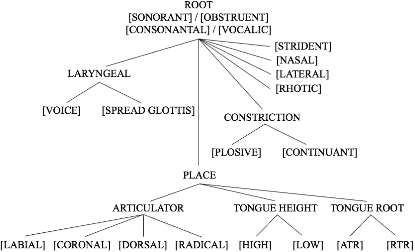
This study investigates whether phonological features can be applied in text-to-speech systems to generate native and non-native speech in English and Mandarin. We present a mapping of ARPABET/pinyin to SAMPA/SAMPA-SC and then to phonological features. We tested whether this mapping could lead to the successful generation of native, non-native, and code-switched speech in the two languages. We ran two experiments, one with a small dataset and one with a larger dataset. The results proved that phonological features could be used as a feasible input system, although further investigation is needed to improve model performance. The accented output generated by the TTS models also helps with understanding human second language acquisition processes.
翻译:这项研究调查了文字到语音系统是否可以应用声学特征来生成英语和普通话的本地和非本地话语。我们向SAMPA/SAMPA-SC和随后的声学特征展示了ARPABET/pinyin的绘图图。我们测试了这一绘图图是否能成功生成两种语言的本地、非本地和代码转换的语音。我们进行了两次实验,一次是小数据集,另一次是大数据集。结果证明,声学特征可以作为一种可行的输入系统使用,尽管还需要进一步调查才能改进模型性能。TTS模型的突出产出也有助于理解人类第二语言获取过程。