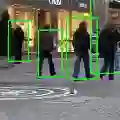
Detecting pedestrians accurately in urban scenes is significant for realistic applications like autonomous driving or video surveillance. However, confusing human-like objects often lead to wrong detections, and small scale or heavily occluded pedestrians are easily missed due to their unusual appearances. To address these challenges, only object regions are inadequate, thus how to fully utilize more explicit and semantic contexts becomes a key problem. Meanwhile, previous context-aware pedestrian detectors either only learn latent contexts with visual clues, or need laborious annotations to obtain explicit and semantic contexts. Therefore, we propose in this paper a novel approach via Vision-Language semantic self-supervision for context-aware Pedestrian Detection (VLPD) to model explicitly semantic contexts without any extra annotations. Firstly, we propose a self-supervised Vision-Language Semantic (VLS) segmentation method, which learns both fully-supervised pedestrian detection and contextual segmentation via self-generated explicit labels of semantic classes by vision-language models. Furthermore, a self-supervised Prototypical Semantic Contrastive (PSC) learning method is proposed to better discriminate pedestrians and other classes, based on more explicit and semantic contexts obtained from VLS. Extensive experiments on popular benchmarks show that our proposed VLPD achieves superior performances over the previous state-of-the-arts, particularly under challenging circumstances like small scale and heavy occlusion. Code is available at https://github.com/lmy98129/VLPD.
翻译:在城市场景中准确检测行人对于自动驾驶或视频监控等实际应用至关重要。但是,混淆人类的物品通常会导致错误的检测,小规模或大量遮挡的行人由于其不寻常的外观容易被忽略。为了应对这些挑战,仅使用对象区域是不足的,因此如何充分利用更明确的语义上下文成为了一个关键问题。同时,先前的上下文感知行人检测器只学习具有视觉线索的潜在上下文,或者需要通过繁琐的注释获得明确的语义上下文。因此,在本文中我们提出了一种新颖的方法,即基于视觉语义自监督学习的上下文感知行人检测(VLPD),通过视觉语言模型自动生成语义类别的显式标签来明确地建模语义上下文,而无需任何额外的注释。首先,我们提出了一种自监督的视觉语义(VLS)分割方法,该方法通过自动生成的显式语义类别标签学习了完全监督型行人检测和上下文分割。此外,我们提出了一种自监督的原型语义对比学习方法,基于从VLS获得的更明确的语义上下文,更好地区分行人和其他类别。在流行的基准测试上进行的大量实验表明,我们提出的VLPD在先前的最新技术水平上表现出卓越的性能,特别是在小规模和大量遮挡的挑战性环境中。代码可在https://github.com/lmy98129/VLPD上获得。