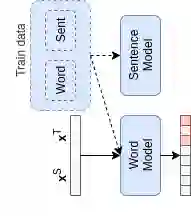
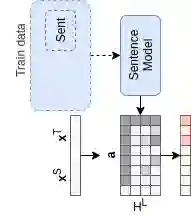
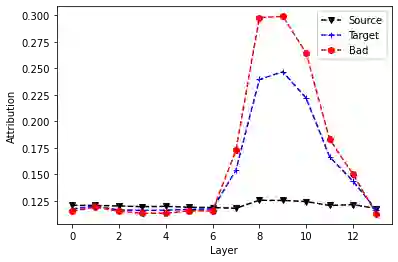
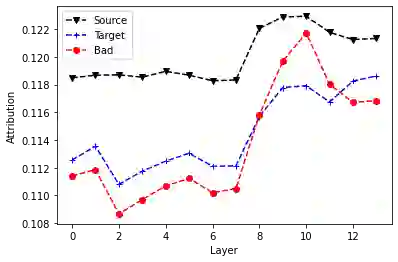
Recent Quality Estimation (QE) models based on multilingual pre-trained representations have achieved very competitive results when predicting the overall quality of translated sentences. Predicting translation errors, i.e. detecting specifically which words are incorrect, is a more challenging task, especially with limited amounts of training data. We hypothesize that, not unlike humans, successful QE models rely on translation errors to predict overall sentence quality. By exploring a set of feature attribution methods that assign relevance scores to the inputs to explain model predictions, we study the behaviour of state-of-the-art sentence-level QE models and show that explanations (i.e. rationales) extracted from these models can indeed be used to detect translation errors. We therefore (i) introduce a novel semi-supervised method for word-level QE and (ii) propose to use the QE task as a new benchmark for evaluating the plausibility of feature attribution, i.e. how interpretable model explanations are to humans.
翻译:以经过培训的多语言代表制为基础的近期质量估计模型在预测翻译判决的整体质量时取得了非常有竞争力的结果。预测翻译错误,即具体发现哪些字不正确,是一项更具有挑战性的任务,特别是培训数据有限。我们假设,成功的质量控制模型与人类不同,并非依赖翻译错误来预测总体判决质量。我们探索了一套特征归属方法,将相关分数分配给投入来解释模型预测,我们研究了从这些模型中提取的最新句级QE模型的行为,并表明从这些模型中提取的解释(即理由)确实可以用来探测翻译错误。因此,我们(一)为字级质量控制引入了一种新型的半超级方法,并(二)提议使用质量控制任务作为评估特征归属的可信赖性的新基准,即如何对人类作出可解释的模型解释性解释。