人类玩德州扑克也扑街了?Facebook开发玩德州扑克的AI,大比分击败顶尖人类选手!

新智元报道
新智元报道
来源:venturebeat
编辑:白峰
【新智元导读】最近,Facebook的研究人员开发了一个玩德州扑克的人工智能,可以轻松击败人类玩家,它跟DeepMind的AlphaZero有何不同?今天我们就来看下。
近年来人工智能发展迅猛,很多重复性的工作都被AI自动化了,人类工作要被机器替代的说法也「甚嚣尘上」,而现在,打打扑克也不行了?
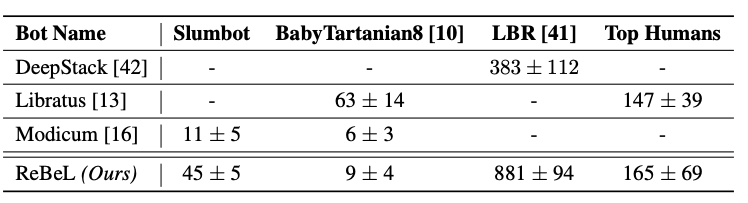
最近,Facebook 的研究人员开发了一个名为「Recursive Belief-based Learning」(ReBeL)的通用人工智能框架,德州扑克玩的相当溜。

根据Facebook的说法,这个框架在单挑无限制的德州扑克游戏中明显优于人类表现,而且使用的领域知识比之前任何扑克人工智能都要少。
他们断言 ReBeL 是开发通用多代理交互技术的一种方法,该算法可以部署在大规模、多代理环境中,预期的应用范围也很广,从拍卖、谈判、网络安全到自动驾驶都能用上。
AlphaZero在不完全信息游戏中表现「差点意思」
基于信念的递归学习击败顶尖人类玩家


担心被拿去赌钱,Facebook决定不公开源码

登录查看更多
相关内容



相关VIP内容
相关资讯
相关论文