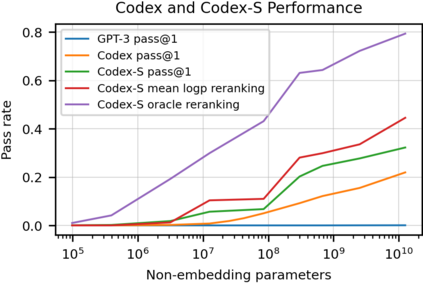
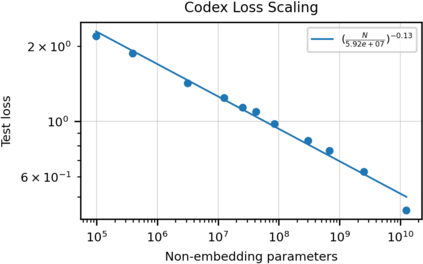
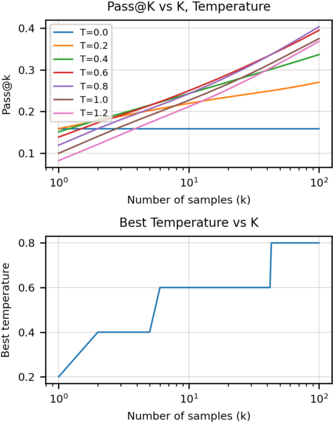
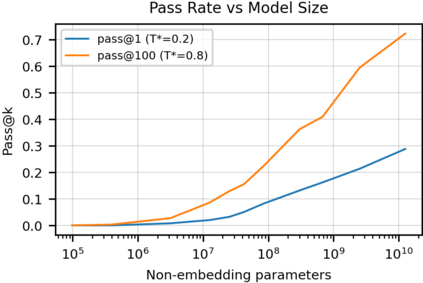
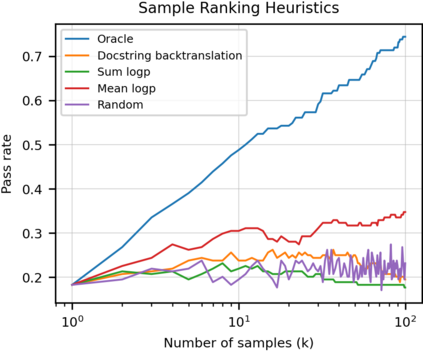
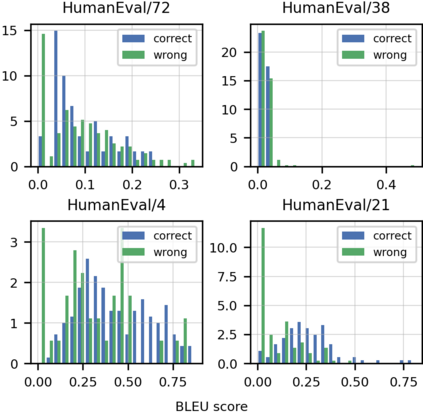
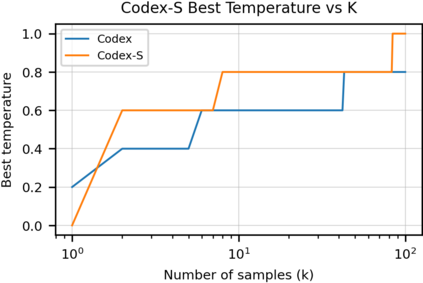
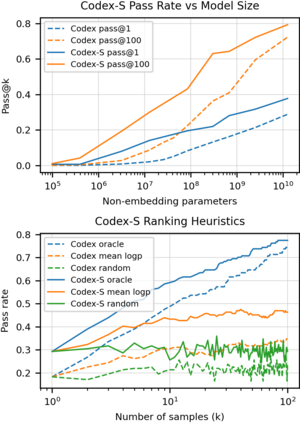
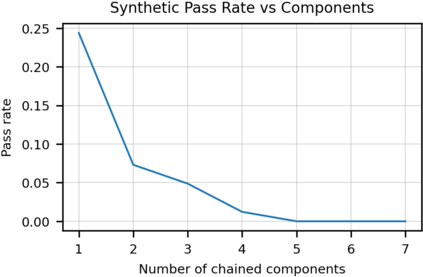
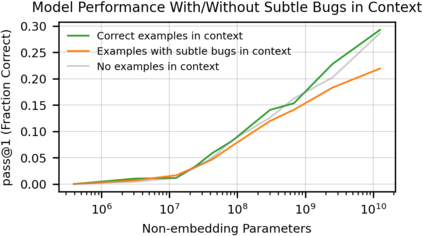
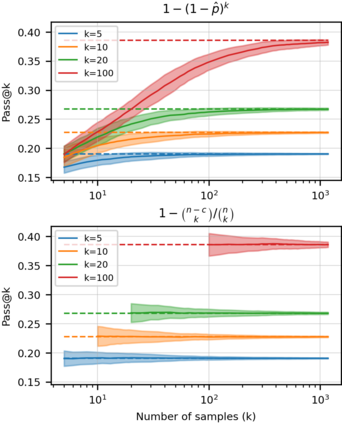
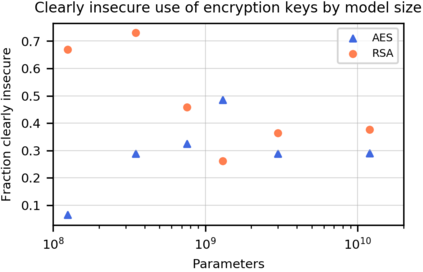
We introduce Codex, a GPT language model fine-tuned on publicly available code from GitHub, and study its Python code-writing capabilities. A distinct production version of Codex powers GitHub Copilot. On HumanEval, a new evaluation set we release to measure functional correctness for synthesizing programs from docstrings, our model solves 28.8% of the problems, while GPT-3 solves 0% and GPT-J solves 11.4%. Furthermore, we find that repeated sampling from the model is a surprisingly effective strategy for producing working solutions to difficult prompts. Using this method, we solve 70.2% of our problems with 100 samples per problem. Careful investigation of our model reveals its limitations, including difficulty with docstrings describing long chains of operations and with binding operations to variables. Finally, we discuss the potential broader impacts of deploying powerful code generation technologies, covering safety, security, and economics.
翻译:我们引入了GPT语言模型Codx, 这个模型根据GitHub的公开代码进行了微调, 并研究了它的 Python 代码写法能力。 一个独特的生产版本的 Codex 权力 GitHub Copilot。 在HumanEval 上, 一个新的评估设定了我们发布来测量从 Docstring 中合成程序功能的正确性, 我们的模式解决了28.8%的问题, 而 GPT-3 解决了0%, GPT-J 解决了11.4% 。 此外, 我们发现从这个模型中反复取样是一个令人惊讶的有效战略, 用来为困难的提示提供工作解决方案。 使用这个方法, 我们用每个问题100个样本解决了70.2%的问题。 对我们的模型的仔细调查揭示了它的局限性, 包括用 docstring描述长的操作链和约束操作到变量的操作的困难。 最后, 我们讨论了使用强大的代码生成技术的潜在更广泛影响, 包括安全、 安全和经济。