
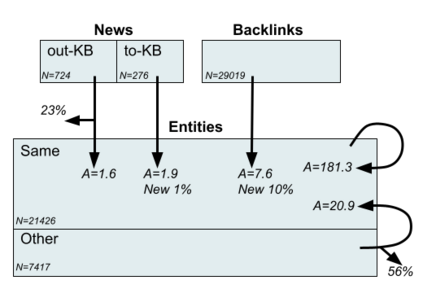
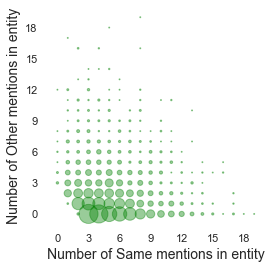
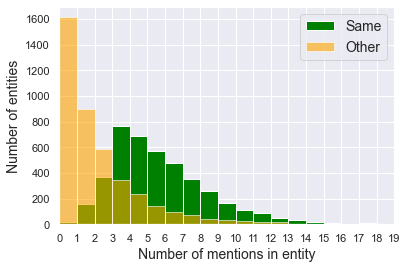
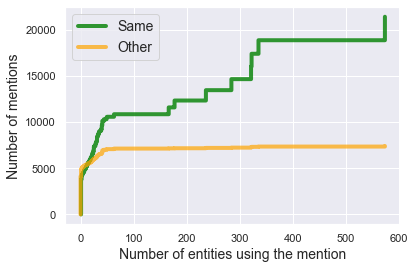
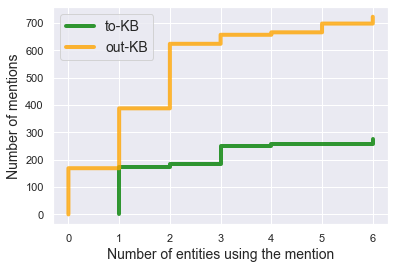
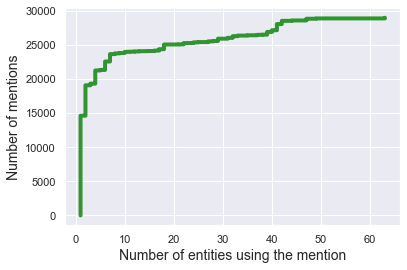
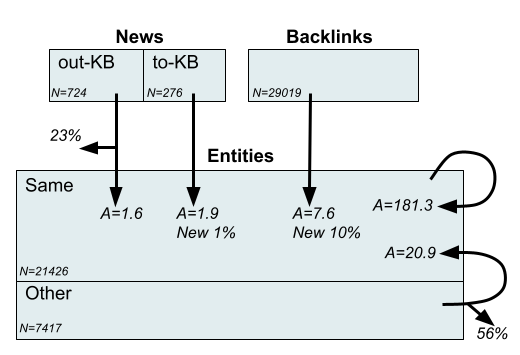
We present Namesakes, a dataset of ambiguously named entities obtained from English-language Wikipedia and news articles. It consists of 58862 mentions of 4148 unique entities and their namesakes: 1000 mentions from news, 28843 from Wikipedia articles about the entity, and 29019 Wikipedia backlink mentions. Namesakes should be helpful in establishing challenging benchmarks for the task of named entity linking (NEL).
翻译:我们展示了从英语维基百科获得的、名称不明的实体和新闻文章的数据集 " 名魔 ",其中58862人提到4148个独特实体及其名称:1 000人从新闻中提及,28843人从维基百科文章中提及该实体,29019人从维基百科回链接中提及。 名魔应有助于为名称实体连接任务(NEL)制定具有挑战性的基准。
相关内容
Arxiv
4+阅读 · 2021年6月1日




相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2021年6月1日