超越EfficientNet,GPU上加速5倍,何恺明组CVPR 2020论文提出新型网络设计范式
选自arXiv
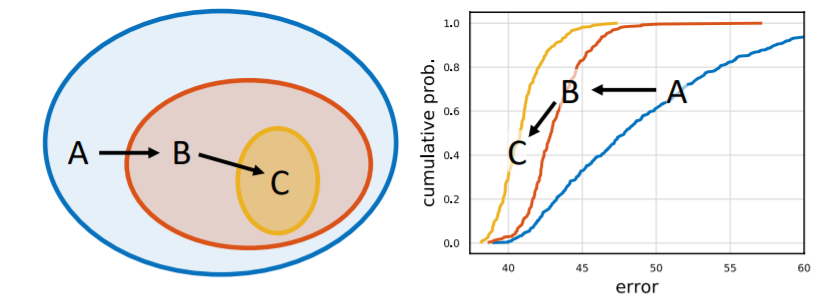
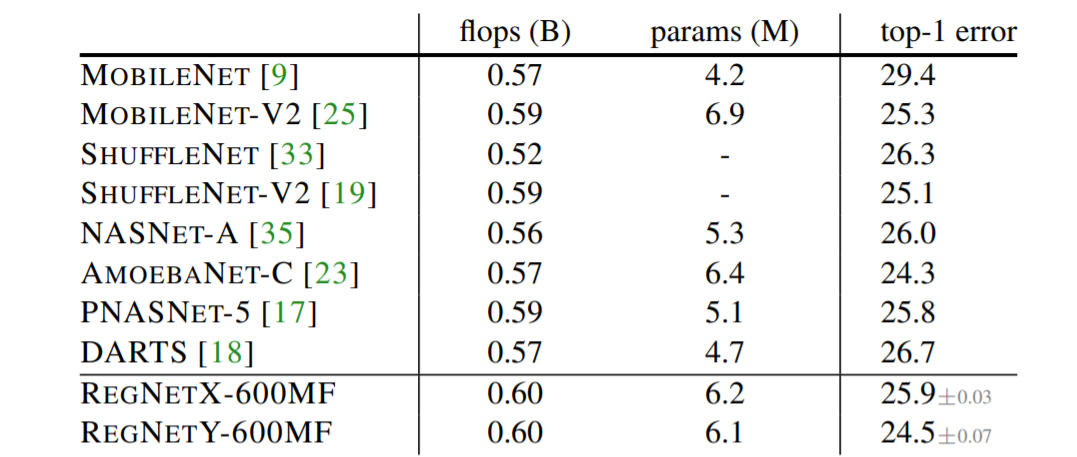
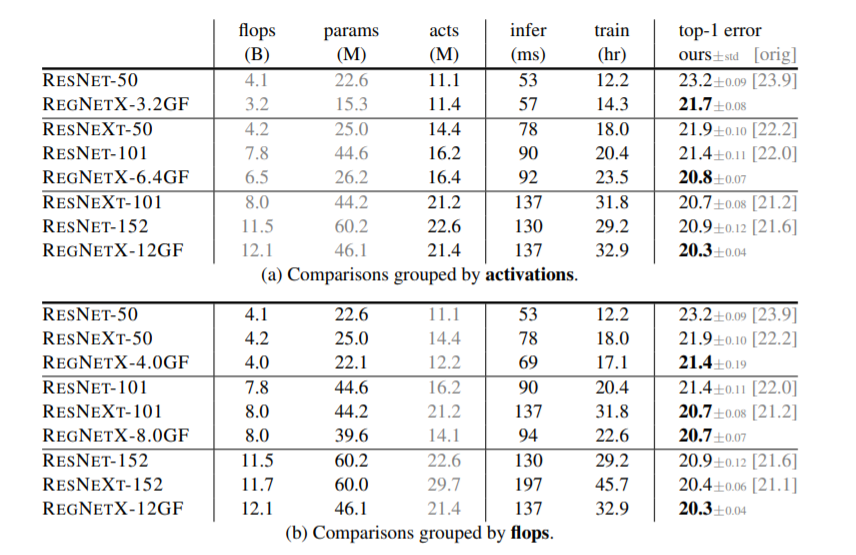
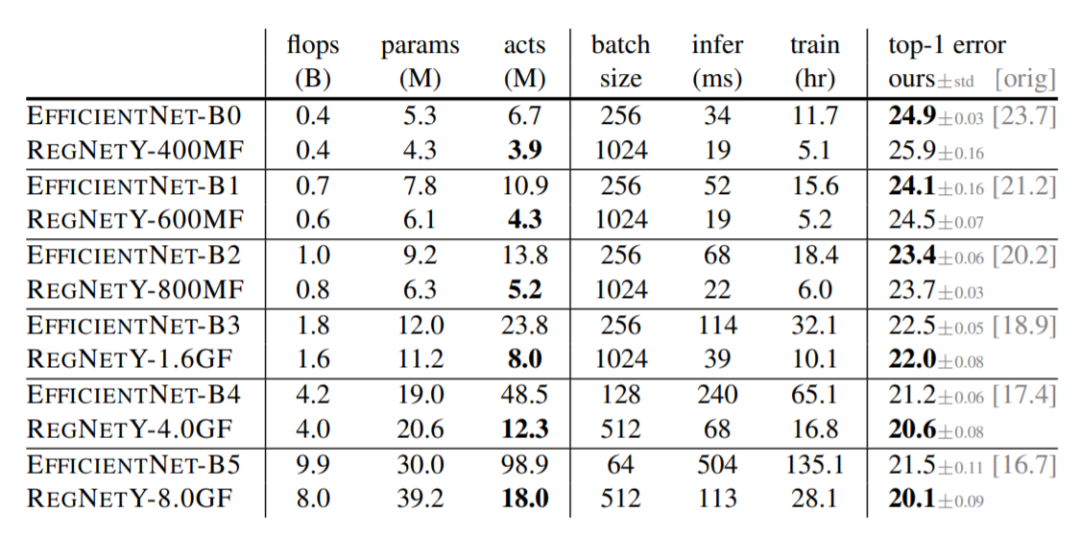
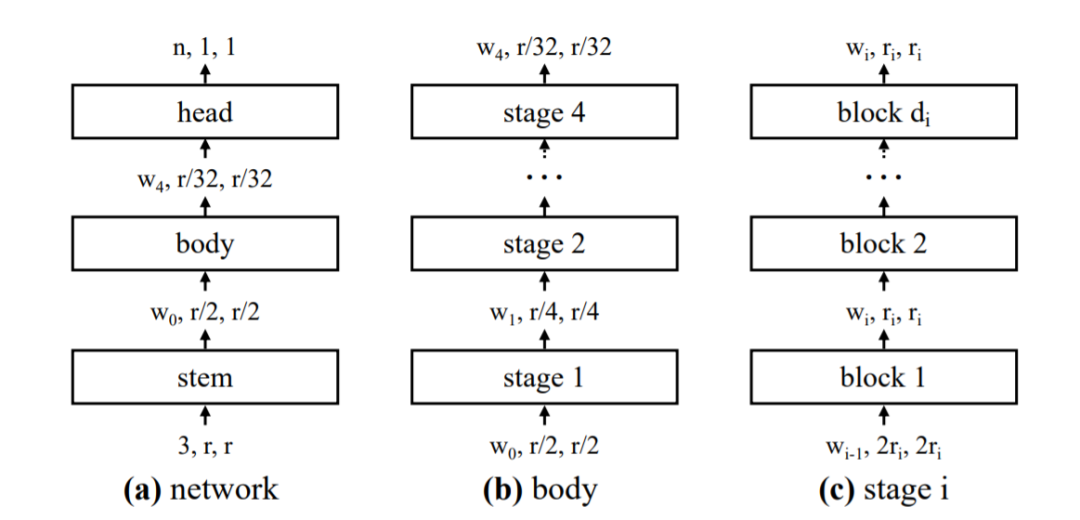
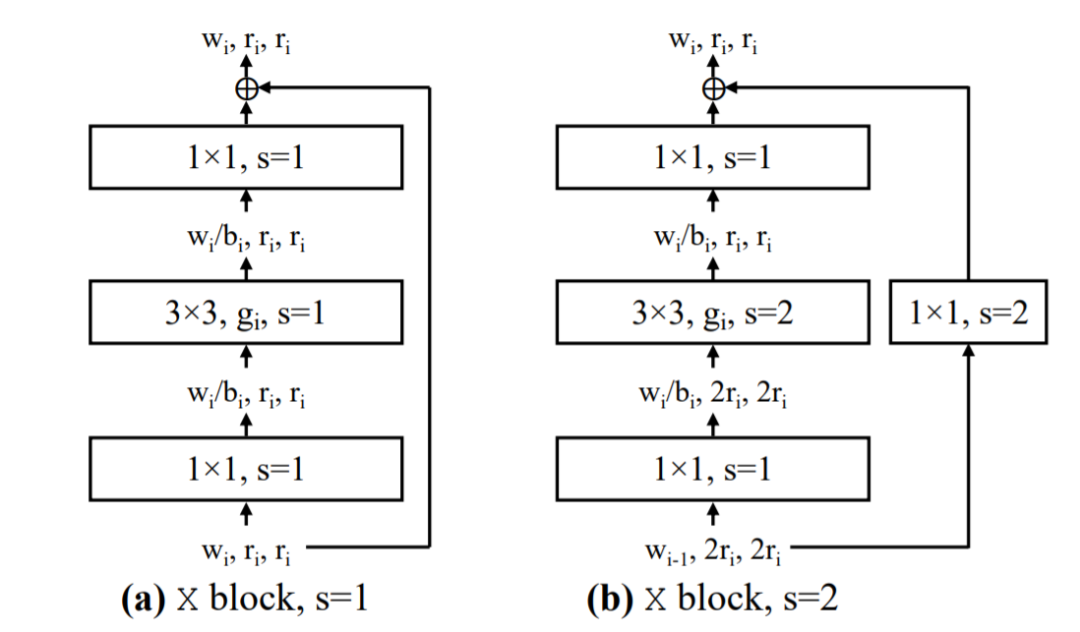
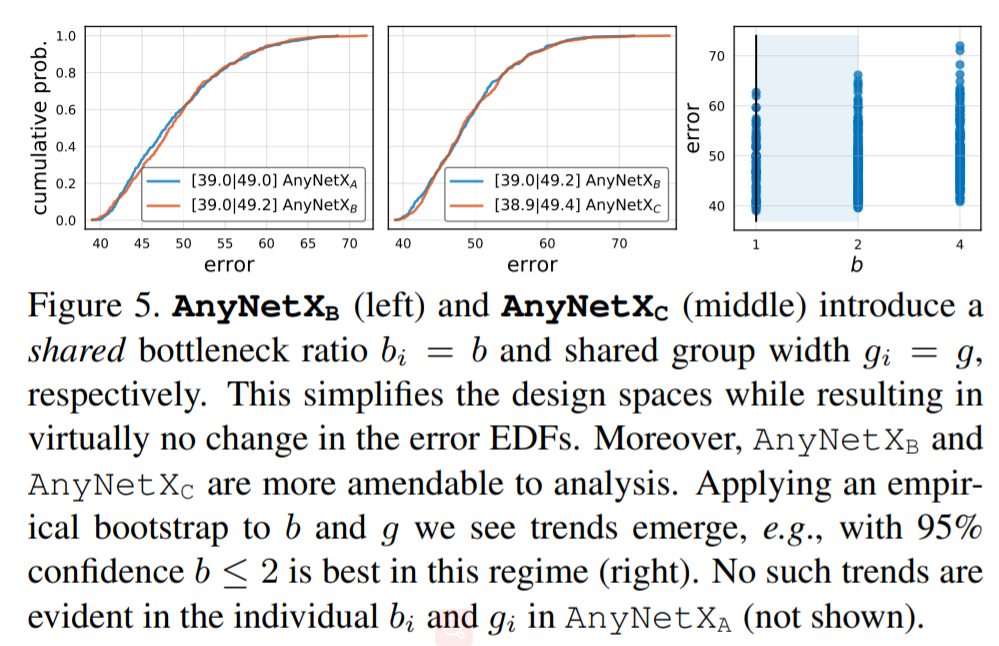
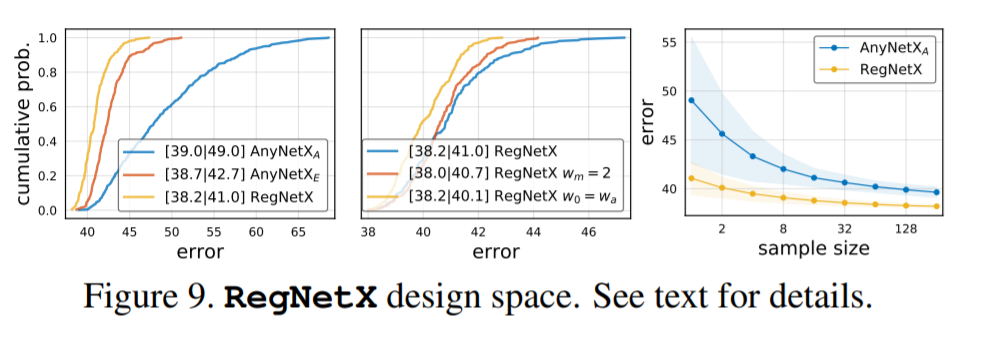
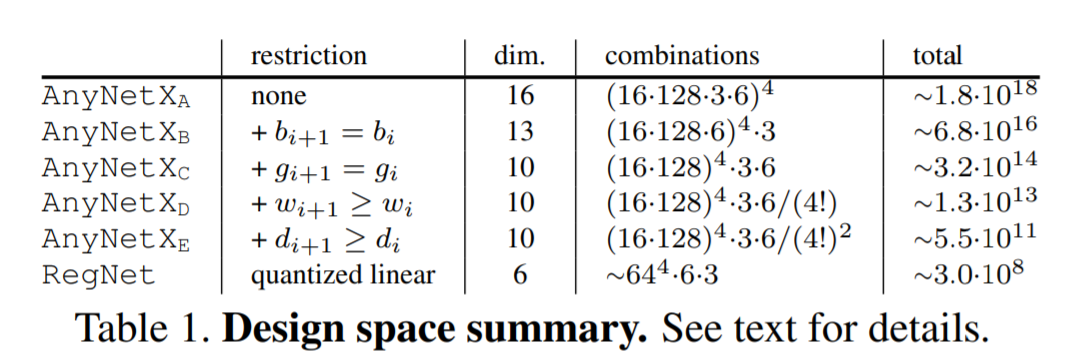
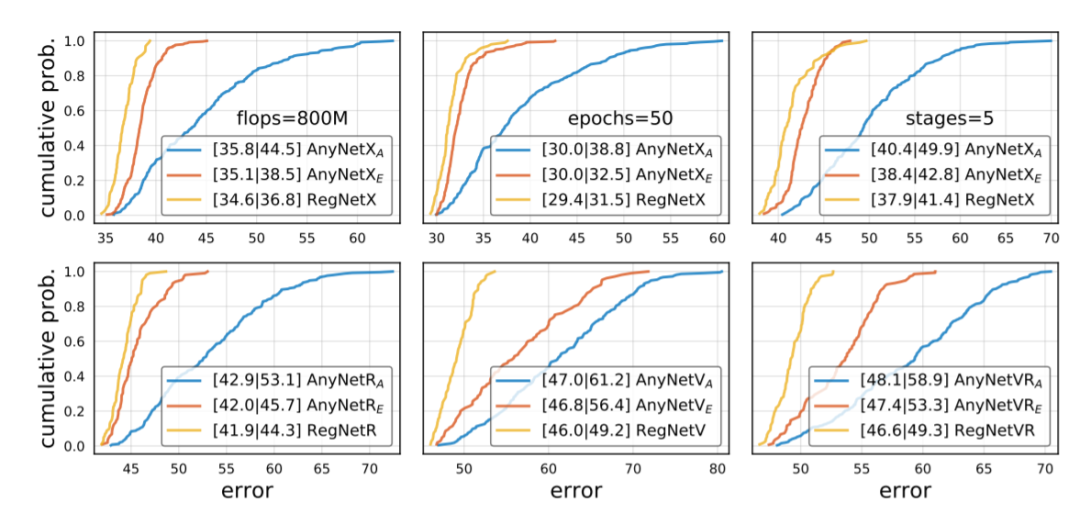
近日,何恺明大神组又发了一篇新论文,提出了一种新的网络设计范式。与以往研究不同,他们没有专注于设计单个网络实例,而是设计出了参数化网络群的网络设计空间。这种新的网络设计范式综合了手工设计网络和神经架构搜索(NAS)的优点。在类似的条件下,他们设计出的网络超越了当前表现最佳的 EfficientNet 模型,在 GPU 上实现了 5 倍的加速。目前,该论文已被 CVPR 2020 接收。



登录查看更多
相关内容

相关VIP内容
相关资讯
相关论文