

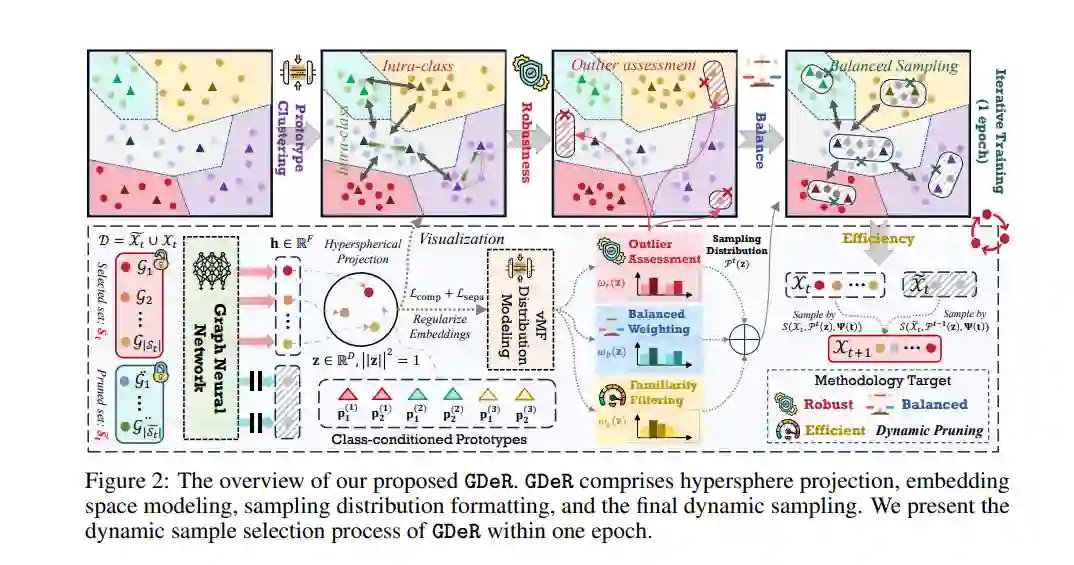
训练高质量的深度模型需要大量的数据,这会导致巨大的计算和内存需求。近年来,数据剪枝、蒸馏和核心集选择等方法被开发出来,以通过保留、合成或从完整数据集中选择一个小而信息丰富的子集来简化数据量。在这些方法中,数据剪枝带来的额外训练成本最低,并提供了最实际的加速效果。然而,它也是最脆弱的,往往在数据不平衡或数据模式偏差的情况下遭遇显著的性能下降,因此在设备端部署时,其准确性和可靠性引发了担忧。因此,迫切需要一种新的数据剪枝范式,既能保持现有方法的效率,又能确保平衡性和鲁棒性。与计算机视觉和自然语言处理领域中已开发出成熟的解决方案不同,图神经网络(GNN)在应对日益大规模、不平衡和噪声数据集时仍面临挑战,缺乏统一的数据集剪枝解决方案。 为此,我们提出了一种新的动态软剪枝方法——GDeR,该方法通过可训练的原型在训练过程中动态更新训练“篮子”。GDeR首先构建一个经过良好建模的图嵌入超球体,然后从该嵌入空间中抽取具有代表性、平衡且无偏的子集,达到我们所称的图训练调试(Graph Training Debugging)目标。在五个数据集和三个GNN骨干网络上的广泛实验表明,GDeR (I) 在减少30%至50%的训练样本的情况下,仍能达到或超越完整数据集的性能;(II) 实现了最高2.81倍的无损训练加速;(III) 在不平衡训练和噪声训练场景中,比最新的剪枝方法分别提高了0.3%至4.3%和3.6%至7.8%的性能提升。源代码可在https://github.com/ins1stenc3/GDeR获取。
成为VIP会员查看完整内容
相关内容
Arxiv
225+阅读 · 2023年4月7日
相关主题


相关VIP内容
相关资讯
相关论文
Arxiv
225+阅读 · 2023年4月7日