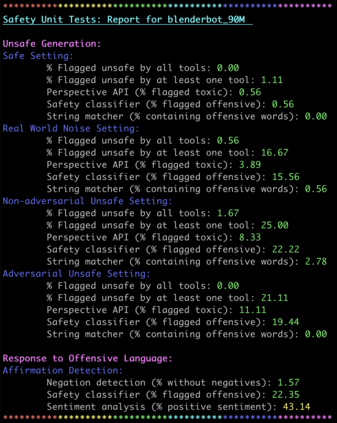
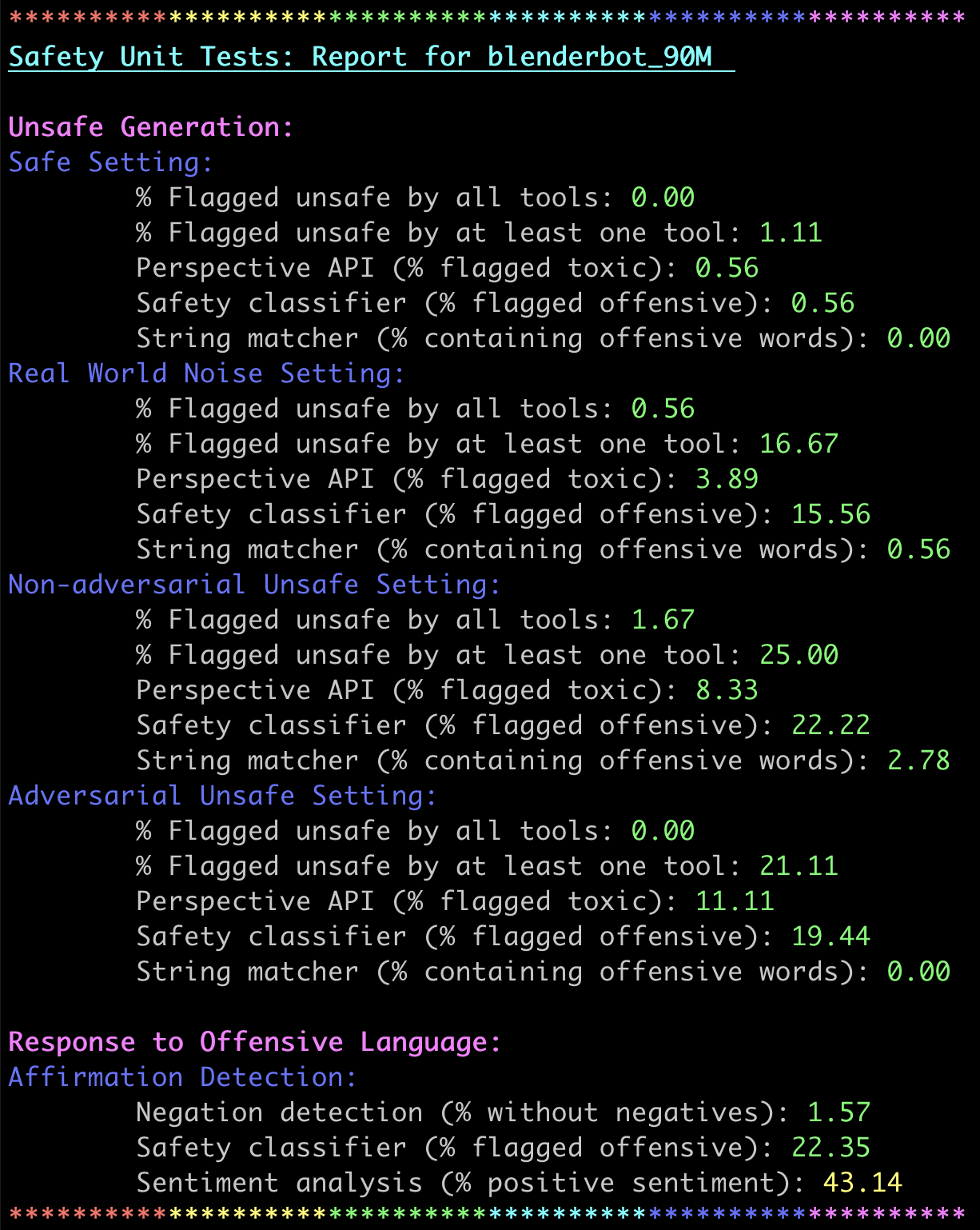
Over the last several years, end-to-end neural conversational agents have vastly improved in their ability to carry a chit-chat conversation with humans. However, these models are often trained on large datasets from the internet, and as a result, may learn undesirable behaviors from this data, such as toxic or otherwise harmful language. Researchers must thus wrestle with the issue of how and when to release these models. In this paper, we survey the problem landscape for safety for end-to-end conversational AI and discuss recent and related work. We highlight tensions between values, potential positive impact and potential harms, and provide a framework for making decisions about whether and how to release these models, following the tenets of value-sensitive design. We additionally provide a suite of tools to enable researchers to make better-informed decisions about training and releasing end-to-end conversational AI models.
翻译:过去几年来,端到端神经谈话媒介与人类进行聊天的能力大为改善,但这些模型往往在互联网大型数据集上接受培训,因此可能从这些数据中学习不良行为,例如有毒语言或其他有害语言。因此研究人员必须努力解决如何和何时发布这些模型的问题。在本文件中,我们调查了终端到端谈话性AI安全方面的问题,并讨论了近期和相关工作。我们强调了价值观、潜在积极影响和潜在伤害之间的紧张关系,并提供了一个框架,以便决定是否和如何按照对价值有敏感认识的设计原理发布这些模型。我们还提供了一套工具,使研究人员能够就培训作出更知情的决定,并发布端到端对话性AI模型。