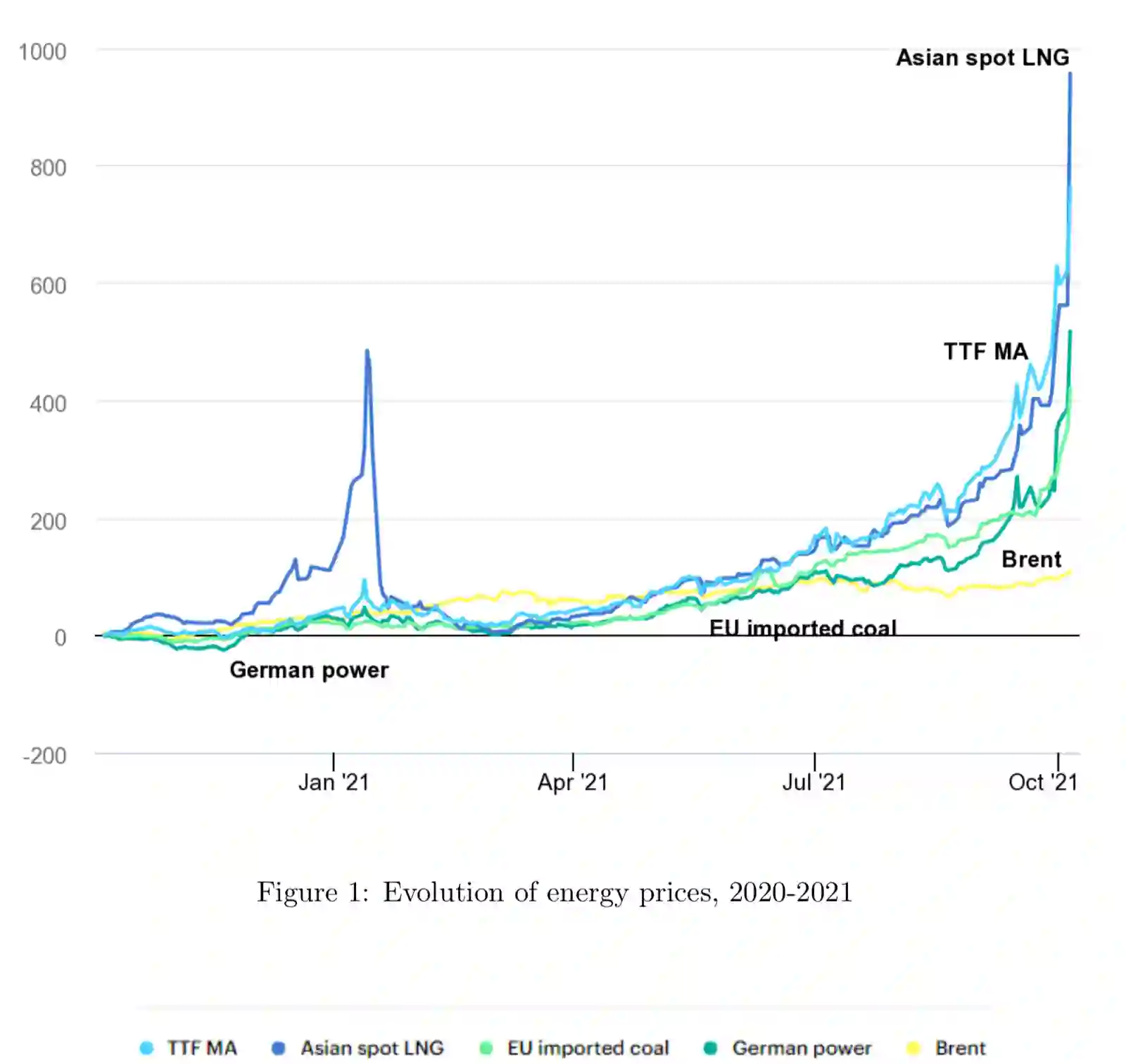
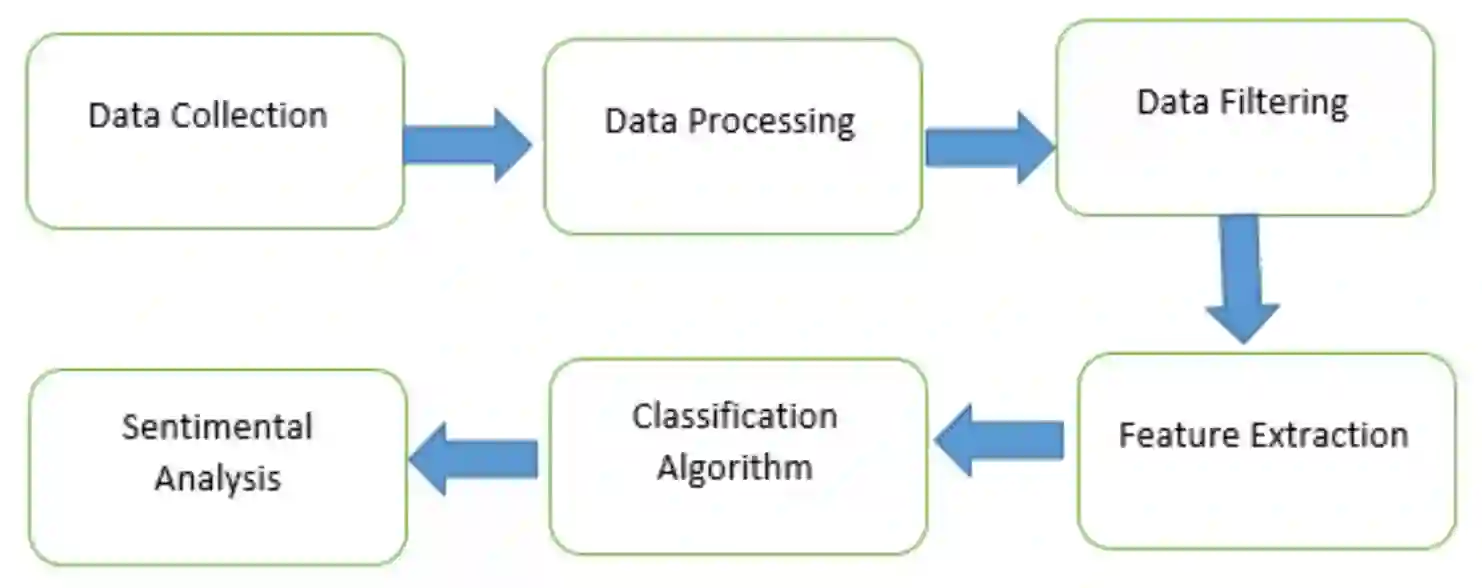
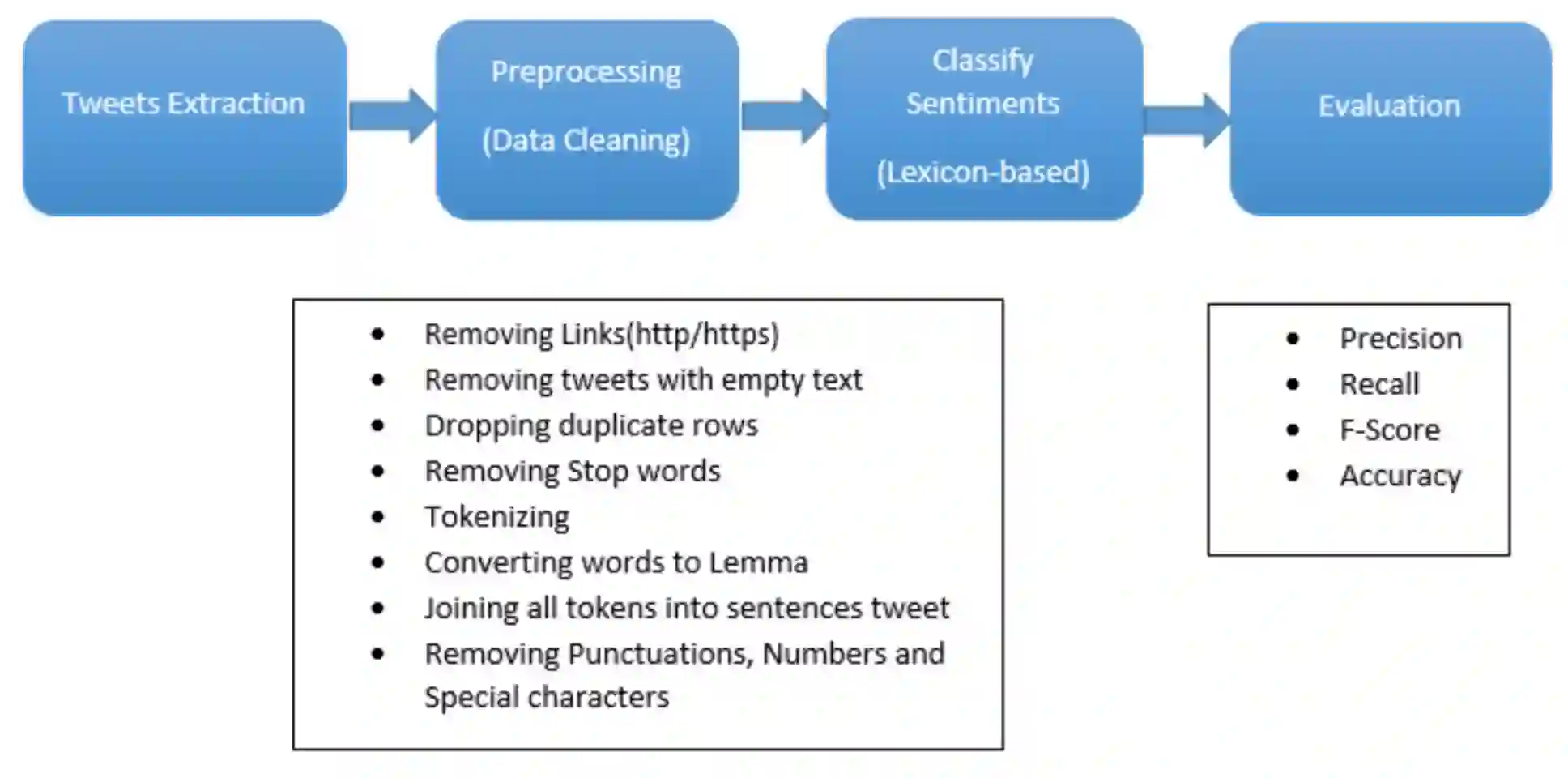
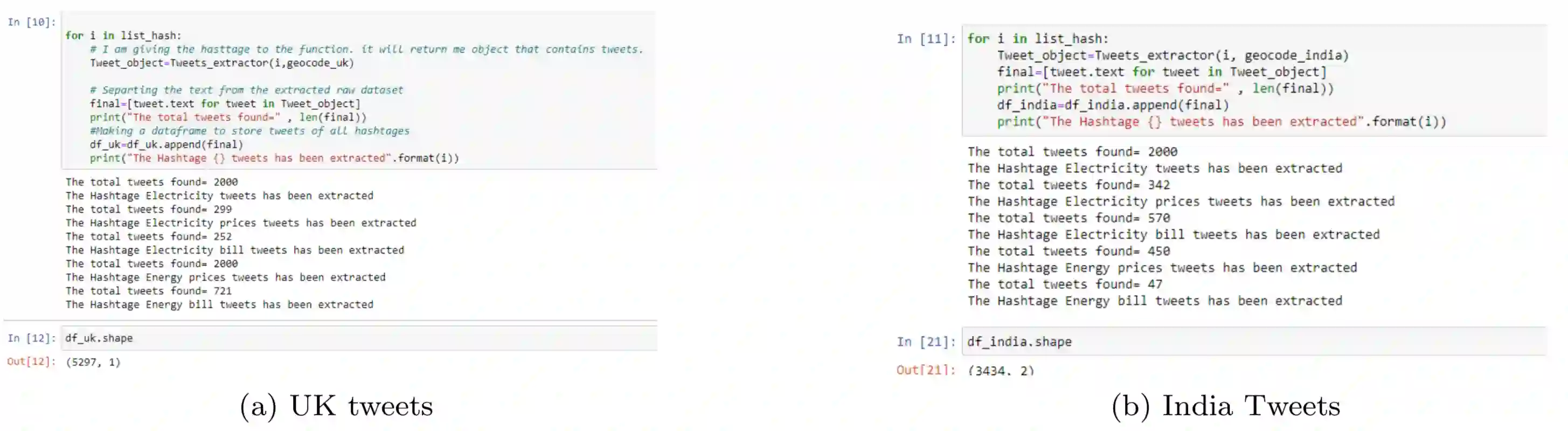
In today's world, everyone is expressive in some way, and the focus of this project is on people's opinions about rising electricity prices in United Kingdom and India using data from Twitter, a micro-blogging platform on which people post messages, known as tweets. Because many people's incomes are not good and they have to pay so many taxes and bills, maintaining a home has become a disputed issue these days. Despite the fact that Government offered subsidy schemes to compensate people electricity bills but it is not welcomed by people. In this project, the aim is to perform sentiment analysis on people's expressions and opinions expressed on Twitter. In order to grasp the electricity prices opinion, it is necessary to carry out sentiment analysis for the government and consumers in energy market. Furthermore, text present on these medias are unstructured in nature, so to process them we firstly need to pre-process the data. There are so many feature extraction techniques such as Bag of Words, TF-IDF (Term Frequency-Inverse Document Frequency), word embedding, NLP based features like word count. In this project, we analysed the impact of feature TF-IDF word level on electricity bills dataset of sentiment analysis. We found that by using TF-IDF word level performance of sentiment analysis is 3-4 higher than using N-gram features. Analysis is done using four classification algorithms including Naive Bayes, Decision Tree, Random Forest, and Logistic Regression and considering F-Score, Accuracy, Precision, and Recall performance parameters.
翻译:在今天的世界上,每个人都以某种方式表达,而这个项目的重点是人们对于英国和印度电价上涨的看法,使用Twitter的数据。Twitter是一个微博客平台,人们在Twitter上发布信息,称为Twitter。因为许多人的收入不高,他们必须支付如此多的税费和账单,因此维持家用已成为一个有争议的问题。尽管政府提供补贴计划来补偿人们的电费,但人们并不欢迎。在这个项目中,目的是对人们在Twitter上表达的电价和观点进行情绪分析。为了了解电价的意见,有必要对政府和能源市场上的消费者进行情绪分析。此外,这些媒体的文本在性质上是不结构化的,因此我们首先需要处理他们的数据。有很多特效提取技术,如《文字袋》、TF-IDF(定期文件频率)、词嵌入式、NLP(NLP)等词的特征。在这个项目中,我们用NTF-R-DFS(ReDF)字级数据分析方式分析,我们用4次的准确性数据分析,我们用ReDFDF字级数据分析结果分析,我们做了。