![]()
本文约4350字,建议阅读7分钟。
机器翻译对于人工翻译而言是威胁还是可利用工具?在多大程度上机器翻译又能帮助普通用户呢?
![]()
作为自然语言处理中一项非常重要的应用,现代意义上的机器翻译概念从上世纪40年代提出至今,经过了几代革新,现已初步实现了多场景的落地和应用。近几年随着机器翻译质量的提高,机器翻译代替人工翻译的声势逐渐浩大起来,那么机器翻译对于人工翻译而言是威胁还是可利用工具?在多大程度上机器翻译又能帮助普通用户呢?
![]()
在AI Time第六期的辩论中,中科院自动化研究所研究员宗成庆、北京外国语大学高级翻译学院副院长李长栓、苏州大学计算机学院副院长国家杰青张民、东北大学计算机学院教授朱靖波、清华大学计算机科学与技术系长聘副教授刘洋一起论道了机器翻译的相关问题。
![]()
机器翻译的历史大体可以分为两大阶段,第一阶段是从60年代到90年代初期,理性主义方法是主流,主要是让人类专家观察语言规律,把它描述成规则,让机器按照既定规则进行翻译。
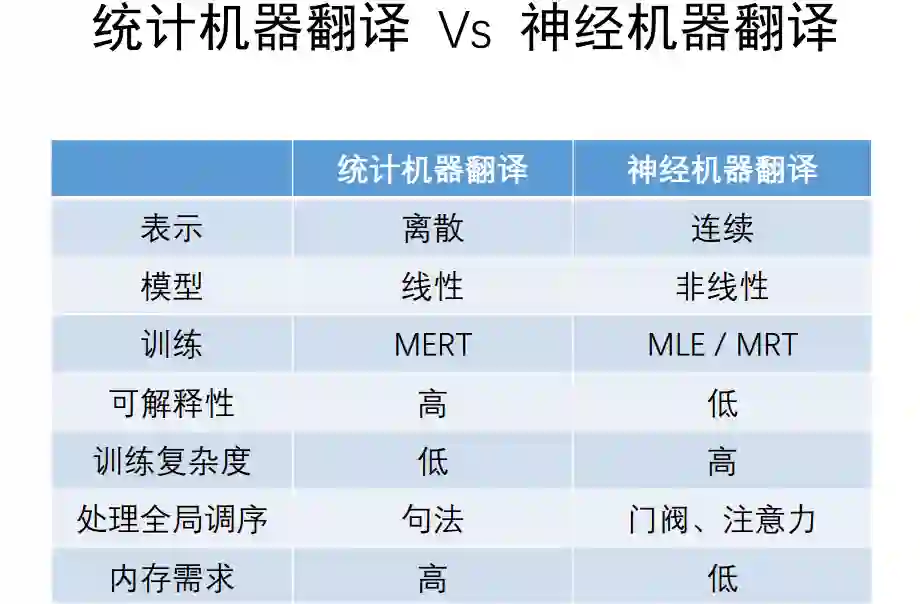
第二个阶段是90年代,特别是互联网出现以后,开始从事统计机器翻译研究,此时数据以及相应的数据驱动方法得到蓬勃发展。
统计方法比较经典的模型叫做隐变量对数线性模型,它的特点是要设计特征,X代表输入,Y代表输出,Z就代表中间的语言结构,通过定义各种特征函数来训练一个参数,很多工作都集中在如何设计好的特征来描述翻译规律上。
但语言太过复杂,穷尽人类智慧也很难把这个特征设计全面,其中一个难点称之为调序,比如“就中东局势举行了一个小时会谈”,这是一个典型的介词短语和动词短语的组合,在中文中先说介词短语,再说动词短语,但在英文中都是反过来的。
2015年后,深度学习在机器翻译得到应用。
深度学习的主要意义在于它可以从数据中自动提取表示,就不需要像以前一样设计特征来描述翻译规则,只需要设计一个网络,让机器自动在数据去寻找表述,效果非常好。
但还是有难解决的问题,它根本不知道数字是什么意思,不知道为什么出错,不知道怎么去改动它,而且很难控制。
目前最核心的技术叫做注意力机制,希望通过自动计算发现中英文之间的相关性,这在整个深度学习里也是非常核心的技术。
现在可以利用一些比较新的技术,这个是transformer,希望能够处理更长的序列。
最近几年出现了一系列机器翻译应用,比如翻译机、微信的翻译服务。
机器翻译很大程度上是为解决不同国家、不同文化之间的沟通问题,如果机器翻译能在一定程度上取代人、帮助人,沟通的信道会有一个巨大的释放。
那么机器翻译究竟能否代替人呢?
宗成庆老师认为,机器翻译近几年的进步很大,可以大幅提高翻译效率,但是机器翻译的运用需要基于场景和任务,机器翻译在一些场景下确实能帮助人,比如旅游问路,但是在某些领域,比如高层次的翻译,要对机器翻译寄予太多的希望还为时过早。
张民老师对宗老师的观点表示赞同,他补充道,机器翻译要从学术界和产业界两个侧面看。
学术界一直可以做下去,产业界里机器翻译已经蓬勃发展,产业对学术界技术需求强烈,技术达到了产业低端门坎,产业推动技术发展、技术服务行业。
李长栓老师也认为虽然机器翻译进步惊人,但不会有取代人的一天,其主要原因在于机器翻译质量还达不到专业翻译的要求,单个句子能理解,但通篇没有逻辑。
朱靖波老师同意宗老师和张老师的观点,并举例说,通常假设翻译人员的结果完全正确,而技术想要超过100%去达到101%的正确率,这在真理上是无法超越的。
但是机器翻译在大数据之后蓬勃发展,并非意在取代人类,比如国家知识产权里几百万个专利文档,只能利用机器翻译,非人工所为;
再比如身在国外,人工翻译不可能随时在身边,只能利用机器翻译,这都不能算是代替人工翻译,而是去弥补人工翻译干不了的应用场景。
李长栓老师根据自己的使用经验,归纳了一下机器翻译中遇到的主要问题:
中文长句子翻译成英文,需要断成几句,但断开之后,后面的句子就没有主语了,这时候要补充主语。而机器翻译根据什么补充主语成迷。
比如“诉裁程序”,机器翻译给出了十几个译文版本,这个问题应该可以解决,但是神经网络翻译似乎还没有解决这个问题。
机器翻译是依赖于形式的转换,遇到歧义时是根据概率决定修饰关系;一词多义也是,即便给了语料库,但是在同一个专业领域,一个词也有很多意思。
![]()
首先,目前基于句子级翻译系统主要因为具体实现机制的问题,实际上学术界关于篇章级机器翻译有不少研究工作。
基于上下文分析主语省略和指代消解等问题,他更倾向于认为是理解问题而非翻译问题,但可以将两者结合起来实现更好的翻译结果。
其次,有些问题应该分成两个环节来考虑,比如原文错误,人会通过理解对其进行纠正错误后翻译,但是对于机器翻译来说,它认为这是用户想要表达的意思,不能轻易自动修改原文,导致错误的翻译。
这就引出一点,机器翻译是不是和别的技术融合在一起使用的效果更好。
最后,一词多义跟结构歧义的问题是现在做得不够好,不是机器翻译没有能力解决,机器翻译建模的核心就是为了解决这两个问题。
宗成庆老师指出,现在机器翻译的基本假设是,只要收集到足够多样本就行。
但这个假设是有问题的,第一,模型能否学成存疑,第二,不应该只基于样本,还有日常生活经历和常识等。
现在的模型还不够智能,提供足够的样本也无法学成,这也是提出基于知识的机器翻译的原因。
张民老师从学术界的角度分析了机器翻译存在的两个重大问题。
一是篇章问题,翻译本来应该根据上下文理解和逻辑分析,但目前机器翻译建模方法都是句子对句子,在句子层面把翻译看作是纯数学映射,因此深度学习的方法如果遇上语料训练缺失的情况急剧下降。
二是知识和推理驱动,不仅仅是语言学知识,还包括常识知识、领域知识、世界知识等。
刘洋老师举了一个例子,有高翻在法国为了翻译一本很厚的地铁资料,坐了一周的法国地铁,向乘务员询问各种信息,后来为核电站翻译也是如此,要知道设备的用途,他认为翻译的绝大功夫都是花在对背景知识的理解。
而反观现在的机器翻译,还是基于数据,没有上升到知识。
预训练是一个非常不一样的想法,在单语数据上设计相关问题的学习任务,这样数据几乎是无限的,然后在上面训练模型。
过去一年,预训练的方法基本刷榜了LP任务,普遍提升8-10个点。
但是机器翻译还没有这么好的效果,因为翻译的输出不是简单的分类,而是整个序列,这个序列光输出这个词,就是指数级的数据,同时还要排准数据和阶层,复杂度非常高。
预训练和机器翻译的结合是一个方向,如果提升到基于知识的翻译系统,显然是更好的策略。
目前比较容易想到的是知识图谱和机器翻译结合,但这块没有突破性的进展。
李长栓老师也认为专业翻译大部分时间是用来查资料的,他举例,“某一个先生指出,索马里沿海海岛问题,联络小组鼓励通过法律允许根据捕获和释放的做法进行起诉”,看 完之后不知所云,这就是机器翻译的结果。
这种时候专业翻译就会去查阅相关资料,明白之后再进行翻译,“谁谁指出,鉴于一些国家存在先抓后放的做法,某小组鼓励相关国家通过立法允许起诉”。
翻译是一个不断调查、不断获取文字背后意思的过程,表达的过程是在理解基础上自然形成的。
同时李长栓老师也提供了他对机器翻译的优化思路,机器补充知识是机器的优势,它有无穷无尽的语料,翻译某一句话时就可以利用超链接等方式提供相关背景,这样会更有助于翻译的进行。
朱靖波老师根据自己的经验列举出好的机器翻译系统需要的三个东西。
一是扩大训练数据规模,提高品质;
二是不断创新技术;
三是根据问题不断打磨,三者缺一不可。
他把机器翻译技术的概念扩大到两个不同对象之间的等价转换,并认为机器翻译与人工智能和NLP不同,机器翻译是一个产业,机器翻译+也是一个产业。
宗成庆老师认为虽然现在机器翻译问题很多,但是不用悲观,从研究角度讲,只有发现问题才能改进问题,问题代表了进步空间。
朱靖波老师认为未来机器翻译的突破口在于产学研形成闭环,应用需求不断推进机器翻译理论和技术研究。
刘洋老师表示,必须要在范式上进行革新,要找到好的策略和方法,充分利用非标注数据。
或者能把数据用好,或者能够从未标注数据中提炼出知识,这两点都非常关键。
李长栓老师认为,机器翻译在中英文间的切换还是很困难,但是在新闻语言等领域,机器翻译的质量已经很高。
未来的突破还是要回归到范式或者是思维方法的改变上来,从句子当中抓取意思,再重新表达,这是人做翻译时的思维过程,未来机器翻译也是这样。
宗成庆老师补充道,高质量的机器翻译结果并非一定要达到信达雅,那是人类翻译的终极目标,目前在某些场景的翻译结果已经很好,未来还需要解决更细节的问题。
从某种意义上讲,现在神经网络机器翻译的性能已经接近天花板,未来一定是对翻译模型进行改进和提高,从技术应用和产业发展的角度讲,需要明确具体需求和任务,针对性地做定向开发,这是推动整个技术真正走向实用的比较可行的路线。
张民老师表示,机器翻译本身既是一个科学问题,又是一个工程问题,未来想要突破,科学上的突破一定要从科学技术上产生新的范式;
工程上的突破一定要依赖知识,而知识需要在不同的领域、需要全人类来解决。
![]()