从特斯拉AI团队学到的九条方法论

尽管 OpenAI 以其在自然语言处理上的成就而著称,而 DeepMind 则以强化学习和决策而闻名,特斯拉(Tesla)无疑是计算机视觉领域最有影响力的公司之一。即便你不是计算机视觉专业人士,你也可以通过特斯拉了解到不少它的生产级人工智能。
特斯拉的人工智能团队并没有像 Uber 或 Airbnb 那样发表博文,因此外界很难了解他们都做了什么,又是怎样取得今天的成绩。不过,特斯拉在 2021 年举办的“人工智能日”展示了许多技术和经验,这些技术和经验对所有的人工智能部门和企业都有借鉴意义。
下面是一些经验。
特斯拉公布了其最新产品:特斯拉机器人(Tesla Bot),这是一款人形机器人产品。尽管汽车和机器人看上去差别很大,但是无人驾驶汽车和由人工智能控制的机器人实际上有许多相同的部件。举例来说,特斯拉汽车和特斯拉机器人都需要传感器、电池、实时计算和分析接收到的数据,同时还需要即时作出决策。所以,特斯拉开发的人工智能芯片和硬件都可以在两者中使用。
特斯拉的两款产品在软件和算法上都要求有一个视觉系统和规划系统。所以特斯拉汽车团队能够和特斯拉机器人团队共享软件代码库。规模经济将会进一步降低平均开发费用,从而使得特斯拉在市场上更加具有竞争力。
特斯拉的人工智能团队还有一个优势,那就是特斯拉机器人所收集到的数据也可以用来训练特斯拉的无人驾驶汽车。
事实上,还有其他重用内部先进技术的例子。
其中之一就是 reCAPTCHA。Luis von Ahn 最先联合发明了验证码(CAPTCHA),它要求用户输入屏幕上显示的字母,从而实现自我认证。之后,他开始向自己挑战,让验证码变得更加有用,最终,他和《纽约时报》(NY Times)共同发明了 reCAPTCHA,这个系统能将书籍中的长句分解,要求用户输入他们所看到的内容。只需稍加修改,就可以让几百万本书在数天之内被数字化,而这一过程原本很可能需要花费好几年才能做到。
如果你的公司拥有独一无二的技术,那么请记住技术的本质,并且考虑哪些人可以从你的技术中获益。把你的思想资源用在这上面,你就能找到下一个业务线了。
在问答环节中,伊隆·马斯克(Elon Musk)说:
一般来说,创新就是很多次迭代,每次迭代之间的平均进程。所以,在迭代之间缩短了时间,那么改进的速度将会好很多。
因此,如果一个模型的训练时间有时需要几天,而不是几个小时,那就太重要了。这已经解释了为什么特斯拉拥有一支 工具团队,并在内部制造了很多东西。而这就是下一个经验。
特斯拉知道 GPU 一般都是内置的硬件,而用专门设计的芯片进行大规模计算,速度会更快。正因为如此,特斯拉才有了自己的人工智能芯片:Dojo。
除芯片外,特斯拉还建立了自己的人工智能计算基础设施,每周进行 100 万次实验。他们还构建了自己的调试工具,可以把结果可视化。在演讲中,Andrej Karpathy 提到,他发现数据标签管理工具很关键,他们为这个工具感到自豪。
如果你的团队没有足够的资源来构建自己的工具,那么你可以加入开源社区。你可以根据自己的需求,创建一个基于开源项目的东西。如果你遇到了新问题,或是有了更好的点子,那么就开始开发最初的原型,并写好文档的困难部分,这样才能让与你有类似问题的人能够帮到你。
如果你稍微了解一下舞台上那些人的背景,你就会发现他们都是非常聪明的人,他们都是拥有博士学位、从顶尖大学毕业的人,或是曾经干过什么了不起的大事。
这些人也有失误的时候。Andrej Karpathy 分享说,他们最初是和第三方的数据提供商一起工作的。我想,他们之所以这么做,是为了更快速地获取数据,降低成本。但是,他们不久就会意识到,在这样的关键问题上,与第三方合作,和来回的沟通,并不能解决问题。因此,他们把注释员引进公司,目前已有超过 1000 名注释员。
从这一经验教训中我们可以学到,创新和技术进步都是一个不断试错的过程。错误就是它的一部分。如果你逃避错误,把失败归咎于他人,那么你就没有学习到什么,也不会取得进步。
在问答分享中,Ashok Elluswamy 提出,神经网络仅仅是系统中的一块,可以与任何东西结合。他解释说,实际可以将搜索与优化融入到网络架构中,也可以将基于物理学的块(模型)和神经网络块相结合,形成一个混合系统。
我觉得把神经网络和非神经网络模型结合在一起进行训练,这个主意很有意思,而且非常值得一试。
HydraNet 的想法可以追溯到 2018 年,这在人工智能社区中已经存在很久了。尽管如此,我仍然觉得这个主意不错,而且在许多情况下会非常有用。Andrej 解释说,HydraNet 允许神经网络共享一个共同的架构,将任务解耦,你可以为中间的特征缓存,从而节约计算。
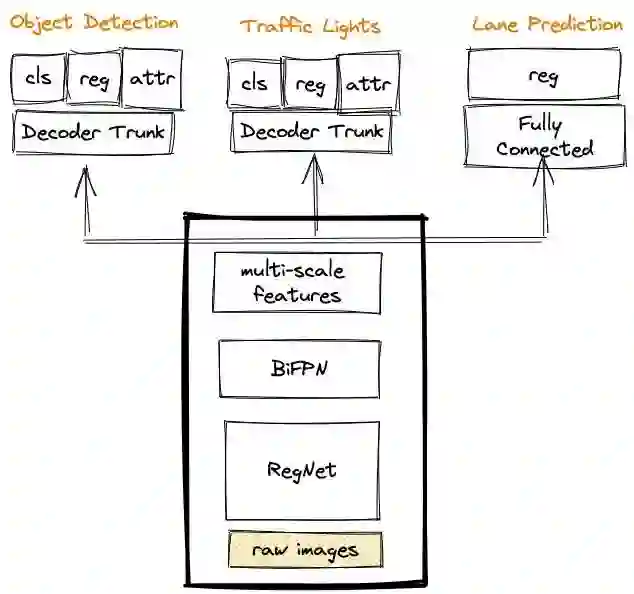
标签不平衡是一种常见的、无所不在的现象。少数族裔的数据即使不是不可能,也很难获得。但是,要在现实世界中部署人工智能,最关键的问题总是在边缘的情况下,因为这会带来严重的、不必要的后果。
模拟是一种用于生成新数据的数据论证技术,但是说起来简单,实际操作起来却很困难。在特斯拉,模拟团队采用了诸如光线追踪之类的技术,以产生逼真的视频数据,我个人乍一看无法判断这些数据的真伪。

我想,这项技术的确是特斯拉的一件秘密武器,因为它可以轻易地获取到许多非同一般的数据。如今,他们能够生成像一对夫妻和一条狗在高速公路上狂奔的视频数据,这虽然是不太可能的事,但绝对有可能生成。
对了,你怎么看到“模拟即服务”这个想法?
曾有观众问,特斯拉是否将机器学习用于其制造设计或其他工程流程,马斯克是这样回答的:
对于 99.9% 的数据,我不做任何评论,这要看你说的是什么。举个例子,你不一定要用机器学习,才能找到你最大的消费客户。你所需要的仅仅是一种排序算法。
不过,我发现很多人都会犯这个错误。为了让机器学习有效,你必须满足一系列的条件。即使不能,也有很多可以帮你解决数据科学问题的工具。比如,遗传算法、数学建模、调度算法,等等。
如果你有一把锤子,所有东西看起来都像钉子。
无人驾驶模拟团队的经理 Ian Glow 提到,最近有一篇关于现实增强(photorealism enhancement)的论文,展示了最新的研究成果,但是他的研究团队可以做到的远多于那些已经发表文章的团队。原因在于特斯拉的数据、计算能力和人力都要多。
这仅仅是深度学习中的数据和计算至关重要的又一例证。我想这个经验就是,如果你真的想要将深度学习应用到生产中,那么就应该花些时间来思考一下,怎样才能得到数据,并且能够更有效、高效地利用计算能力。继续这样做,直至你使获取数据和使用数据的平均成本可以忽略不计。
虽然很多人专注于深度学习模型的实施细节,但是我相信,大的想法、教训和背后的思考过程同样有价值。我希望这篇文章能为你提供一些新的知识,并有助于你发展更好的机器学习实践。
作者介绍:
Gary Chan,数据科学家。
原文链接:
https://pub.towardsai.net/9-lessons-from-the-tesla-ai-team-3c311100e6cc
今日好文推荐
保卫腾讯云,专访云鼎实验室董志强(Killer)团队 | 卓越技术团队访谈录
GitHub热榜项目“程序员延寿指南”一周获上万Star;快手前副总裁巨额受贿案宣判;小红书辟谣大裁员:正常人员汰换 | Q资讯
自由软件之父抨击苹果电脑变成“监狱”,不建议用Ubuntu
活动推荐
参与写作社区 2 周年庆典活动!500 份周年定制礼包等你来拿~还有机会赢取苹果电脑、Switch 游戏机等多重好礼!
![]()
保卫腾讯云,专访云鼎实验室董志强(Killer)团队 | 卓越技术团队访谈录
GitHub热榜项目“程序员延寿指南”一周获上万Star;快手前副总裁巨额受贿案宣判;小红书辟谣大裁员:正常人员汰换 | Q资讯
活动推荐
参与写作社区 2 周年庆典活动!500 份周年定制礼包等你来拿~还有机会赢取苹果电脑、Switch 游戏机等多重好礼!

点个在看少个 bug 👇


