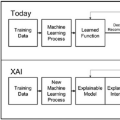
可解释性是构建可信人工智能系统的必要元素。来自普渡大学等几位学者在SIGMOD2022《可解释的人工智能》教程,130+PPT阐述XAI的基础、应用、机会,非常值得关注!

算法决策系统被成功地应用于各种领域的不同任务。虽然算法决策的潜在好处很多,但信任这些系统的重要性直到最近才引起关注。人们越来越担心这些系统复杂、不透明、不直观,因此难以信任。最近,人们对可解释人工智能(XAI)的兴趣重新升温。XAI旨在通过解释模型的行为、预测或两者兼有来减少模型的不透明性,从而使人类能够仔细检查并信任模型。近年来,针对模型的可解释性和透明性问题,出现了一系列的技术进步和解释方法。在本教程中,我们将介绍这些新颖的解释方法,描述它们的优势和局限性,将现有工作与数据库(DB)社区联系起来,并列举在XAI环境下进行数据管理研究的机会。
引言
人工智能(AI)系统越来越多地用于关键领域的决策,如医疗保健、刑事司法和金融。然而,这些系统的不透明性和复杂性构成了新的威胁。越来越多的人担心,这些系统的不透明可能会造成培训数据[37]中反映的系统性偏见和歧视,从而损害分布在不同社会阶层的利益攸关方。这些对透明度的呼吁重新激起了人们对可解释人工智能(XAI -参见[50]最近的一项调查)的兴趣,它旨在为算法决策系统的结果或过程提供人类可以理解的解释。
XAI方法的发展受到技术、社会和伦理目标的推动[9,14,36,38,44]: (1)通过建立对决策结果的信任,提高社会对基于机器学习(ML)的决策算法的接受程度;(2)为用户提供可操作的见解,以在未来改变算法的结果;(3)促进识别偏见和歧视等危害来源;(4)通过识别导致不利和意外行为的训练数据中的错误或偏差,提供调试ML算法和模型的能力。政府法规要求企业使用自动化决策系统向最终用户解释其决策,进一步加剧了这一问题的紧迫性[1,16]。最近,人们提出了几种方法来解释ML模型的行为或预测。这些方法可以大致分为以下几类:(a)可解释性是通过设计(内在)还是通过事后系统分析(外在)实现的,(b)方法是否假设访问系统内部(模型相关)或可以应用于任何黑箱算法系统(模型无关),以及(c)方法生成的解释是否迎合对单个实例的预测(局部),解释模型的整体行为(全局)或介于这两个极端之间。
在本教程中,我们将详细介绍当代XAI技术,并强调它们的优点和局限性。与现有的XAI教程相比,我们将在数据库社区的背景下讨论XAI的范围,并概述一组利用XAI进展的数据管理研究的挑战和机会,并为XAI研究的挑战做出贡献。本教程的学习结果如下。
- (1) 了解XAI技术的概况。
- (2) XAI技术与数据管理社区现有技术之间的联系。
- (3) 暴露之前XAI提案的关键漏洞,以及数据管理技术如何在许多情况下提供帮助。
- (4) 接触到一些新的机会,利用基于数据来源和因果推理的技术来解释模型行为和调试AI管道。

涵盖范围
根据现有XAI技术[50]生成的结果,可以根据多个维度来解释模型及其预测。目前有各种各样的技术可以解决这些可解释性的不同维度。例如,一些方法提供了代表用于训练模型的数据的特征的全面总结,一些返回数据点以使模型可解释,一些用固有的可解释模型来近似模型,等等。本教程分为五个主题,涵盖了这些不同维度的代表性技术。每个专题的内容总结如下。
2.1基于特征的解释
解释黑盒模型的一种常见方法是将模型输出的责任归因于它的输入。这种方法类似于提供输入特征的重要性。例如,在线性回归的情况下,学习线性方程中的特征的系数可以作为特征重要性的指标。为训练数据中的所有特征分配一个实数的最终目标可以通过多种方式实现。此外,该数字还可以表示该特征影响的程度和方向。我们将在本教程中介绍以下特征属性方法。
2.2 基于规则的解释
基于特征属性的方法为每个特征值分配一个实值重要性分数。相反,基于规则的解释生成一组规则作为对模型行为的解释。输出规则集满足一个共同属性,即只要遵守这些规则,模型就会提供一个特定的结果。理想情况下,这些规则应该简明扼要,并适用于大量数据点。较长的规则(超过5个从句)是不可理解的,而非常具体的规则是不可概括的。锚[54]是一种试图生成简短且广泛适用的规则的方法。它使用一种基于多武装匪徒的算法来搜索这些规则。Lakkaraju等人使用可解释的决策集来获得一组if-then规则,这些规则可以用来解释黑盒模型[43]。它们的目标函数旨在平衡和优化这些决策集的准确性和可解释性。
2.3 基于训练数据的解释
与特征归因方法相比,基于训练数据的方法将ML算法的输出归为训练数据集[10]的特定实例。基于数据的解释的核心思想是,训练数据影响模型,从而间接影响模型预测的结果。为了理解模型的预测,基于数据的解释可以将模型参数和预测追溯到用于训练模型的训练数据。这些方法不是根据数据的特征(例如,年龄,性别等),而是根据特定的数据点(例如,列举20个数据点负责特定的模型输出)来解释模型的行为。基于数据的解释有助于调试ML模型,理解和解释模型行为和模型预测。在本教程中,我们将介绍以下基于训练数据的方法。
2.4 对非结构化数据的解释
深度学习已经非常成功,特别是在图像分类和涉及图像和文本的语言翻译等任务中。尽管现有的XAI方法主要关注结构化数据,但在解释ML模型预测优于非结构化数据方面已经取得了重大进展。例如,对图像分类模型的解释可以在各种名称下找到,如敏感性地图、显著性地图、像素属性地图、基于梯度的属性方法、特征相关性、特征属性和特征贡献[50]。这些解释通常会根据输入像素对分类结果的重要性突出并排序。然而,单个像素可能对分类器的结果没有很大的直接影响,但可以通过贡献神经网络从原始像素学习到的抽象特征和概念,间接影响其结果。已有研究表明,这些方法的计算成本很高,而且极易引起误解、脆弱和不可靠[2,22,52]。类似地,可以将LIME[53]应用于文本数据,以识别解释文本分类模型结果的特定单词。计算机视觉中另一种流行的解释类型是反事实解释,这种解释是通过改变图像的最小区域产生的,从而导致分类结果的改变[72]。在本教程中,我们将关注结构化数据,因为它与DB社区更相关。
[1] 2016. Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation). (2016). [2] Julius Adebayo, Justin Gilmer, Michael Muelly, Ian J. Goodfellow, Moritz Hardt, and Been Kim. 2018. Sanity Checks for Saliency Maps. In Advances in NeuralInformation Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, Samy Bengio, Hanna M. Wallach, Hugo Larochelle, Kristen Grauman, Nicolò Cesa-Bianchi, and Roman Garnett (Eds.). 9525–9536. [3] Rakesh Agrawal, Tomasz Imieliński, and Arun Swami. 1993. Mining association rules between sets of items in large databases. In Proceedings of the 1993 ACM SIGMOD international conference on Management of data. 207–216. [4] Rakesh Agrawal, Ramakrishnan Srikant, et al. 1994. Fast algorithms for mining association rules. PVLDB.