TensorFlow Extended (TFX):使用 Apache Beam 实现大规模数据处理
文 / Reza Rokni, 技术推广工程师, Google Cloud(代表 TFX 和 Apache Beam 团队)

TensorFlow Extended (TFX) 的核心任务是帮助开发者将模型从研究投入生产,同时创建和管理生产流水线。很多模型在构建时都会使用大量数据,因此需要多个主机并行运行才能同时满足生产流水线的处理和服务需求。
Apache Beam 是 TFX 的数据处理框架,我们将借助继承自该框架的功能,了解如何针对小型数据集开发 TFX 流水线,以及扩展并应用于生产数据集。
Apache Beam
Apache Beam 的起源可追溯到 FlumeJava,后者是 Google 使用的数据处理框架(在FlumeJava 论文 (2010) 中有相关讨论)。现在,Google Flume 是 Google 内部广泛使用的工具,如 TFX 在 Google 内部的数据处理框架也使用它。
Google Flume 是 Google Cloud Dataflow(2015 年发布)开发的基础工具。SDK for Dataflow 在 2016 年开放源代码,并命名为 Apache Beam。与 Google 的内部 TFX 实现相似,TFX 的外部版本使用 Google Flume 的外部版本。
在执行有向无环图 (DAG) 的环境下,Apache Beam 的可移植 API 层为 TFX 库(如 TensorFlow Data Validation,TensorFlow Transform,和 TensorFlow Model Analysis)提供支持。该图可在一组不同的执行引擎或“运行程序”中获得执行。如需运行程序及其功能的综合列表,请访问以下网站:
https://beam.apache.org/documentation/runners/capability-matrix/。
本文使用的 runner 与 Dataflow 有很多类似,并正在进一步统一。
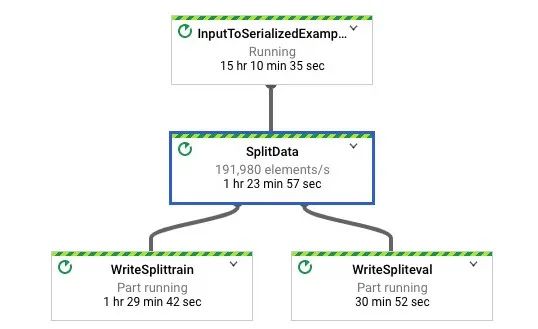
下面是 TFX 组件 ExampleGen 在 Google Cloud Dataflow 运行程序上运行时创建的图表:
Apache Beam 的优势
Apache Beam 可自由选择不同的执行引擎,这也是促使我们决定对 TFX 使用 Apache Beam 的重要因素。开发工作可以在本地 DirectRunner 上完成,而生产工作负载可以在生产 runner 上运行。例如,Apache Flink 可以在本地数据中心运行,也可以在 Google Dataflow 等完全托管的云 runner上运行。通过使用 Google Dataflow 等生产 runner,我们可以使用数万个并行运行的核心来执行在 TFX 库中的计算。并且使用流水线开发期间创建的相同代码。
我们将在本文的其他部分通过两个示例来介绍此功能。首先,使用 TFX 核心库AnalyzeAndTransformDataset,最后使用两个 TFX 组件 ExampleGen 和 StatisticsGen。
注意:
Google Cloud BigQuery 和 Google Cloud Dataflow 是付费服务,请先确保您了解费用问题,再运行本文中的示例:
https://cloud.google.com/bigquery/pricing
https://cloud.google.com/dataflow/pricing
https://cloud.google.com/storage/pricing
TFX 库
TFX 流水线组件根据 TFX 库构建,例如其中一个库是使用 Apache Beam 的 tf.transform。我们将使用两个不同的 Apache Beam 运行程序来使用此库。首先,使用本地开发运行程序 DirectRunner。然后,对代码稍作修改,以便使用 Google Cloud Dataflow 生产 runner 运行示例。 DirectRunner 是为开发而打造的轻量级 runner,可以在本地运行,无需分布式处理框架。
以下流水线示例摘自教程(预处理数据(初学者)),其中提供如何使用 TensorFlow Transform (tf.Transform) 预处理数据的示例。
如需有关 preprocessing_fn 的详细信息,请参阅教程。在本文中,我们只需了解此代码会将传递的数据点转换为函数。
注意:
本文使用的环境是:
virtualenv tfx-beam --python=python3
source tfx-beam/bin/activate
pip install tfxdef main():
with tft_beam.Context(temp_dir=tempfile.mkdtemp()):
transformed_dataset, transform_fn = (
(raw_data, raw_data_metadata) | tft_beam.AnalyzeAndTransformDataset(
preprocessing_fn))
transformed_data, transformed_metadata = transformed_dataset
print('\nRaw data:\n{}\n'.format(pprint.pformat(raw_data)))
print('Transformed data:\n{}'.format(pprint.pformat(transformed_data)))
if __name__ == '__main__':
main()注意:
Apache Beam 使用特殊语法定义和调用转换。例如,在该行中:
result = pass_this | 'name this step' >> to_this_call
系统会调用 to_this_call 方法,并传递名为 pass_this 的对象,此操作在堆栈轨迹中名为name this step。
在运行该示例时,您会隐式使用本地开发/测试 DirectRunner。我们可在使用 tft_beam.Context 时完成此操作。这将在本地环境下执行代码。 现在,我们要运行此示例,并从本地 DirectRunner 切换到 Google Cloud Dataflow。为此,我们需要在 beam.Pipeline 中打包初始 beam_impl.Context。
现在,我们仍通过设置参数 --runner=DirectRunner 来使用本地 DirectRunner。
import apache_beam as beam
argv=['--runner=DirectRunner']
def main():
with beam.Pipeline(argv=argv) as p:
# Ignore the warnings
with beam_impl.Context(temp_dir=tempfile.mkdtemp()):
input = p | beam.Create(raw_data)
transformed_dataset, transform_fn = (
(input, raw_data_metadata)
| beam_impl.AnalyzeAndTransformDataset(preprocessing_fn))
transformed_dataset[0] |"Print Transformed Dataset" >> beam.Map(print)
if __name__ == '__main__':
main()
在此步骤中,我们将切换为使用 Google Cloud Dataflow Runner。由于 Dataflow 是在 Google Cloud 上运行的完全托管的 runner,我们需要为流水线提供某些环境信息。其中包括 Google Cloud 项目和流水线使用的临时文件的位置。
注意:
您需要确保正确完成身份验证才能向 Dataflow 服务提交流水线任务。请查阅:https://cloud.google.com/dataflow/docs/concepts/security-and-permissions
# Setup our Environment
## The location of Input / Output between various stages ( TFX Components )
## This will also be the location for the Metadata
### Can be used when running the pipeline locally
#LOCAL_PIPELINE_ROOT =
### In production you want the input and output to be stored on non-local location
#GOOGLE_CLOUD_STORAGE_PIPELINE_ROOT=
#GOOGLE_CLOUD_PROJECT =
#GOOGLE_CLOUD_TEMP_LOCATION =
# Will need setup.py to make this work with Dataflow
#
# import setuptools
#
# setuptools.setup(
# name='demo',
# version='0.0',
# install_requires=['tfx==0.21.1'],
# packages=setuptools.find_packages(),)
SETUP_FILE = "./setup.py"
argv=['--project={}'.format(GOOGLE_CLOUD_PROJECT),
'--temp_location={}'.format(GOOGLE_CLOUD_TEMP_LOCATION),
'--setup_file={}'.format(SETUP_FILE),
'--runner=DataflowRunner']
def main():
with beam.Pipeline(argv=argv) as p:
with beam_impl.Context(temp_dir=GOOGLE_CLOUD_TEMP_LOCATION):
input = p | beam.Create(raw_data)
transformed_data, transformed_metadata = (
(input, raw_data_metadata)
| beam_impl.AnalyzeAndTransformDataset(preprocessing_fn))
if __name__ == '__main__':
main()如要了解 TFX 为我们减轻了多少工作量,请查看下方流水线处理图表的直观展示。由于转换众多,我们不得不缩小图片才能将其全部放入此版面中!
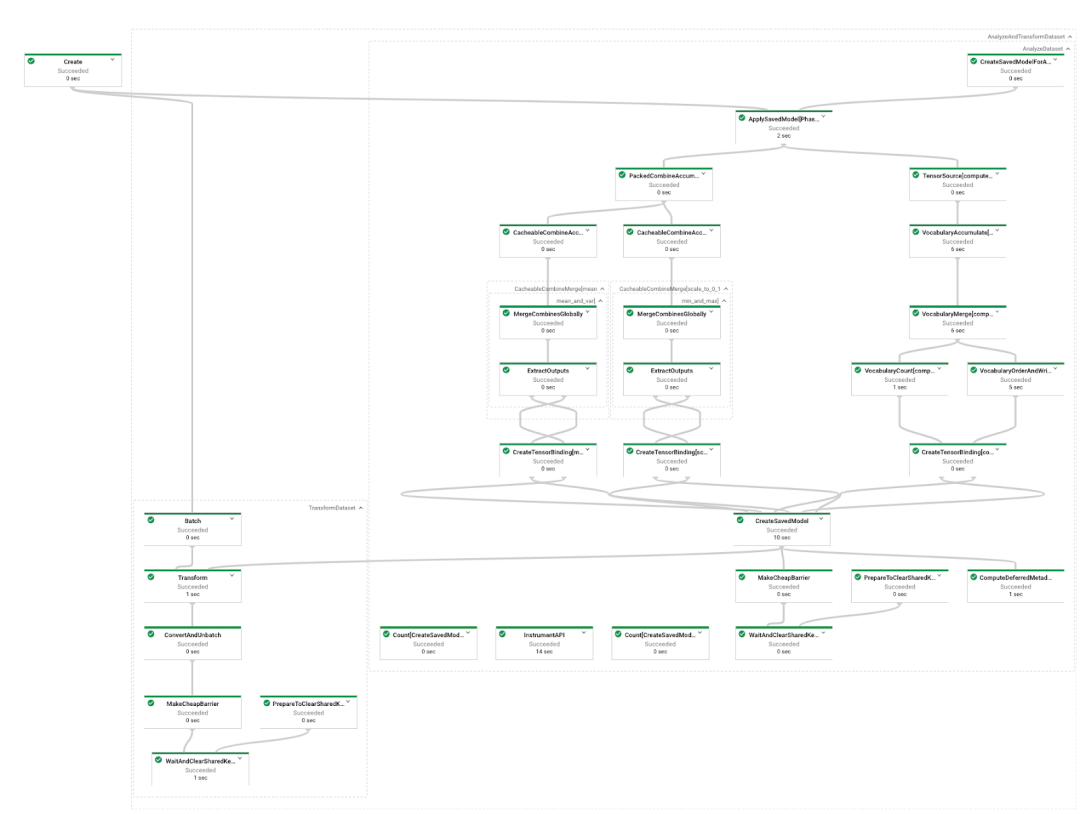
将 TFX 组件与 Beam 搭配使用
接下来,我们使用一些根据 TFX 库构建的 TFX 组件。 我们将使用 ExampleGen 提取数据,并使用 StatisticsGen 生产描述性的统计信息。
ExampleGen
-
将数据拆分为训练和评估集合(默认情况下,2/3 的数据是训练数据,1/3 的数据是评估数据) -
将数据转化为 tf.Example 格式 将数据复制到 _tfx_root 目录下,以供其他组件访问
借助 BigQueryExampleGen,我们可以在 Google Cloud BigQuery 公共数据集中直接查询数据。
def createExampleGen(query: Text):
# Output 2 splits: train:eval=3:1.
output = example_gen_pb2.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
example_gen_pb2.SplitConfig.Split(
name='train', hash_buckets=3),
example_gen_pb2.SplitConfig.Split(name='eval', hash_buckets=1)
]))
return BigQueryExampleGen(query=query, output_config=output)
与运行 SQL 查询一样,此代码也会传递配置,通过 SplitConfig 对象定义数据拆分的方式。
此代码段将显示如何从 Google BigQuery 的公共数据集(Google Cloud 的数据仓库)中直接读取数据。此示例的数据源自芝加哥出租车出行公共数据集,位于
bigquery-public-data.chicago_taxi_trips.taxi_trips
注意:
如需公共数据集的详细信息,请访问以下网站:
https://cloud.google.com/bigquery/public-data/
下面的查询将以正确的格式提取数据,供 ExampleGen 处理。
query="""
SELECT
pickup_community_area,
fare,
EXTRACT(MONTH FROM trip_start_timestamp) trip_start_month,
EXTRACT(HOUR FROM trip_start_timestamp) trip_start_hour,
EXTRACT(DAYOFWEEK FROM trip_start_timestamp) trip_start_day,
UNIX_Millis(trip_start_timestamp) trip_start_ms_timestamp,
pickup_latitude,
pickup_longitude,
dropoff_latitude,
dropoff_longitude,
trip_miles,
pickup_census_tract,
dropoff_census_tract,
payment_type,
company,
trip_seconds,
dropoff_community_area,
tips
FROM
`bigquery-public-data.chicago_taxi_trips.taxi_trips`
LIMIT 100
"""
注意:LIMIT 100 可将查询输出限制至 100 行,允许我们快速测试代码的正确性。
StatisticsGen
StatisticsGen TFX 流水线组件可为训练和评估数据生成描述性统计数据,此类数据可供其他流水线组件使用。基于之前 ExampleGen 的结果:
def createStatisticsGen(bigQueryExampleGen: BigQueryExampleGen):
# Computes statistics over data for visualization and example validation.
return StatisticsGen(examples=bigQueryExampleGen.outputs['examples'])
ExampleGen 的输出内容为 StatisticsGen 所需,因此现在这两个步骤之间存在依赖性问题。此生产者-消费者模式广泛应用于生产 ML 流水线。为实现流水线自动化,我们需要使用某种工具来协调这些依赖关系。
流水线编排
编排解决方案之一是编写简单的轻量级 Python 脚本。但是,如何解决调试、故障模式、重试、日志记录等问题?
我们很幸运,将 TFX 与两个流水线编排引擎(Kubeflow 和 Apache Airflow)集成即可解决这类问题。
除了这两种编排引擎,我们还可以使用 Apache Beam,因为这些依赖关系可建模为 DAG。因此,我们将结合 DAG 的转换来使用 DAG。“我们必须深入研究”:-)。
对所用引擎的选择取决于您的需求和要求,不在本文讨论的范围内。在本文中,我们选择使用 Apache Beam 进行编排,并使用 TFX 的 BeamDagRunner。因此 Beam 将以两种不同的角色工作,既要充当处理数据的执行引擎,又要充当为 tfx 任务排序的编排器。
# Used for setting up the orchestration 用于设置编排
from tfx.orchestration import pipeline
from tfx.orchestration import metadata
from tfx.orchestration.beam.beam_dag_runner import BeamDagRunner
以下代码会创建可供 BeamDagRunner 执行的流水线对象。
from typing import Text
from typing import Type
def createTfxPipeline(pipeline_name: Text, pipeline_root: Text, query: Text,
beam_pipeline_args) -> pipeline.Pipeline:
output = example_gen_pb2.Output(
# Output 2 splits: train:eval=3:1.
split_config=example_gen_pb2.SplitConfig(splits=[
example_gen_pb2.SplitConfig.Split(name='train', hash_buckets=3),
example_gen_pb2.SplitConfig.Split(name='eval', hash_buckets=1)
]))
# Brings data into the pipeline or otherwise joins/converts training data.
example_gen = BigQueryExampleGen(query=query, output_config=output)
# Computes statistics over data for visualization and example validation.
statistics_gen = StatisticsGen(examples=example_gen.outputs['examples'])
return pipeline.Pipeline(
pipeline_name=pipeline_name,
pipeline_root=pipeline_root,
components=[
example_gen, statistics_gen
],
metadata_connection_config=metadata.sqlite_metadata_connection_config(
os.path.join(".", 'metadata', pipeline_name,'metadata.db')),
enable_cache=False,
additional_pipeline_args=beam_pipeline_args)为测试流水线,我们将使用 LIMIT 100 进行查询,以返回一百行数据,并使用 DirectRunner 在本地处理数据。注意参数中的 --runner=directRunner。
tfx_pipeline = createTfxPipeline(
pipeline_name="my_first_directRunner_pipeline",
pipeline_root=LOCAL_PIPELINE_ROOT,
query=query,
beam_pipeline_args= {
'beam_pipeline_args':[
'--project={}'.format(GOOGLE_CLOUD_PROJECT),
'--runner=DirectRunner']})
BeamDagRunner().run(tfx_pipeline)
您可看到 tfds 与 LOCAL_PIPELINE_ROOT 的结果如以下所述:
import os
import tensorflow_data_validation as tfdv
stats = tfdv.load_statistics(os.path.join(LOCAL_PIPELINE_ROOT,"StatisticsGen","statistics","","train","stats_tfrecord"))
tfdv.visualize_statistics(stats)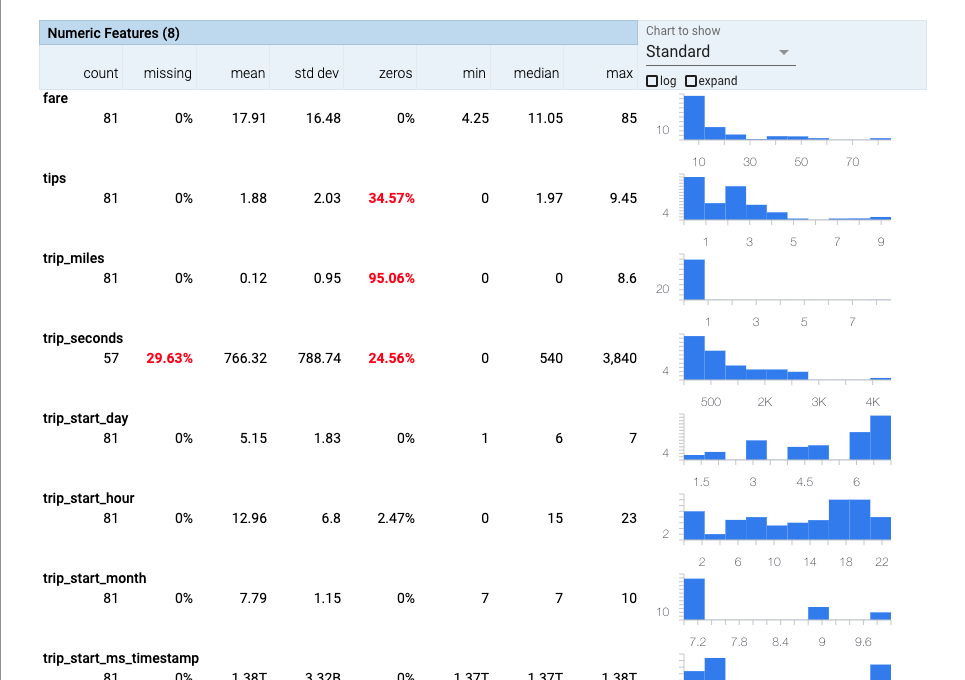
处理一百行尚可,但如果目标是处理数据集中的全部 187,002,0025 行呢?因此,您需要从 DirectRunner 切换到生产 Dataflow Runner。为完成切换,您还需要设置若干环境参数:
tfx_pipeline = createTfxPipeline(
pipeline_name="my_first_dataflowRunner_pipeline",
pipeline_root=GOOGLE_CLOUD_STORAGE_PIPELINE_ROOT,
query=query,
beam_pipeline_args={
'beam_pipeline_args':[
'--project={}'.format(GOOGLE_CLOUD_PROJECT)
,
'--temp_location={}'.format(GOOGLE_CLOUD_TEMP_LOCATION),
'--setup_file=./setup.py',
'--runner=DataflowRunner']})
BeamDagRunner().run(tfx_pipeline)
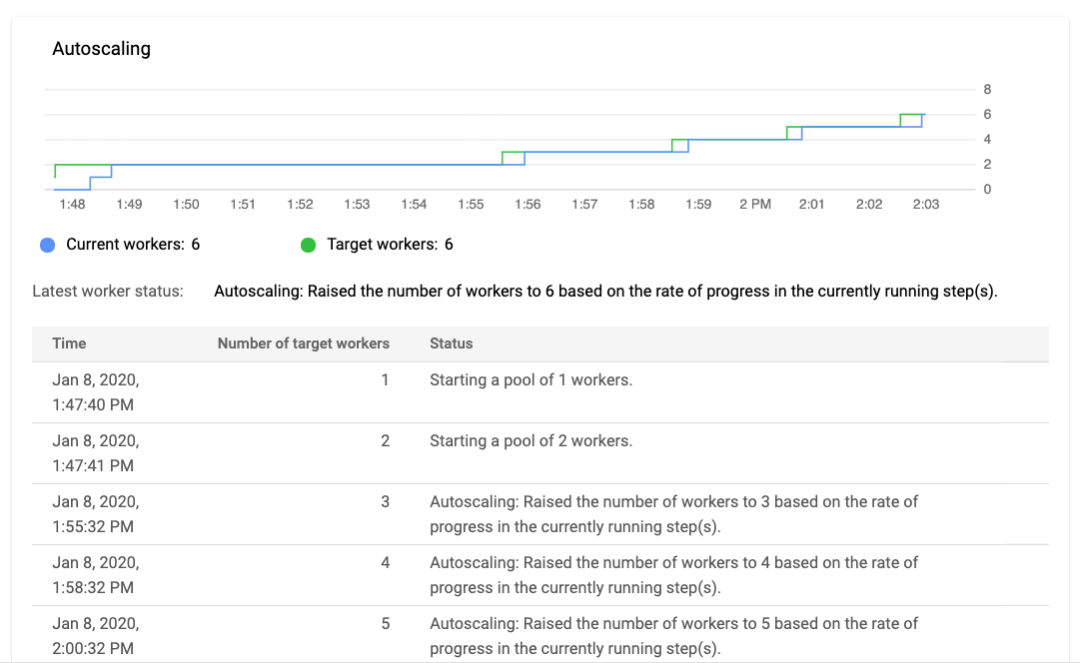
BeamDagRunner 可将 ExampleGen 和 StatisticsGen 作为单独的流水线进行提交,并可确保在启动 StatisticsGen 之前先成功完成 ExampleGen 的作业。此 Dataflow 服务可自动安排运行工作线程、自动调节、在工作线程出现故障时重试、集中日志记录和监控。 自动调节基于各种信号,包括吞吐率,如下图所示:
Dataflow 监控控制台会显示流水线的各种指标,例如工作线程的 CPU 使用率。我们可在下图中看到机器投入运行时的使用率,该指标因大多数工作线程的使用率超过 90% 并一直保持:
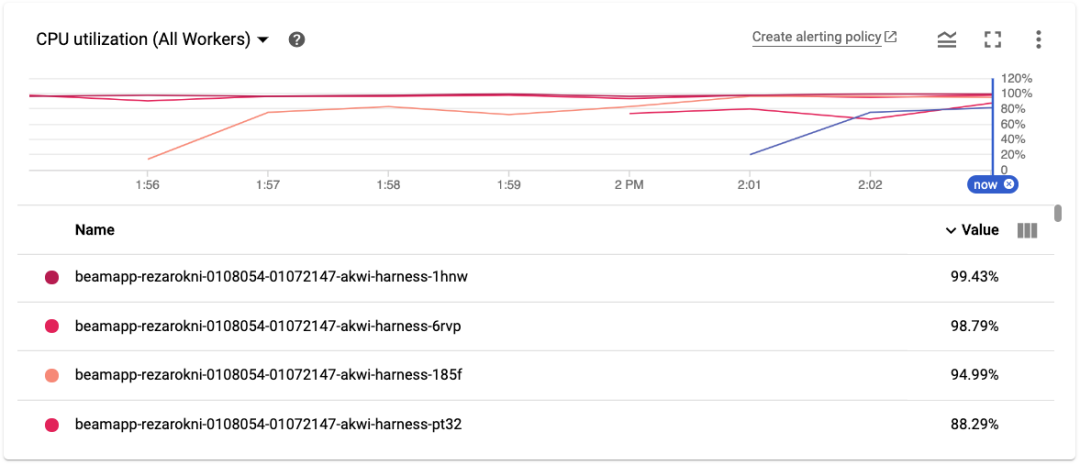
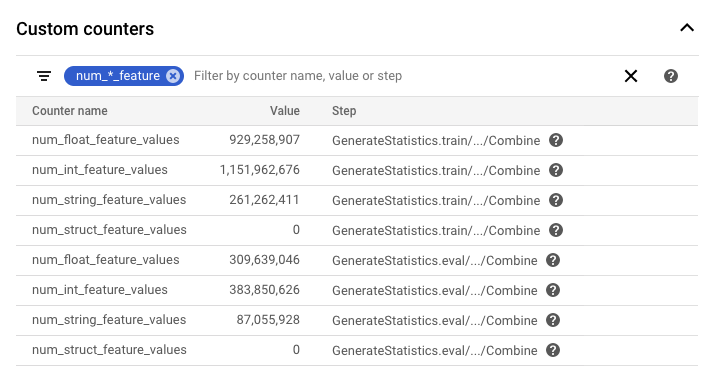
Apache Beam 支持自定义计数器,可让开发者在其流水线中创建指标。TFX 团队已使用此功能为各种组件创建有用的信息计数器。在下图中,我们可以看到在 StatistcsGen 运行期间记录的一些计数器。针对关键词“num_*_feature”进行筛选后,大致有十亿个整型和浮点特征值。
总结
在本文中,我们介绍了 TFX 如何使用 Apache Beam 从开发环境轻松切换到生产基础架构,而无需更改核心代码。我们首先介绍 TFX 库,然后介绍流水线以及两个核心 TFX 流水线组件 ExampleGen 和 StatisticsGen。
更多信息
如要了解有关 TFX 的更多信息,请访问 TFX 网站,加入 TFX 讨论小组,阅读 TFX 相关文章。
如果您想详细了解 本文提及 的相关内容,请参阅以下文档。这些文档深入探讨了这篇文章中提及的许多主题:
TensorFlow Data Validation
https://tensorflow.google.cn/tfx/guide/tfdvTensorFlow Transform
https://tensorflow.google.cn/tfx/transform/api_docs/python/tftTensorFlow Model Analysis
https://tensorflow.google.cn/tfx/model_analysis/api_docs/python/tfma预处理数据(初学者)
https://tensorflow.google.cn/tfx/tutorials/transform/simple
TensorFlow Transform (tf.Transform)
https://tensorflow.google.cn/tfx/transform/Apache Beam
https://beam.apache.org/特殊语法定义和调用转换
https://beam.apache.org/documentation/programming-guide/#applying-transforms此操作在堆栈轨迹中名为为此步骤命名
https://stackoverflow.com/questions/50519662/what-does-the-redirection-mean-in-apache-beam-pythonBigQueryExampleGen
https://tensorflow.google.cn/tfx/api_docs/python/tfx/components/example_gen/big_query_example_gen/component/BigQueryExampleGen
Kubeflow
https://www.kubeflow.org/Apache Airflow
https://airflow.apache.org/TFX 网站
https://tensorflow.google.cn/tfxTFX 讨论小组
https://groups.google.com/a/tensorflow.org/forum/#!forum/tfx
了解更多请点击 “阅读原文” 访问官网。







