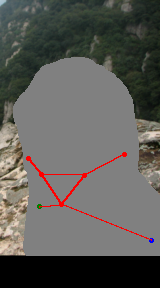
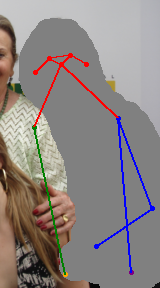
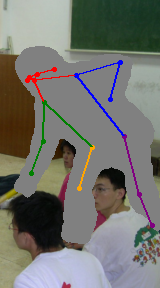
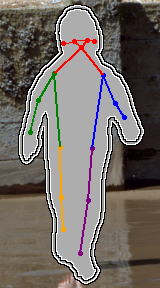
We address the task of in-the-wild human figure synthesis, where the primary goal is to synthesize a full body given any region in any image. In-the-wild human figure synthesis has long been a challenging and under-explored task, where current methods struggle to handle extreme poses, occluding objects, and complex backgrounds. Our main contribution is TriA-GAN, a keypoint-guided GAN that can synthesize Anyone, Anywhere, in Any given pose. Key to our method is projected GANs combined with a well-crafted training strategy, where our simple generator architecture can successfully handle the challenges of in-the-wild full-body synthesis. We show that TriA-GAN significantly improves over previous in-the-wild full-body synthesis methods, all while requiring less conditional information for synthesis (keypoints vs. DensePose). Finally, we show that the latent space of \methodName is compatible with standard unconditional editing techniques, enabling text-guided editing of generated human figures.
翻译:我们解决了自然场景下人物合成的问题,其中主要目标是给定任何图像的任何区域,合成完整的人物。在自然场景下的人物合成一直是一个具有挑战性和不被充分研究的任务,目前的方法难以处理极端姿势、遮挡物和复杂的背景。我们的主要贡献是TriA-GAN,这是一个关键点引导的GAN模型,可以合成任何人、任何地方、任何给定的姿势。我们方法的关键是投影GAN相结合的良好训练策略,我们的简单生成器体系结构可以成功处理自然场景下全身合成的挑战。我们表明,TriA-GAN显着改善了以前的自然场景下全身合成方法,同时需要更少的条件信息进行合成(关键点与DensePose相比)。最后,我们表明,TriA-GAN的潜在空间与标准的无条件编辑技术相兼容,可以实现对生成人物的文本指导编辑。