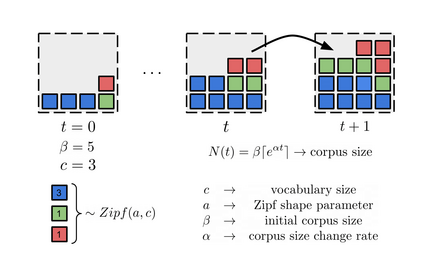
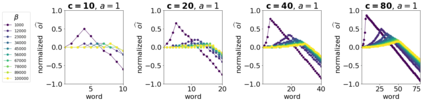
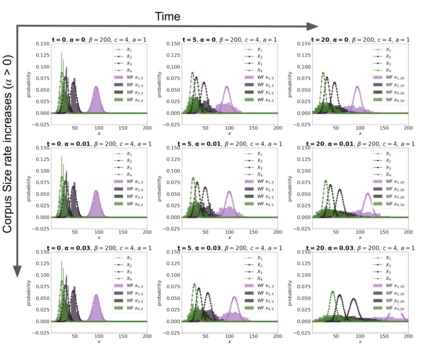
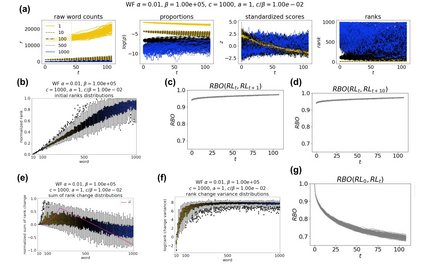
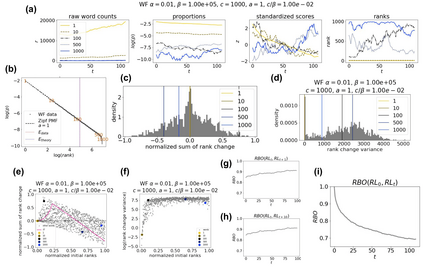
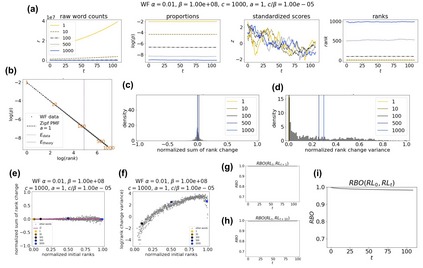
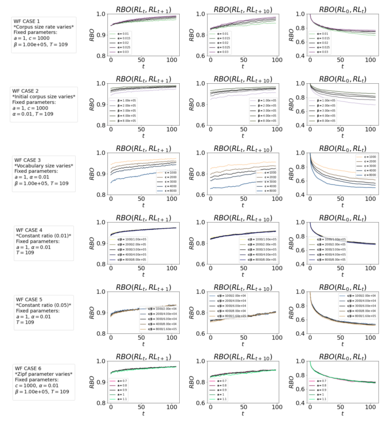
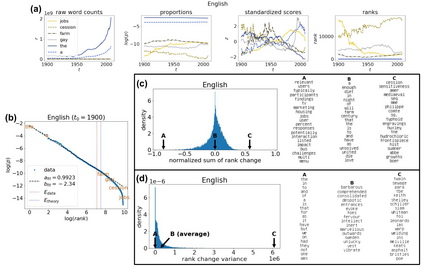
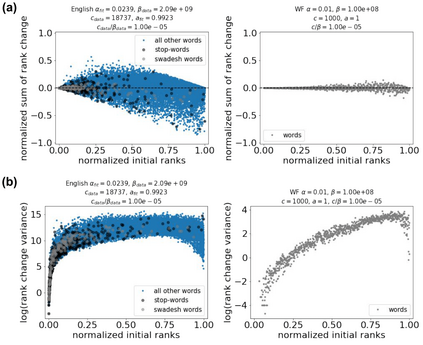
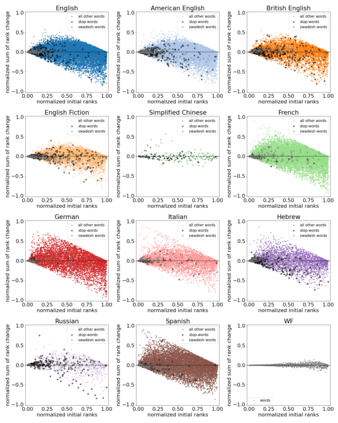
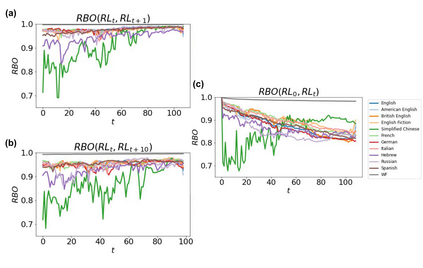
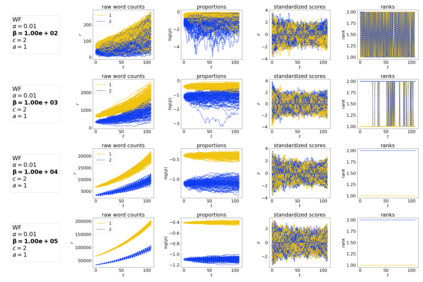
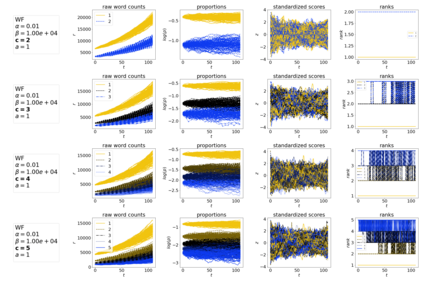
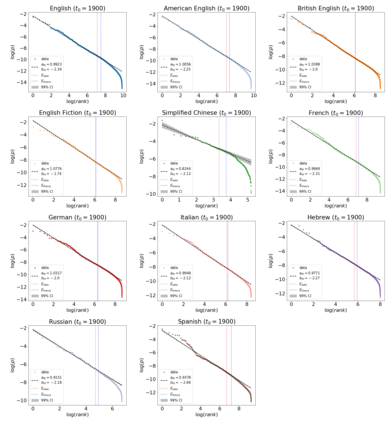
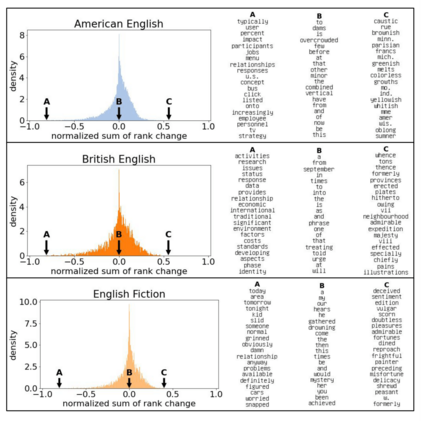
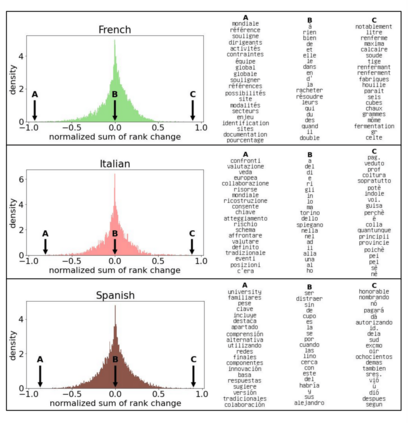
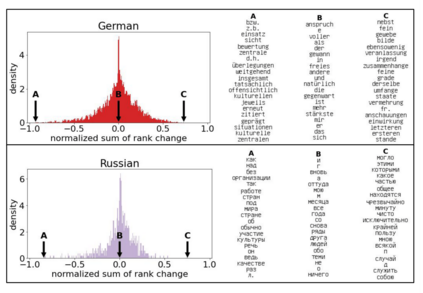
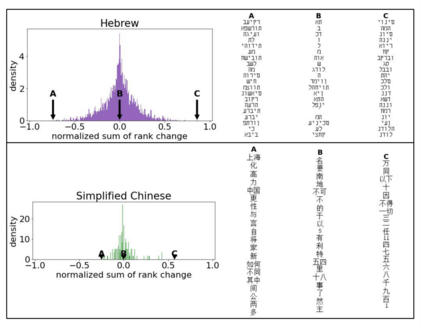
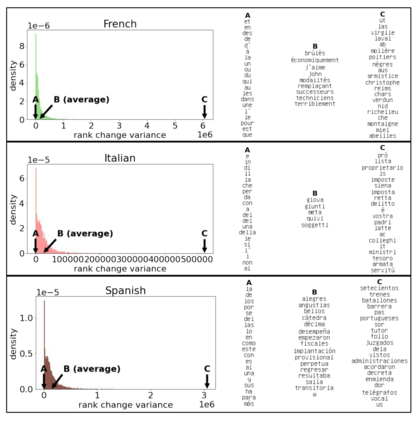
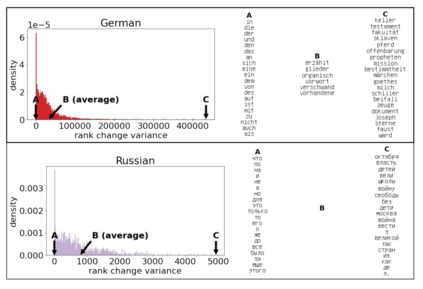
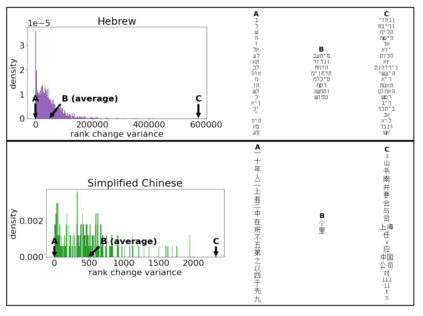
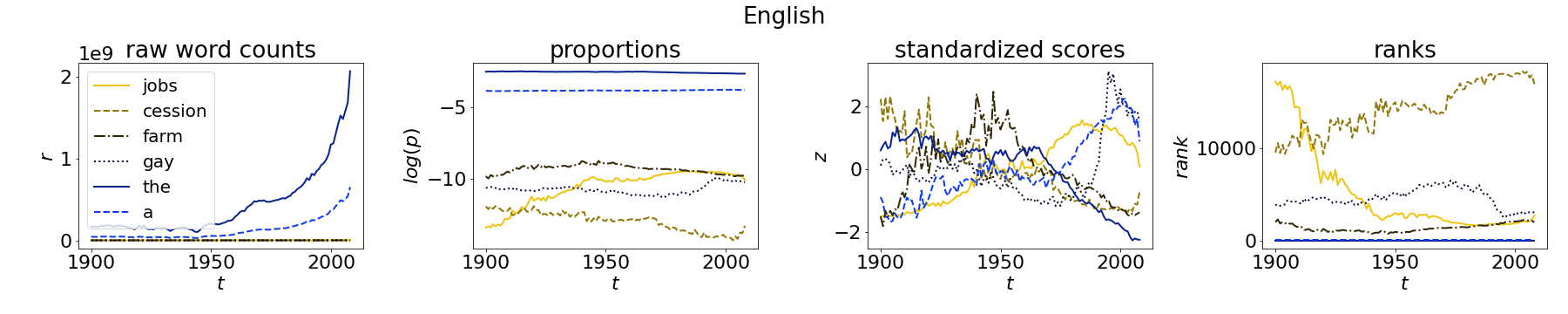
The availability of large linguistic data sets enables data-driven approaches to study linguistic change. This work explores the word rank dynamics of eight languages by investigating the Google Books corpus unigram frequency data set. We observed the rank changes of the unigrams from 1900 to 2008 and compared it to a Wright-Fisher inspired model that we developed for our analysis. The model simulates a neutral evolutionary process with the restriction of having no disappearing words. This work explains the mathematical framework of the model - written as a Markov Chain with multinomial transition probabilities - to show how frequencies of words change in time. From our observations in the data and our model, word rank stability shows two types of characteristics: (1) the increase/decrease in ranks are monotonic, or (2) the average rank stays the same. Based on our model, high-ranked words tend to be more stable while low-ranked words tend to be more volatile. Some words change in ranks in two ways: (a) by an accumulation of small increasing/decreasing rank changes in time and (b) by shocks of increase/decrease in ranks. Most of the stopwords and Swadesh words are observed to be stable in ranks across eight languages. These signatures suggest unigram frequencies in all languages have changed in a manner inconsistent with a purely neutral evolutionary process.
翻译:大型语言数据集的可用性使得以数据驱动的方式来研究语言变化。 这项工作通过调查Google Books Pasper ungram频率数据集来探索八种语言的字级动态。 我们观察了从1900年到2008年单数的级别变化,并将其与我们为分析而开发的Wright- Fisher启发型模型进行了比较。 模型模拟了一个中立的进化过程, 限制没有消失的单词。 这项工作解释了模型的数学框架 — 写成具有多重过渡概率的Markov链条 — 以显示文字在时间上的频率变化。 从我们在数据和模型中的观察看, 字级稳定性显示了两种特征:(1) 单调的军衔增加/减少, 或者说普通军衔保持不变。 根据我们的模型, 高调的单调的词往往更加稳定, 而低调的单词则比较不稳定。 以两种方式排列的词级变化:(a) 通过在时间上小增/定级的变化,以及(b) 通过在级别上增/降级的冲击, 单级显示两种特性的特性。 多数中阶语言在纯级中, 级的顺序上显示的是, 不变的顺序是稳定的顺序。