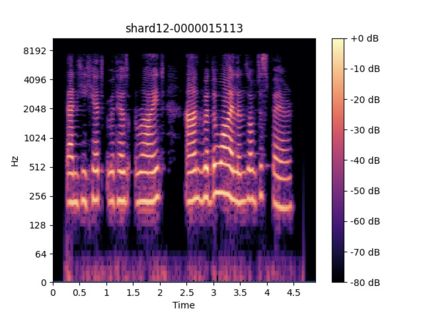
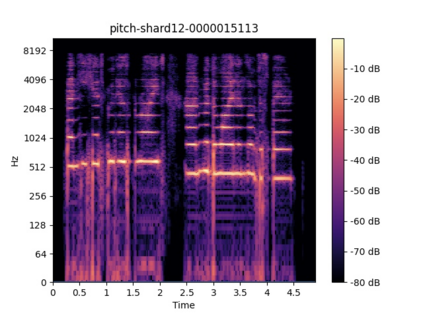
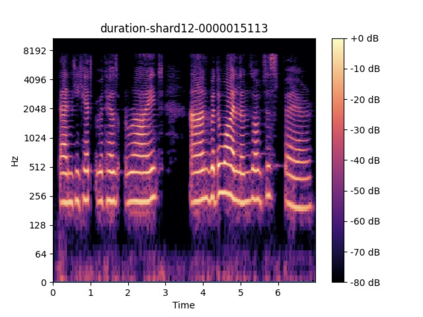
Automatic lyrics transcription (ALT), which can be regarded as automatic speech recognition (ASR) on singing voice, is an interesting and practical topic in academia and industry. ALT has not been well developed mainly due to the dearth of paired singing voice and lyrics datasets for model training. Considering that there is a large amount of ASR training data, a straightforward method is to leverage ASR data to enhance ALT training. However, the improvement is marginal when training the ALT system directly with ASR data, because of the gap between the singing voice and standard speech data which is rooted in music-specific acoustic characteristics in singing voice. In this paper, we propose PDAugment, a data augmentation method that adjusts pitch and duration of speech at syllable level under the guidance of music scores to help ALT training. Specifically, we adjust the pitch and duration of each syllable in natural speech to those of the corresponding note extracted from music scores, so as to narrow the gap between natural speech and singing voice. Experiments on DSing30 and Dali corpus show that the ALT system equipped with our PDAugment outperforms previous state-of-the-art systems by 5.9% and 18.1% WERs respectively, demonstrating the effectiveness of PDAugment for ALT.
翻译:自动歌词转录(ALT)可被视为对歌声的自动语音识别(ASR),是学术界和产业界一个有趣和实用的主题,没有很好地开发该词,主要是因为缺乏配对的歌声和歌词数据集,用于示范培训;考虑到有大量的ASR培训数据,一个直接的方法是利用ASR数据来提高ALT培训;然而,如果直接用ASR数据对ALT系统进行ASR数据培训,由于歌声和标准语音数据之间存在根植于歌声中音乐特定声学特点的差别,这一系统的进展是微不足道的。在本文件中,我们提议了PDaugment,这是一种数据增强方法,在音乐评分的指导下,在可调级别上调整演讲的音调和持续时间,以帮助ALT培训。具体地说,我们调整了每个自然歌词中的音调的音调和持续时间,与从音乐评分中提取的相应音调的音调之间的距离是微不足道的,以便缩小自然言词与歌声声音之间的差距。DSing30和Daliamp对D的实验显示,配备我们PDAUGUG的系统配备了我们PDAUG1和18-LT的效能,分别展示了18-LT的18-LT的系统。