

近年来,大语言模型(LLMs)的快速发展推动了对多种应用的关注,这些应用依赖于强大的长程建模能力,以便处理大规模输入上下文并持续生成较长的输出。随着序列长度的增加,LLM中的键值对(Key-Value, KV)数量也随之增长,形成了严重的效率瓶颈。
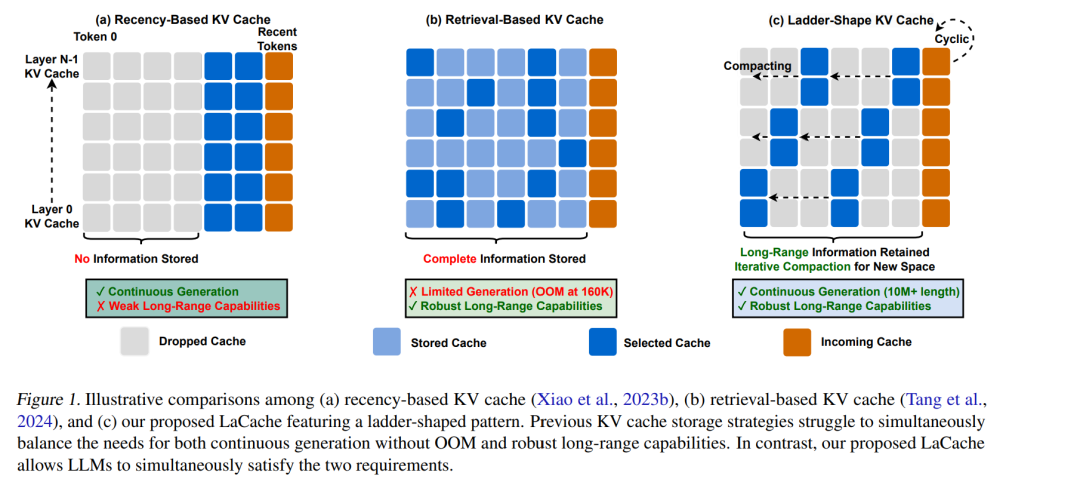
本文提出了一种全新的 KV 缓存优化范式——LaCache,这是一种无需训练、用于提升 LLM 生成推理效率与精度的方法。LaCache 使 LLM 能够同时应对长程建模中的两大关键挑战:增强的长程建模能力以及在不触发内存溢出(OOM)的前提下实现持续生成。 具体而言,LaCache 包含两项核心创新:
梯状 KV 缓存结构(ladder-shaped KV cache pattern):该结构不仅在每一层内部按照顺序(从左至右)存储 KV 对,还在不同层之间(从浅层到深层)进行跨层存储,在固定的存储预算下扩大了可建模的依赖范围,从而显著提升了长程建模能力; 1. 迭代压缩机制(iterative compaction mechanism):该机制能够逐步压缩旧的缓存内容,为新生成的 token 腾出空间。这种基于 token 距离的动态压缩方式,使得在缓存空间受限的情况下实现更高效的持续生成成为可能。
我们在多个任务、基准测试和不同 LLM 模型上进行了实证研究,结果一致验证了 LaCache 在增强大语言模型长程能力方面的有效性。 我们的代码开源于:https://github.com/GATECHEIC/LaCache
成为VIP会员查看完整内容
相关内容
Arxiv
40+阅读 · 2023年4月19日
Arxiv
213+阅读 · 2023年4月7日
Arxiv
81+阅读 · 2023年4月4日
Arxiv
145+阅读 · 2023年3月29日

相关VIP内容
相关资讯
相关论文
Arxiv
40+阅读 · 2023年4月19日
Arxiv
213+阅读 · 2023年4月7日
Arxiv
81+阅读 · 2023年4月4日
Arxiv
145+阅读 · 2023年3月29日