标注数据的依赖程度可以将目前基于深度学习的事件抽取方法主要分为两类:有监督和远程监督学习方法.有监督学习在训练过程中使用人工标注的数据集,而远程监督的学习方法通过对齐远程知识库自动对语料进行标注来获取带标记语料数据,具体比较情况如表2 所示.

2.1 基于深度学习的有监督事件抽取
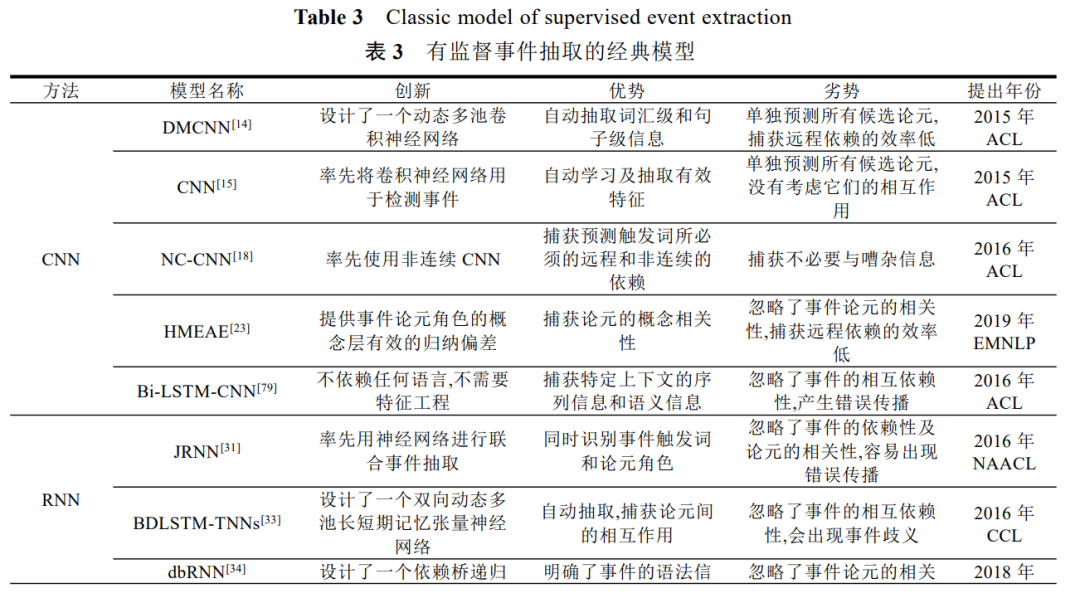
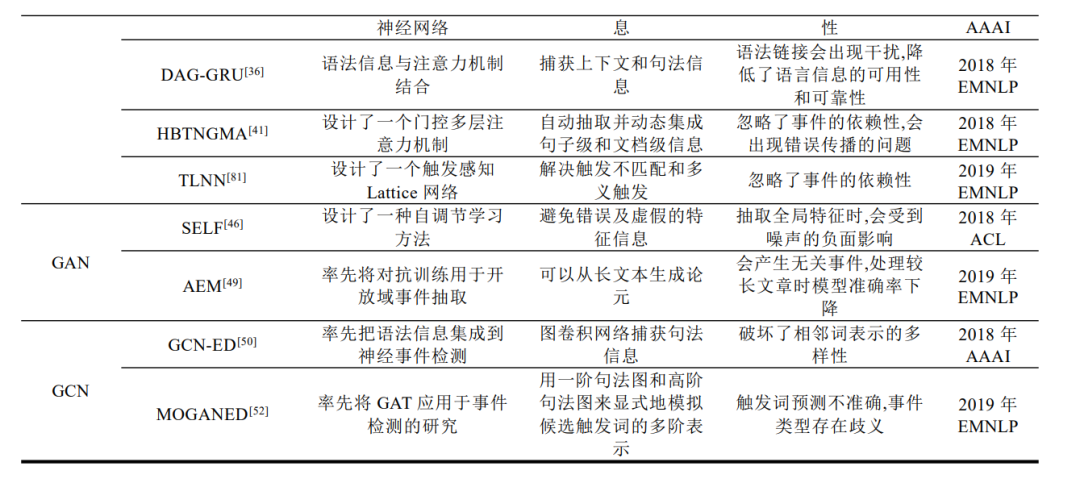
在有监督中运用深度学习方法进行事件抽取,已经成为这几年事件抽取的热门研究方向.表3 整理了深度学习框架下有监督事件抽取的经典模型.其中,模型主要是改进 CNN、RNN 输入特征或网络结构,比如添加不同特征、结合多种注意力机制和引入依存树等挖掘更深层次事件语义信息来提升其性能.下面对相关模型进行深入研究和分析.
**2.2 基于远程监督的事件抽取 **
远程监督(DS, Distant Supervision)可以为事件抽取自动生成大规模标注数据[54]. 为了解决数据标注问题,Chen 等人[55]利用远程监督方法结合 Freebase [56]构建了一个基于维基百科的事件数据集.他们通过 Freebase 找出事件关键论元,自动检测事件和触发词,利用 FrameNet [57]过滤噪声.实验结果表明,该模型能够学到合理权重来缓解远程监督中噪声问题,同时还充分挖掘有用信息.而Zeng 等人[58]则从维基百科和 Freebase 中自动生成训练事件抽取的数据,将事件抽取训练实例从数千个扩展到数十万个.该模型集成了远程监督的知识库,自动从未标记文本中标注事件数据,并开发了一个基于 Bi-LSTM和CRF 的联合神经网络模型.实验结果证明,该模型可以与已有的数据相结合自动抽取事件,还可以进行多类型的事件检测.Keith等人[59]利用 2016 年全年收集的警察死亡语料库,提出了一个基于特征逻辑回归和卷积神经网络分类器的远程监督模型.通过实验结果可以看出,该模型与现有的抽取模型的 F1 值相比有所提高,说明其方法可以更好地进行事件抽取,但是仍存在人工标注导致的错误传播的问题.Rao 等人[60]提出了一种抽象意义表示(AMR)的方法识别生物医学文本分子事件.他们对事件结构的 AMR 子图进行假设验证,在给定 AMR 的情况下利用远程监督神经网络模型,识别事件子图.通过对其在 BioNLP 共享任务的 GENIA 事件抽取子任务[61]上实验表明,仅以蛋白质为论元的简单事件下 F1 值达到了 94.74%,而复杂事件下降到了 74.18%,这是由于AMR 存在错误解析导致的.
**2.3 对事件抽取中深度学习方法的探索 **
FrameNet(简称 FN)中的帧由一个词法单元和一组帧元素组成,分别扮演与ACE 事件触发词和论元相似的角色,缓解了 ACE 数据集事件类型稀疏的问题.Liu 等人[62]提出了一种基于概率软逻辑的全局推理方法检测FN事件.他们还构建了 Event-FN 数据集,缓解了数据稀疏的问题.通过实验证明,该方法可以实现相关事件类型之间的信息共享.Wadden 等人[63]把全局上下文合并到 IE 框架中,提出了一种基于上下文的跨实体、关系和事件抽取框架(DYGIE++).该方法在 ACE 2005 数据集上,事件触发检测和论元角色分类的F1 值分别为76.5%和52.5%.他们对其他数据集也进行了验证,都优于对比的模型.
Yang 等人[64]对事件、实体及篇章内不同事件的依赖关系进行建模,提出了一种完全端到端学习的模型.实验结果表明,该模型在事件类型分类和论元识别的任务中 F1 值都提高了 1.0%.Han 等人[65]利用端到端的方法, 提出了一种基于共享表示与结构化预测的联合事件和时间关系抽取模型.他们运用两阶段学习方法,首先允许事件和关系模块共享相同的上下文嵌入与神经表示,其次利用结构化的推理和学习方法共同分配事件和事件关系标签,避免了常规管道系统中错误传播的问题.对其进行实验的 F1 值分别提高了10%和6.8%,说明该模型对于端到端事件和时间关系抽取是有效的. 在事件抽取的过程中,总是有数据不平衡的问题出现,而且训练数据稀少也会影响模型的训练效果.针对这些问题, Zhang 等人[66]提出了一种基于迁移学习的神经网络框架(JointTransition),采用从左到右的递增阅读顺序捕获实体和事件提及的依赖结构.在 ACE 2005 数据集上的实验表明,事件触发词分类的任务中F1值达到了73.8%,证明了该方法的有效性.Lu 等人[67]提出了一种基于蒸馏学习和知识泛化的△表示学习方法.实验结果表明,在 ACE 2005 数据集上 F1 值提高了 0.7%,在 TAC-KBP 2017 数据集上 F1 值提高了1.53%.Deng 等人[68]提出了一种基于动态内存的原型网络(DMB-PN),包括了事件触发词识别和 few-shot 事件分类两个阶段.他们还定义“few-shot 事件检测”新问题,也创建了新的数据集 FewEvent.实验结果表明,DMB-PN 不仅比其他基准模型更好地处理数据稀缺的问题,而且在事件类型多样和数据极少的情况下模型的性能较好.Deng 等人[69]在2021年提出了一种基于本体嵌入的 ED 模型(OntoED),同时构建了一个新的数据集 OntoEvent.实验结果表明,在事件角色识别和事件类型分类的任务中 F1 值比 JMEE 模型分别提高了 15.32%和 6.85%,证明了其方法鲁棒性较好. 另外,一些工作还通过结合预训练模型提高事件抽取的性能.Yang 等人[70]针对手工创建的数据费力且数量有限的问题,提出了一种基于语言生成预训练的事件抽取模型(PLMEE).他们为了解决训练数据不足的问题,采用原型网络自动生成标注数据.在 ACE 2005 数据集上的实验表明,事件类型分类和论元分类的任务中F1值分别为81.1%和58.9%.2020年,Du等人[71]则针对错误传播的问题,提出了一种基于问答任务的事件抽取模型.他们在预训练 BERT 的基础上将事件抽取转换为问答任务,并以此为模型在事件触发词识别和论元分类任务上的F1 值分别提高了 0.39%和 0.81%。
Gangal 等人[72]针对 RAMS 数据集在事件论元抽取中准确率存在较大差距的问题,提出了一种基于预训练BERT 的事件论元抽取方法(BERTering RAMS).实验结果表明,该方法具有较好的跨句准确性.Zhang等人[73]为了减少候选论元数量的问题,提出了一种两步隐式事件论元检测方法,将问题分解为两个子问题:论元头词检测和头跨度扩展,其中编码模块采用了预训练 BERT 进行上下文编码.在 RAMS 数据集上的实验结果表明,该模型获比其他对比模型的性能更好. 在生物医学上识别触发词相关联的嵌套结构化事件时准确率不高,Huang 等人[74]提出了一种基于层次知识图的生物医学事件抽取方法(GEANet-SciBERT).该方法在预训练语言模型 SciBERT [93]的基础上,加入了一种新的图神经网络模型 GEANet 作为补充.在 BioNLP 2011 GENIA 事件抽取任务中,该方法在所有事件和复杂事件上 F1 值分别提高 1.41%和 3.19% .
2.4 对中文事件抽取方法的研究
中文事件抽取不仅存在比英文更加严重的数据稀缺问题,而且也存在方法层面和语言特性层面的问题. 中文语言词语间还没有显式间隔,在进行分词时会出现比英文更加明的错误和误差.中文语言的复杂性和灵活性让相同语义的词语、短语和句子有更多表达方式,即同一类型事件触发词可以使用更多词语表达. 根据现有的中文事件抽取相关研究,从文本粒度方面可以将其分为两类:句子级事件抽取和篇章级事件抽取.其中,句子级事件抽取主要是利用句子内部获取特征,即识别句子的中文触发词,并判断实体在事件中所扮演的角色.而篇章级事件抽取主要包含了跨句、跨文档抽取的特征信息.
2.5 数据集
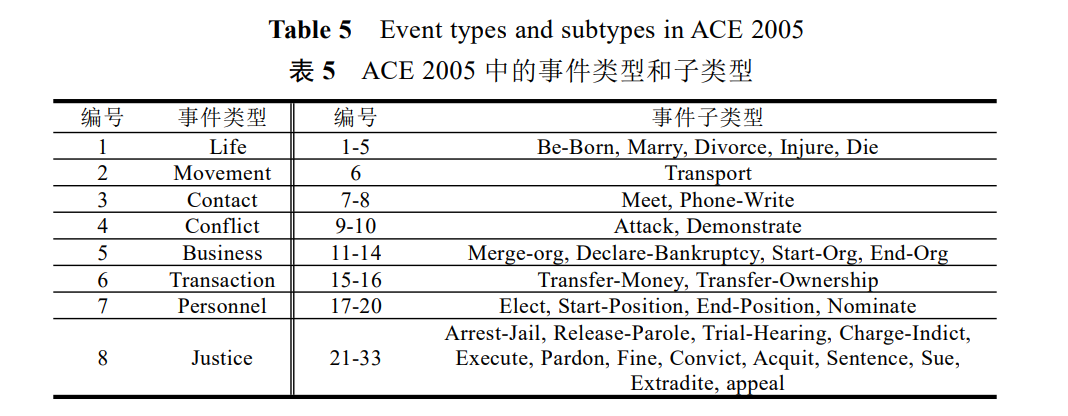
事件抽取中常用的数据集主要包括 ACE 2005、TAC-KBP、BioNLP-ST、GENIA、MLEE 和CEC[86],其中ACE 2005 是应用最广泛的数据集. ACE 数据集是语言数据联盟(LDC, Linguistic Data Consortium)发布的,由实体、关系和事件注释组成的各种类型的数据[2].ACE 2005事件数据集定义了 8 个事件类型和 33个子类型,每个事件子类型对应一组论元角色, 是来自媒体、广播新闻等不同方面的英文、中文和阿拉伯语事件.表 5 描述了相关的事件类型和其子类型.
TAC-KBP 数据集已在 2015 年 TAC 会议事件检测评估中发布[5].TAC-KBP 中的事件类型和子类型是根据ACE 语料库定义的,包括 9 个事件类型和 38 个子类型.TAC-KBP 2015 为英文语料库,但TAC-KBP2016为所有任务添加了中文和西班牙语数据. 生物医学领域的事件抽取数据集,常见的是 BioNLP-ST、GENIA、MLEE 和PC 等.BioNLP-ST是从生物医学领域科学文献的生物分子事件抽取中获得的,包括 GE、CG、PC、GRO、GRN 和BB [87]等任务.GENIA事件数据集是为 GENIA 项目编写并标注的生物医学文献集合事件.而 MLEE 数据集是分子到器官系统的多个生物组织水平的事件.PC 数据集则是与生物分子途径模型有关的反应事件. 除了上述常见的数据集外,还有一些其他领域的数据集,如中文突发事件语料库CEC(Chinese EmergencyCorpus) [86]是由上海大学语义智能实验室所构建,选取了地震、火灾、交通事故、恐怖袭击和食物中毒这5类突发事件的新闻报道进行标注,合计有 332 篇.与 ACE 数据集相比,CEC 较小,但它在事件和事件论元的注释方面更全面.TERQAS研讨会建立了一个名为 TimeBANK数据集,主要用于突发新闻事件抽取[88].还有军事情报领域的 MUC 数据集[89]、丁效等人的音乐领域事件抽取数据集[90] ,以及杨航的中文金融事件抽取数据集[92].
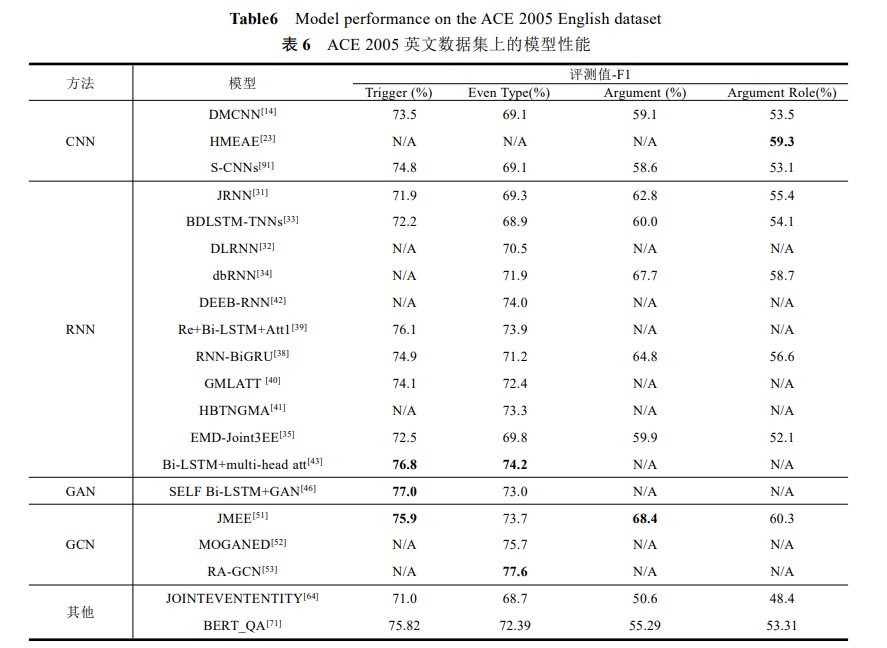
2.6 模型性能及评价
事件抽取常采用准确率(P , Precision)、 召回率(R , Recall) 和 F1 值(F1, F1-Measure)这3项作为基本评价指标.其中,P 是指系统中抽取出的正确个数占抽取出总数的比例,用来衡量抽取准确程度;R是指系统中正确抽取的个数占所有正确总数的比例,用来衡量抽取全面程度;F1 值是P 和R 的加权平均值,作为系统性能的总体评价.
3 事件抽取面临的挑战及研究趋势
事件抽取作为信息抽取中的重要任务之一,能够检测句子提到的某些事件,也可以对事件类型进行分类与识别事件论元.它为知识图谱、推荐系统、信息检索等任务提供基础的数据支持,同时,事件抽取在语义分析、篇章理解、自动问答等领域也具有重要意义.然而,人工智能的发展对事件抽取的准确性提出了更高的要求,深度学习虽已成为事件抽取的关键技术,但在领域自适应性和召回率方面仍有很大的提升空间.
(1)结合深度学习技术进展的事件抽取研究. 事件抽取是在事件触发和论元识别的基础上发展起来的.它在某种程度上取决于事件类型、触发词识别和论元检测的效果,但是这些基础技术准确率不高.在深度学习技术被大规模使用后,事件抽取的效果得到了很大的提升.2015 年至今,该领域的研究热点集中于CNN、RNN、GAN、GCN 以及 Attention 机制、少样本学习、预训练技术等方法的研究,还有联合多种网络来进行事件抽取. 在事件抽取中,如何更有效地结合最新的深度学习技术进行抽取的研究是未来的一个重要趋势.
**(2)段落级和篇章级事件抽取的研究. **近几年的事件抽取工作主要聚集在利用深度学习方法进行句子级事件抽取,而实际应用时同一事件经常出现在不同句子中,这时需要通过整个篇章确定事件的具体情况.同时, 还存在抽取的事件信息不完整的问题,在日常应用中,我们经常要了解事件发生的全过程.现有基于深度学习的跨句子级事件抽取模型性能较差,但是段落甚至篇章级的事件抽取要求深度模型具有更复杂的推理能力、更高的准确率以及更好的灵活性,未来利用深度学习技术融合多个句子进行段落和篇章级事件抽取是一个重要的研究方向.
(3)面向特定领域事件抽取系统的设计与研究. 基于特征或传统机器学习的事件抽取方法,已经覆盖了多数可能的输入和特征,而基于深度学习的模型往往依赖网络的复杂程度带来对隐含事件信息挖掘性能的提升. 面向特定领域事件抽取系统的领域与深度学习技术更好的融合,进行可扩展性与可移植性的进一步提升是将来的关键研究内容.
(4)跨语言、跨领域的事件抽取的研究. 目前,事件抽取的水平还限制在对独立语言、单一领域的事件文本处理上,跨语言、跨领域的研究尚处于探索阶段.例如,在中文事件抽取的相关研究主要集中在生物医学、微博、新闻、紧急情况等方面,其他领域和跨语言事件抽取技术的研究很少.随着深度学习技术的进一步完善,跨语言、跨领域的事件抽取必将成为研究热点.
(5)事件抽取中的深度迁移学习的研究. 在事件抽取中,由于触发词特征和数据集注释的不同,可能无法在其他文本上很好地进行研究.尽管有一些迁移学习技术已应用在事件抽取的研究中,但涉及比较少.针对深度迁移学习技术的进一步研究,有利于我们开发一个健壮的识别器来识别不同领域的事件类型,探索事件抽取任务中的少样本、零样本学习,解决领域不匹配和跨域不匹配的问题.
(6)基于远程监督的事件抽取的深入研究. 为了缓解远程监督中经常会出现的错误标签问题,研究者们分别结合多示例学习、注意力机制、噪声建模等方法提出了多种模型,但如何建立更有效的方法缓解远程监督中错误标签的影响仍是事件抽取中研究的重点问题.
**4 结论及展望 **
在本文中,对深度学习中事件抽取技术进行了全面最新的概述.事件抽取发展至今,在研究内容上逐渐由单一领域向多领域、跨领域发展,事件类型的定义方式表示为由人工预先定义转变为事件类型自动发现、挖掘;在研究方法上,深度学习的方法在事件抽取任务的性能上表现良好,基于深度学习的框架日益成为主流,在此基础上结合远程监督、强化学习、少样本学习和零资源学习的思想等可以为事件抽取性能的提升提供新思路. 特别是,中文事件抽取的任务复杂,将深度学习的方法应用在其中,是今后需要努力的一个方向.

