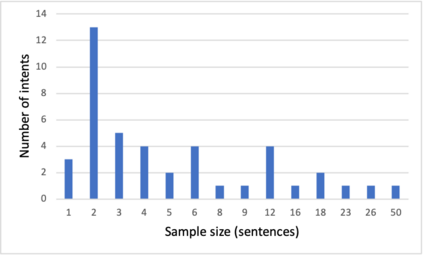
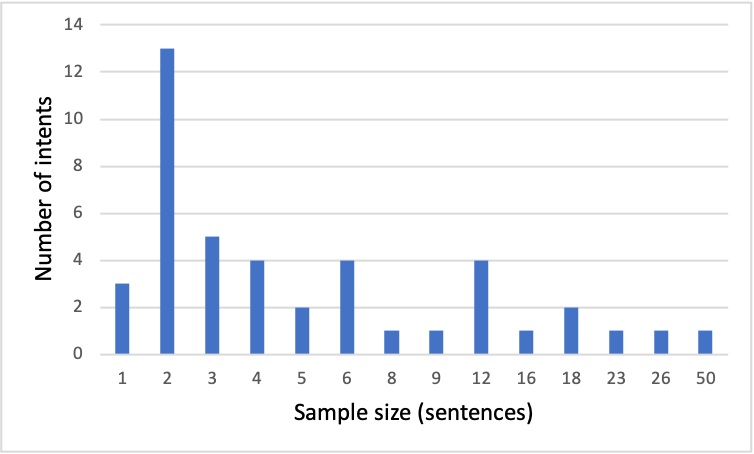
This paper presents key principles and solutions to the challenges faced in designing a domain-specific conversational agent for the legal domain. It includes issues of scope, platform, architecture and preparation of input data. It provides functionality in answering user queries and recording user information including contact details and case-related information. It utilises deep learning technology built upon Amazon Web Services (AWS) LEX in combination with AWS Lambda. Due to lack of publicly available data, we identified two methods including crowdsourcing experiments and archived enquiries to develop a number of linguistic resources. This includes a training dataset, set of predetermined responses for the conversational agent, a set of regression test cases and a further conversation test set. We propose a hierarchical bot structure that facilitates multi-level delegation and report model accuracy on the regression test set. Additionally, we highlight features that are added to the bot to improve the conversation flow and overall user experience.
翻译:本文介绍了在设计法律领域特定领域对话工具方面面临的挑战的主要原则和解决办法,包括范围、平台、架构和输入数据编制等问题,提供了回答用户询问和记录用户信息的功能,包括联系细节和与案件有关的信息,利用亚马逊网络服务(AWS)LEX和AWS Lambda共同开发的深层学习技术,由于缺乏公开数据,我们确定了两种方法,包括众包实验和存档查询,以开发一些语言资源,其中包括培训数据集、一套对谈话代理的预先反应、一套回归测试案例和一套进一步的对话测试。我们建议了一个等级机器人结构,以便利多层次的代表团授权,并报告回归测试集的模型准确性。此外,我们强调在机器人中增加的特征,以改善对话流量和总体用户经验。