前两天,机器学习顶会 ICML 公布了 2022 年的论文获奖情况,包括 15 篇杰出论文奖和 1 项时间检验奖。其中,复旦大学、上海交通大学、厦门大学、莱斯大学胡侠团队等多个华人团队的研究获得杰出论文奖。ICML 2012 关于「投毒攻击」的论文《Poisoning Attacks against Support Vector Machines》获得了大会的时间检验奖。
一次性评选出 15 篇杰出论文,这个不同于寻常的做法引起了研究者们的关注。与此同时,部分获奖论文的内容也在推特上引起了强烈的争议。
论文 1:Bayesian Model Selection, the Marginal Likelihood, and Generalization
引起争议的第一篇论文是纽约大学的研究《Bayesian Model Selection, the Marginal Likelihood, and Generalization》。
![]()
论文地址:https://proceedings.mlr.press/v162/lotfi22a/lotfi22a.pdf
这篇论文首先回顾了学习约束和假设检验的边际似然所具有的特性,之后强调了在使用边际似然作为泛化代理(proxy)的概念和实际问题。论文展示了边际似然如何与泛化负相关,还介绍了其与神经架构搜索的含义,可能导致超参数学习中欠拟合和过拟合问题。
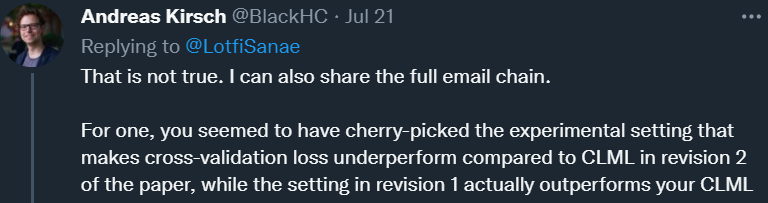
质疑的声音之一来自牛津大学博士生 Andreas Kirsch,他之前曾在谷歌、DeepMind 工作。他表示,在指出了论文的一个 bug 后,作者重新运行了一些实验,但之后得到的结果相互矛盾。
![]()
不过,这一说法遭到了论文一作 Sanae Lotfi 的反驳,她表示,他们在 camera-ready 版本中重新运行了所有会被那个小 bug 影响的实验,得到的定性结果没变。
![]()
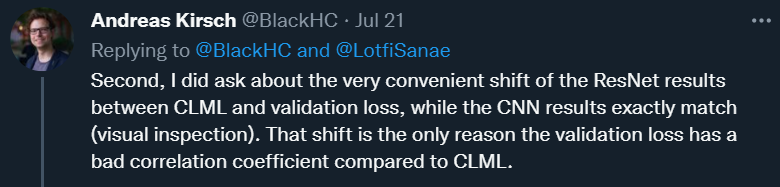
对于这一回复,Andreas Kirsch 并不买账,并接着指出了三点问题。其中一点是,他认为 Sanae Lotfi 组精心挑选了实验配置,使得交叉验证损失的表现低于论文 revision 2 的 CLML,而 revision 1 中的设置实际上优于作者的 CLML。
![]()
![]()
![]()
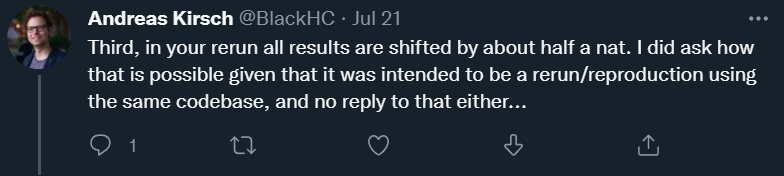
另外,值得注意的是,Andreas Kirsch 表示,能够显示这些矛盾的消融实验在提交给 ICML 的 camera-ready 版本中已经被移除,目前仅能从 arxiv 的第一版和第二版中看到。他认为,作者在给 ICML 的 camera-ready 版本中巧妙地回避了这些问题。
![]()
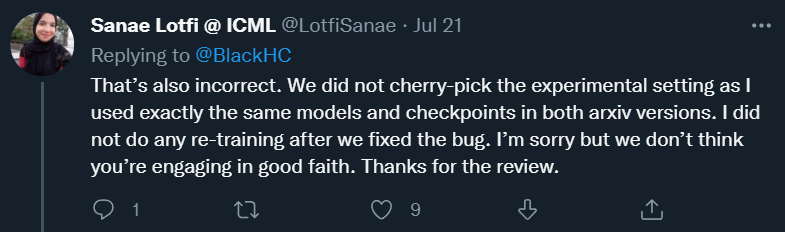
Sanae Lotfi 反驳了 Andreas Kirsch 关于精心挑选实验设置的指控,并表示他们在两个 arXiv 版本中使用了完全相同的模型和检查点,而且在修复 bug 后,他们没有再进行任何的二次训练。
![]()
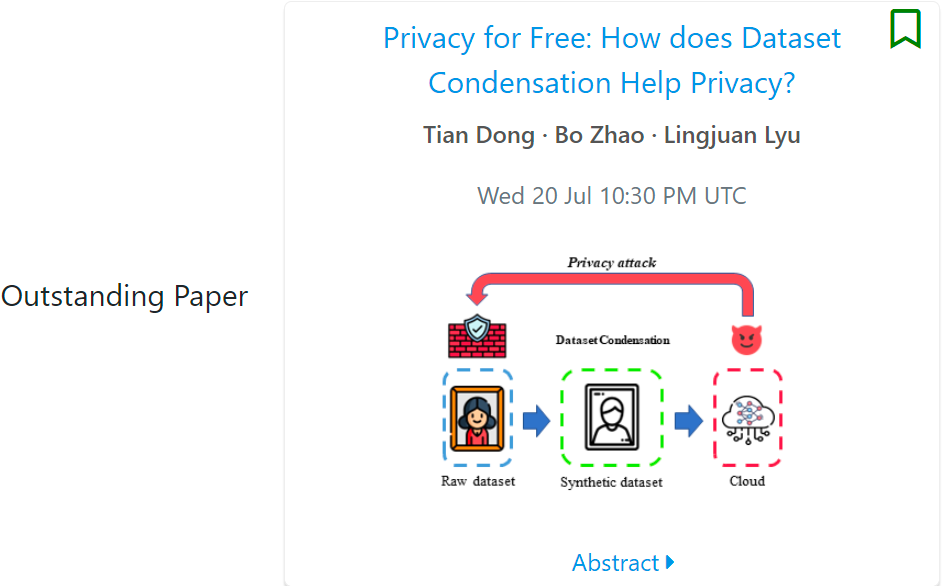
论文 2:Privacy for Free: How does Dataset Condensation Help Privacy?
引起争议的第二篇论文是上海交通大学、爱丁堡大学、Sony AI 的研究《Privacy for Free: How does Dataset Condensation Help Privacy?》
![]()
论文链接:https://proceedings.mlr.press/v162/dong22c.html
根据论文摘要,这项研究首次发现了旨在提高训练效率的数据集压缩(DC)方法也是替代传统数据生成器进行私有数据生成的良好解决方案。为了证明 DC 的隐私优势,该研究在 DC 和差分隐私之间建立了联系。这项工作是「数据高效和隐私保护机器学习的一个里程碑」。
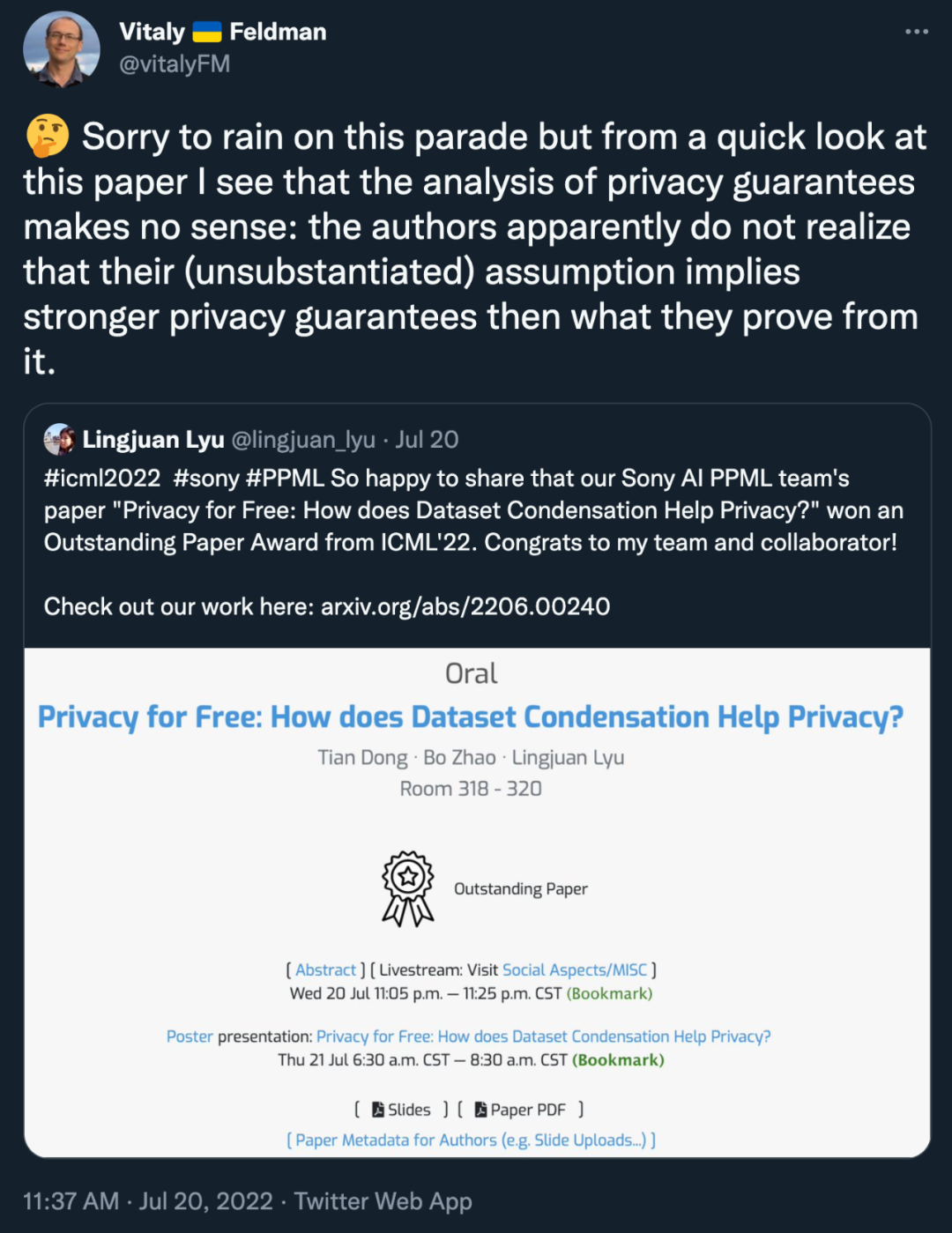
苹果研究科学家 Vitaly Feldman 的说法是:「(这篇论文)对隐私保证的分析毫无意义。作者显然没有意识到他们的(未经证实)的隐私保证的假设比他们所能证明的强大得多。」
![]()
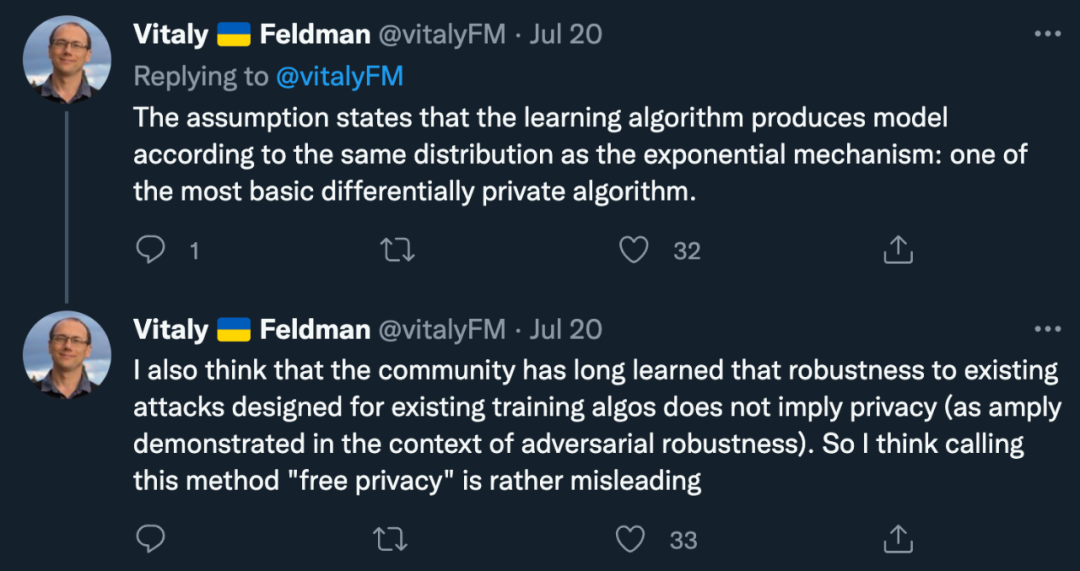
「该假设表明,学习算法根据与指数机制相同的分布生成了模型:这是最基本的差分隐私算法之一。我认为社区早就知道,针对现有训练算法设计的现有攻击的鲁棒性并不意味着隐私。所以我认为将这种方法称为 free privacy 是一种误导。」
![]()
![]()
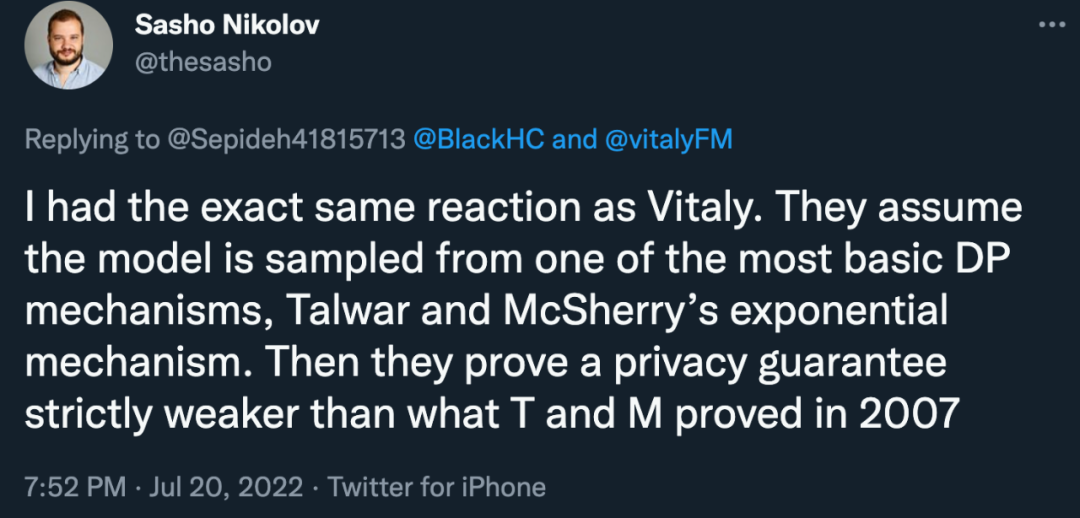
支持 Vitaly Feldman 观点的学者不在少数。多伦多大学副教授 Sasho Nikolov 认为:「他们假设模型是从最基本的 DP 机制之一(Talwar、 McSherry 2007 年的指数机制)中采样的,然后他们证明了一种比 Talwar、 McSherry 当年证明的还要弱的隐私保证。」
![]()
滑铁卢大学教授 Gautam Kamath 甚至表示:「论文数量(甚至获奖论文)是一个毫无意义的指标。如果你不这么认为,请记住这个例子:大多数隐私专家(包括我)都存在与 Vitaly、Sasho 一样的担忧。但不知何故,这些始终被忽视,直到它被评为杰出论文?」
![]()
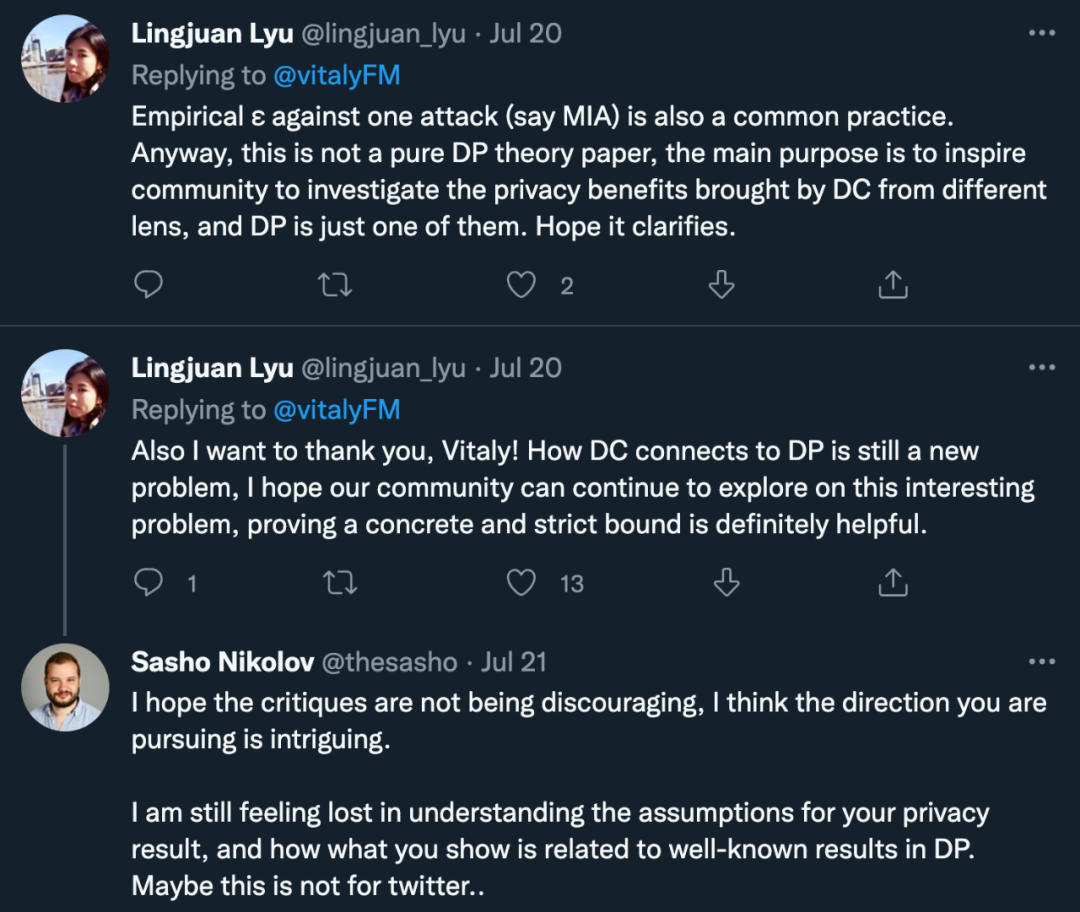
「并非是对作者不尊重,探索数据集浓缩的问题是一个有趣的问题。但我希望审稿人能进行更具批判性和探索性的阅读。我也有兴趣了解奖项委员会的流程。他们是否批判性地阅读了这篇论文?」
![]()
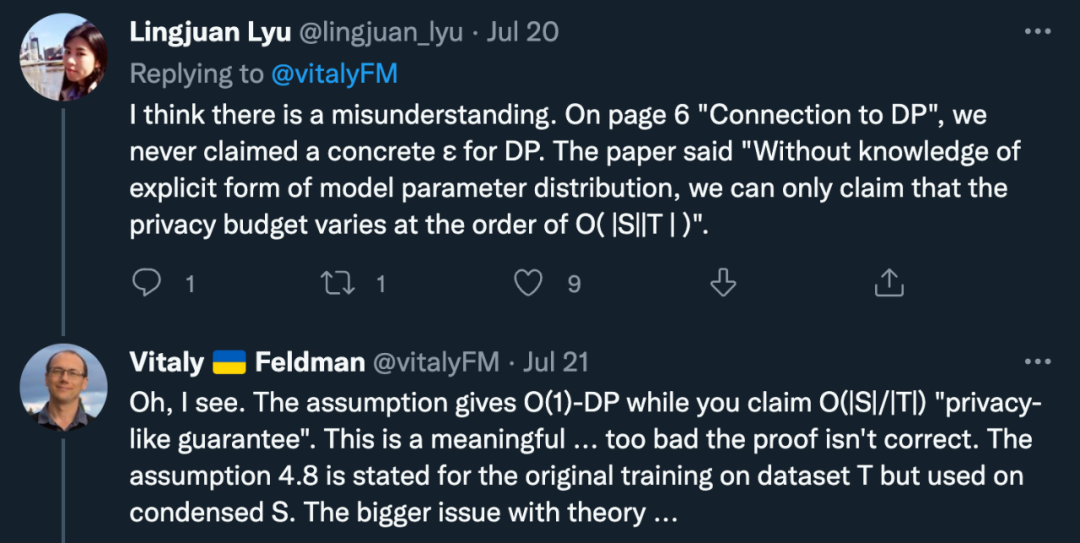
归根结底,与其说是对论文内容或作者的质疑,不如说是对 ICML 会议审稿程序的质疑。而具体到「DC 与 DP 的连接」问题上,研究者们都认为这确实是一个值得探讨的好方向,但目前这篇论文的内容无法支撑起作者们想要证明的结论。
![]()
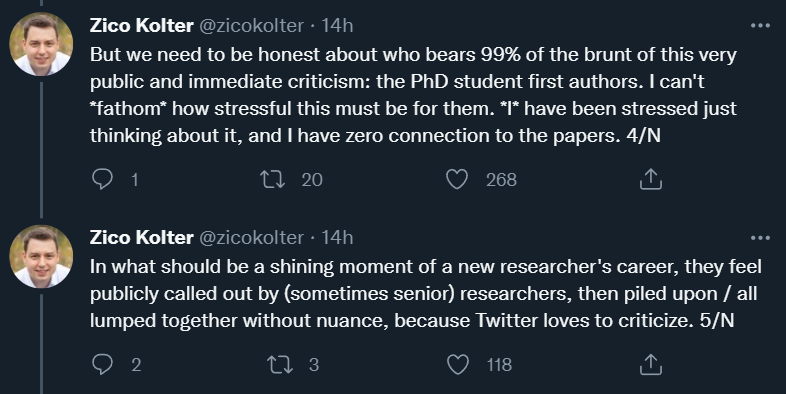
除了论文本身可能存在的问题,关于这种问题的处理方式也在推特、reddit 上引发了争论。很多人认为,对于一些初出茅庐的博士生来说,这种在社交媒体上被大佬们点名批评的压力确实是太大了,而且这种压力主要集中在一作身上,想想都觉得窒息。
![]()
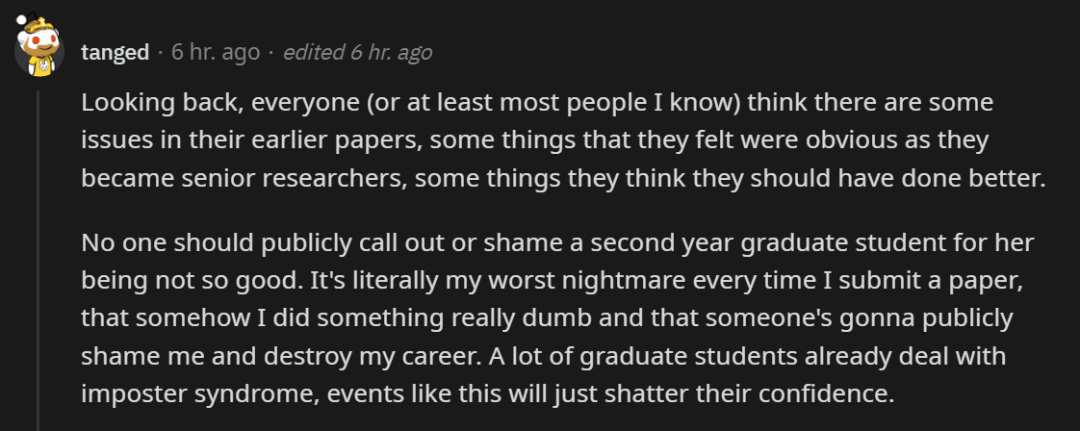
其实,每个成熟的研究者在回顾自己早期的工作时,都会发现一些不完美的地方。如果大家都以这种公开的方式打击他们,他们的自信可能会受到严重影响,甚至患上冒名顶替综合征。
![]()
如果文章真的有一些问题,那审稿人、评奖人也有责任,只批评作者是没有意义的。
![]()
![]()
那发现获奖论文有问题时,正确的解决方式是怎样的?有人提议说:或许可以试试提交一篇纠错的新论文。
![]()
参考链接:https://www.reddit.com/r/MachineLearning/comments/w4ooph/d_icml_2022_outstanding_paper_awards/?utm_source=share&utm_medium=web2x&context=3
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com