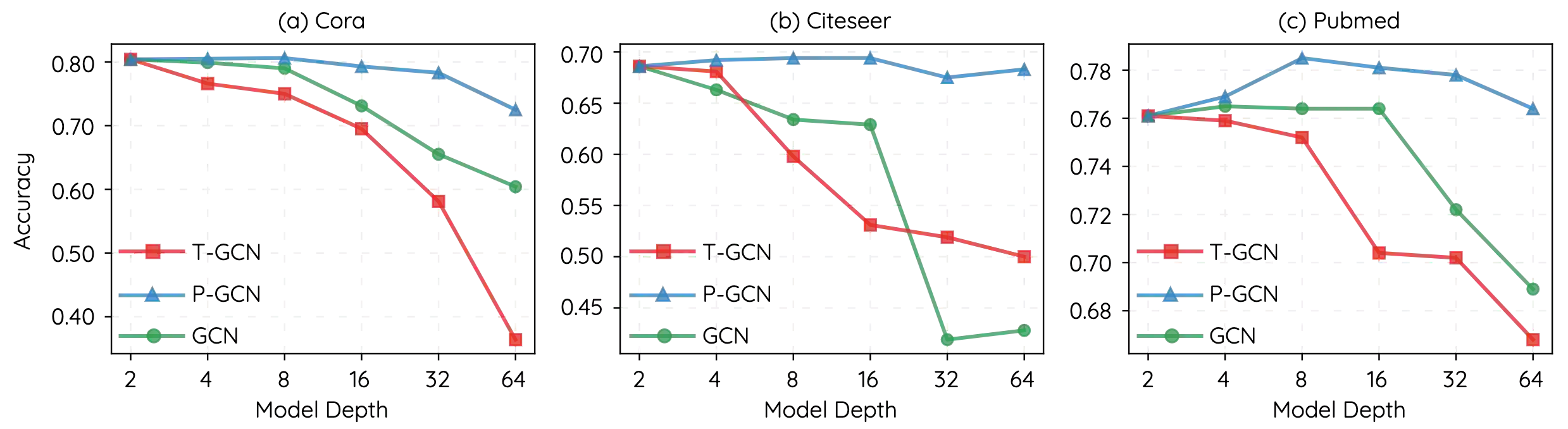
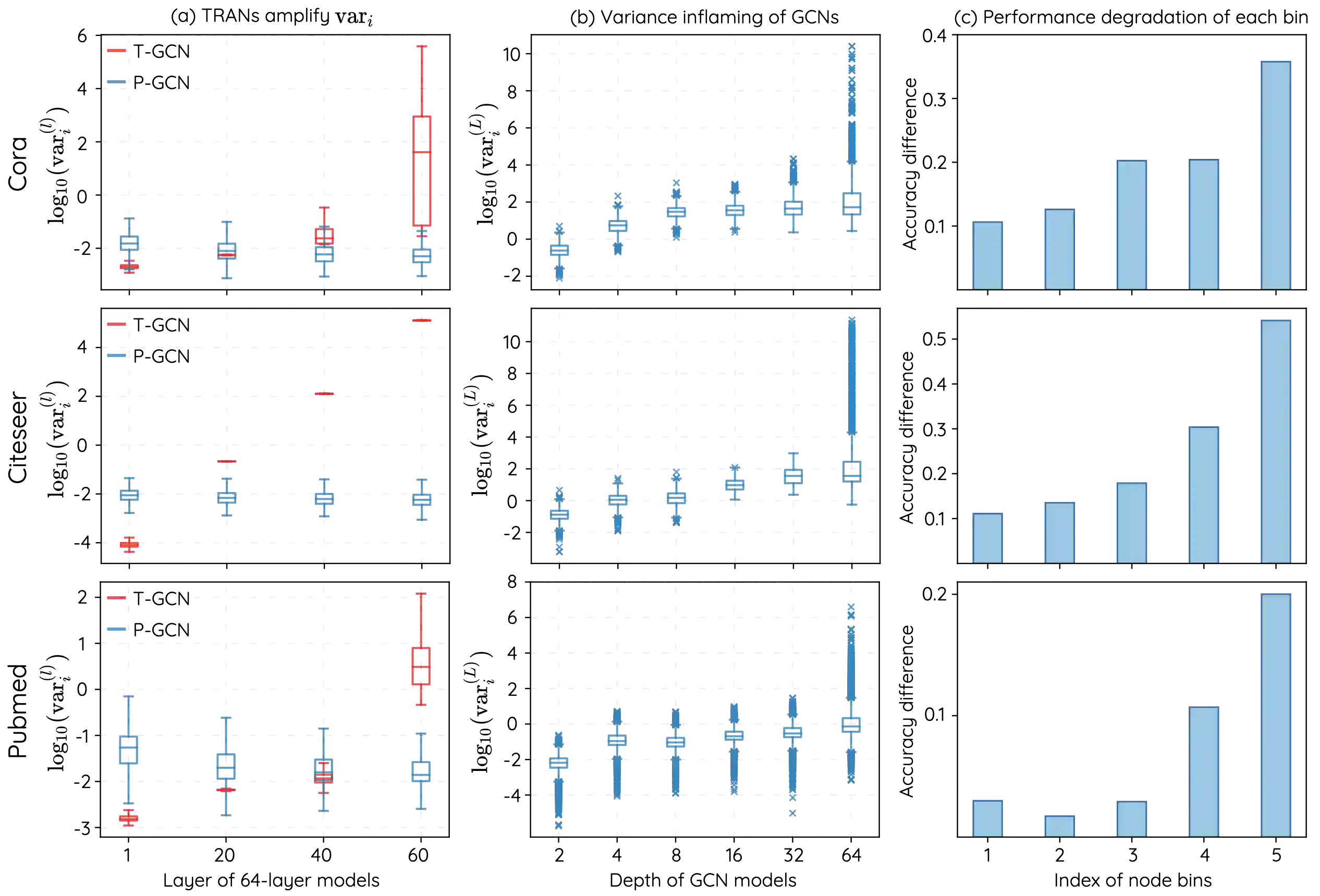
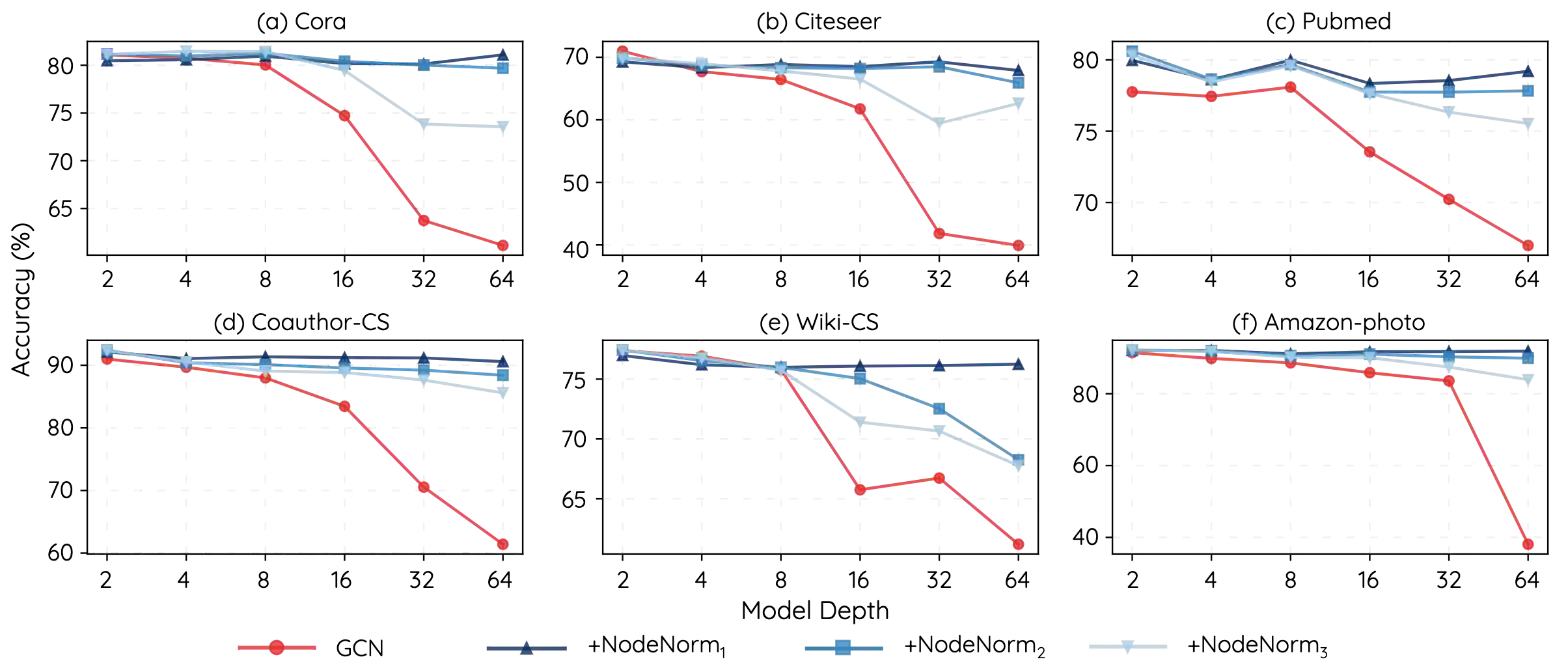
A Graph Convolutional Network (GCN) stacks several layers and in each layer performs a PROPagation operation (PROP) and a TRANsformation operation (TRAN) for learning node representations over graph-structured data. Though powerful, GCNs tend to suffer performance drop when the model gets deep. Previous works focus on PROPs to study and mitigate this issue, but the role of TRANs is barely investigated. In this work, we study performance degradation of GCNs by experimentally examining how stacking only TRANs or PROPs works. We find that TRANs contribute significantly, or even more than PROPs, to declining performance, and moreover that they tend to amplify node-wise feature variance in GCNs, causing variance inflammation that we identify as a key factor for causing performance drop. Motivated by such observations, we propose a variance-controlling technique termed Node Normalization (NodeNorm), which scales each node's features using its own standard deviation. Experimental results validate the effectiveness of NodeNorm on addressing performance degradation of GCNs. Specifically, it enables deep GCNs to outperform shallow ones in cases where deep models are needed, and to achieve comparable results with shallow ones on 6 benchmark datasets. NodeNorm is a generic plug-in and can well generalize to other GNN architectures. Code is publicly available at https://github.com/miafei/NodeNorm.
翻译:图表革命网络(GCN) 堆叠了几层, 每层中都有几层, 每层中都有几层, 我们通过实验研究堆叠TRAN或PROP的特性如何起作用, 研究GCN的性能退化。 我们发现TRAN对在图形结构化数据中学习节点表示作用有显著或甚至超过TRAN, 而且它们往往会放大GCN的节点特征差异, 造成差异炎热, 我们确定这是造成性能下降的关键因素。 我们受这种观察的驱使, 我们提出了一种差异控制技术, 名为Node 正常化( NodeNorm), 使用自己的标准偏差来测量每个节点的特性。 我们发现TRANN对降低性能作用有很大的帮助, 甚至比PROP还大, 而且它们往往会放大GCN的节点特征差异, 造成差异性能差异, 我们确定这是导致性能下降的关键因素。 我们建议一种名为Node- 正常化(NodeNorm) 的技术, 使用自己的标准偏差来测量每个节点特征特征。 实验结果验证NONM在GCNPER在深度通用模型中处理性降解, 在深度的常规模型中, 的深度模型中, 无法进行更深的模型中, 直基质化数据到比。