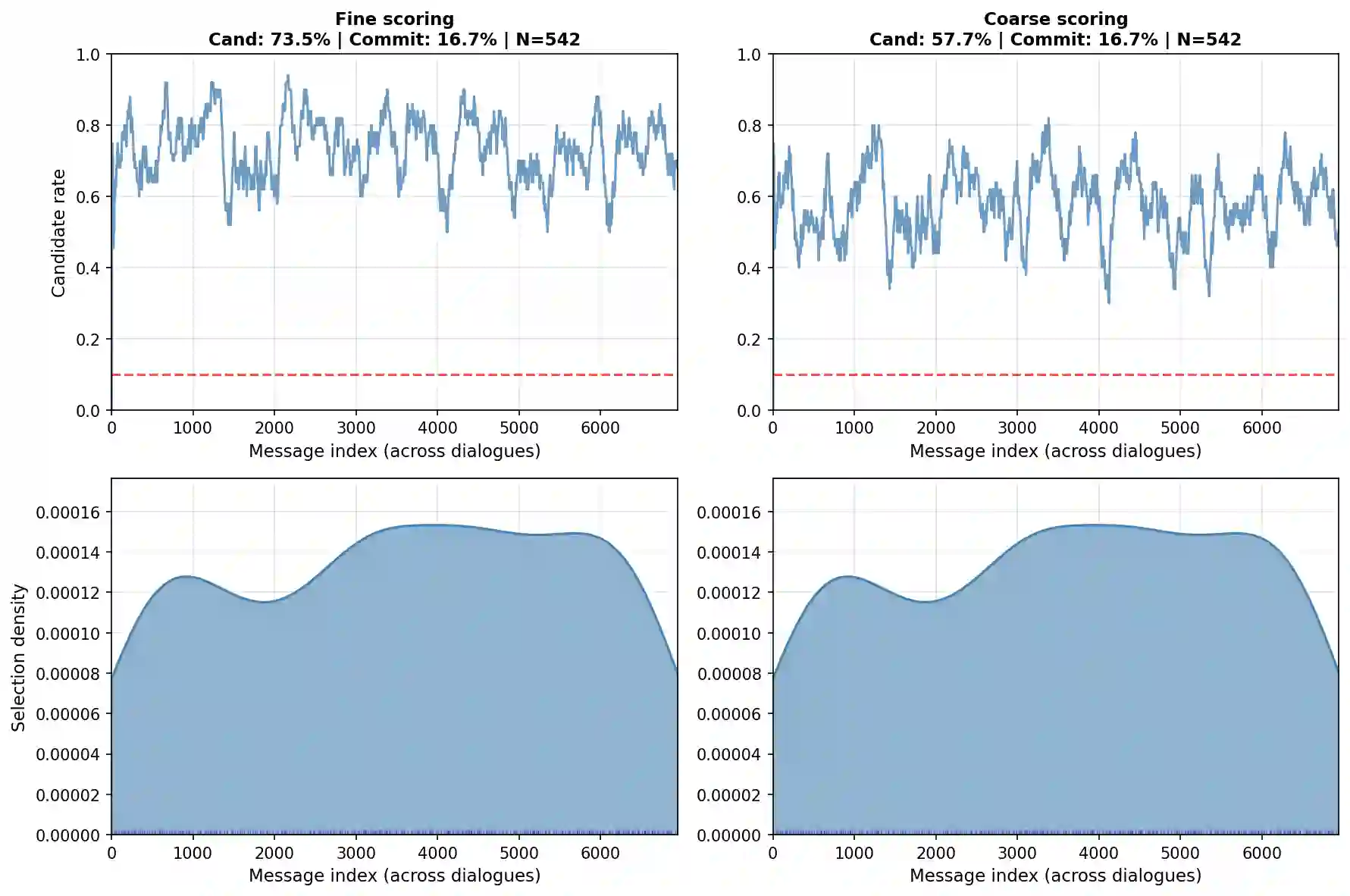
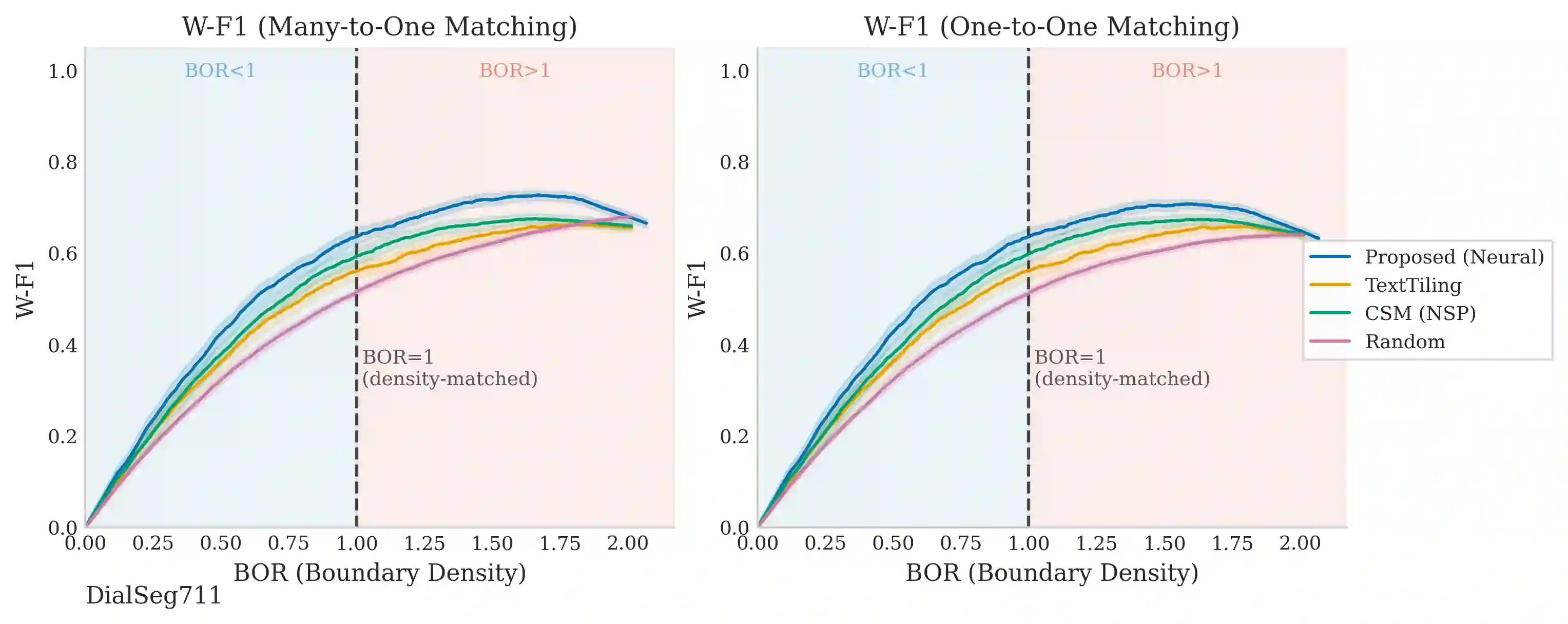
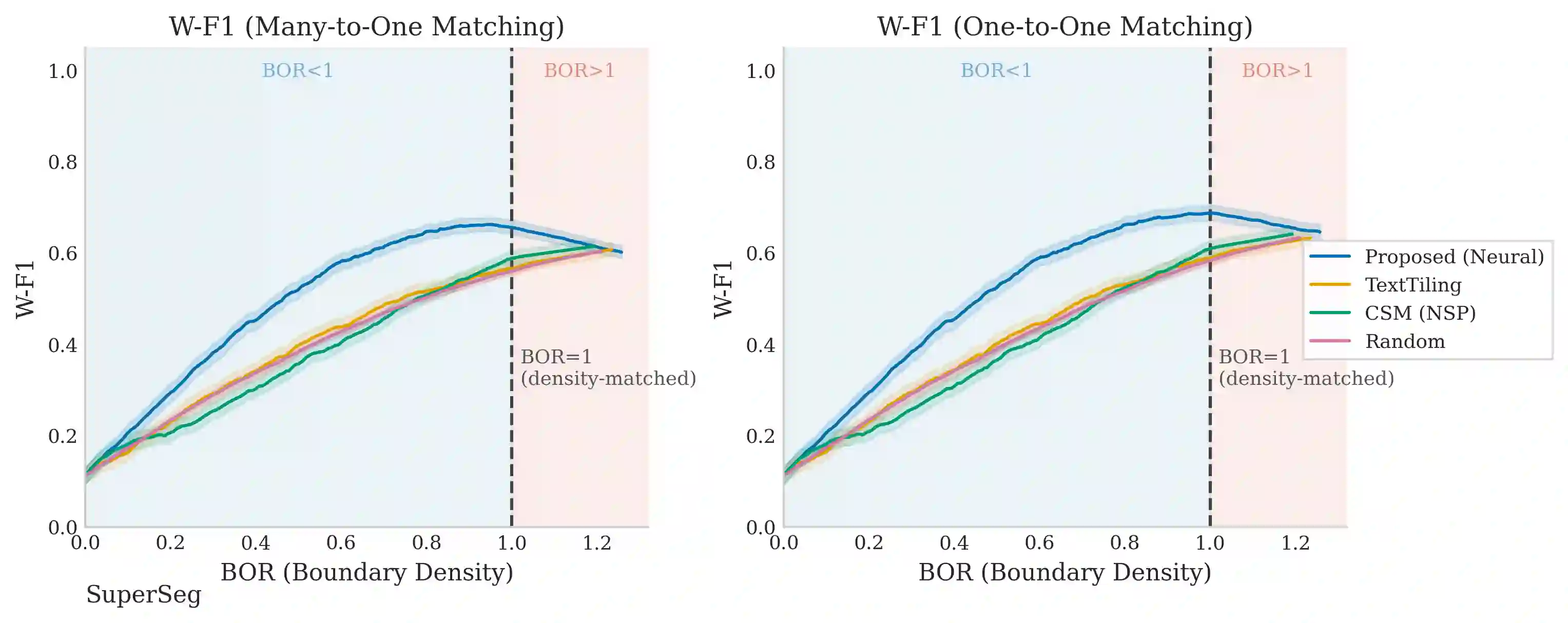
Dialogue topic segmentation supports summarization, retrieval, memory management, and conversational continuity. Despite decades of work, evaluation practice remains dominated by strict boundary matching and F1-based metrics. Modern large language model (LLM) based conversational systems increasingly rely on segmentation to manage conversation history beyond fixed context windows. In such systems, unstructured context accumulation degrades efficiency and coherence. This paper introduces an evaluation framework that reports boundary density and segment alignment diagnostics (purity and coverage) alongside window-tolerant F1 (W-F1). By separating boundary scoring from boundary selection, we evaluate segmentation quality across density regimes rather than at a single operating point. Cross-dataset evaluation shows that reported performance differences often reflect annotation granularity mismatch rather than boundary placement quality alone. We evaluate structurally distinct segmentation strategies across eight dialogue datasets spanning task-oriented, open-domain, meeting-style, and synthetic interactions. Boundary-based metrics are strongly coupled to boundary density: threshold sweeps produce larger W-F1 changes than switching between methods. These findings support viewing topic segmentation as a granularity selection problem rather than prediction of a single correct boundary set. This motivates separating boundary scoring from boundary selection for analyzing and tuning segmentation under varying annotation granularities.
翻译:对话主题分割为摘要生成、信息检索、记忆管理及会话连续性提供了关键支持。尽管相关研究已开展数十年,当前评估实践仍主要依赖严格边界匹配和基于F1的度量标准。现代基于大语言模型(LLM)的对话系统日益依赖主题分割技术来管理超出固定上下文窗口的对话历史。在此类系统中,非结构化的上下文积累会降低系统效率与连贯性。本文提出一种评估框架,在报告边界密度和片段对齐诊断指标(纯度与覆盖率)的同时,引入窗口容错F1(W-F1)度量。通过将边界评分与边界选择解耦,本框架能在不同密度区间评估分割质量,而非局限于单一操作点。跨数据集评估表明,现有方法间的性能差异往往反映的是标注粒度失配,而非单纯的边界定位质量。我们在涵盖任务导向、开放域、会议风格及合成交互的八个对话数据集上,对结构各异的主题分割策略进行了系统性评估。基于边界的度量指标与边界密度存在强耦合关系:阈值扫描产生的W-F1变化幅度甚至超过不同方法间的性能差异。这些发现支持将主题分割视为粒度选择问题,而非对单一正确边界集的预测。该视角为在不同标注粒度下分析和优化分割性能,提供了将边界评分与边界选择相分离的理论依据。