使用 FastAI 和即时频率变换进行音频分类

本文为 AI 研习社编译的技术博客,原标题 :
Audio Classification using FastAI and On-the-Fly Frequency Transforms
作者 | John Hartquist
翻译 | 胡瑛皓
校对 | 酱番梨 审核 | Pita 整理 | 立鱼王
原文链接:
https://towardsdatascience.com/audio-classification-using-fastai-and-on-the-fly-frequency-transforms-4dbe1b540f89
注:本文的相关链接请访问文末【阅读原文】
简介
目前深度学习模型能处理许多不同类型的问题,对于一些教程或框架用图像分类举例是一种流行的做法,常常作为类似“hello, world” 那样的引例。FastAI 是一个构建在 PyTorch 之上的高级库,用这个库进行图像分类非常容易,其中有一个仅用四行代码就可训练精准模型的例子。随着v1版的发布,该版本中带有一个data_block的API,它允许用户灵活地简化数据加载过程。今年夏天我参加了Kaggle举办的Freesound General-Purpose Audio Tagging 竞赛,后来我决定调整其中一些代码,利用fastai的便利做音频分类。本文将简要介绍如何用Python处理音频文件,然后给出创建频谱图像(spectrogram images)的一些背景知识,示范一下如何在事先不生成图像的情况下使用预训练图像模型。
点击原文查看文中涉及的代码,以及相关的notebooks。
音频文件转图像
起初把音频文件作为图像分类听起来有些怪异。图像是二维数据(其中包含RGBA等4个通道), 而音频文件通常是一维的 (可能包含2个维度的通道,单声道和立体声)。本文只关注单声道的音频文件。我们知道,每个音频文件会有一个采样率,即音频的每秒采样数。如果文件是一个3秒长采样率为44100Hz的声音片段,这就意味着文件是由 3*44100 = 132300 表示气压变化的连续数字组成。 librosa是Python中处理音频效果最好的库。
clip, sample_rate = librosa.load(filename, sr=None)clip = clip[:132300] # first three seconds of file
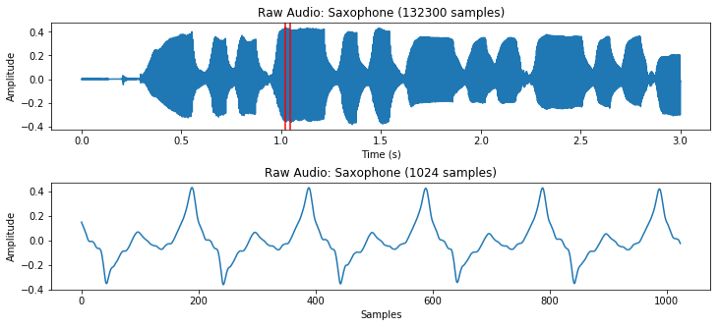
虽然从上图可以感受到各时点音频的响亮或安静程度,但图中基本看不出当前所在的频率。为获得频率,一种非常通用的方案是去获取一小块互相重叠的信号数据,然后运行Fast Fourier Transform (FFT) 将数据从时域转换为频域。经过FFT处理后,我们可以将结果转换为极坐标,就得到不同频率的幅度和相位。虽然相位信息在某些情况下适用,本文中主要适用幅度信息,我们将其转换为分贝单位,因为耳朵是以对数尺度感知声音的。
n_fft = 1024 # frame lengthstart = 45000 # start at a part of the sound thats not silencex = clip[start:start+n_fft]X = fft(x, n_fft)X_magnitude, X_phase = librosa.magphase(X)X_magnitude_db = librosa.amplitude_to_db(X_magnitude)
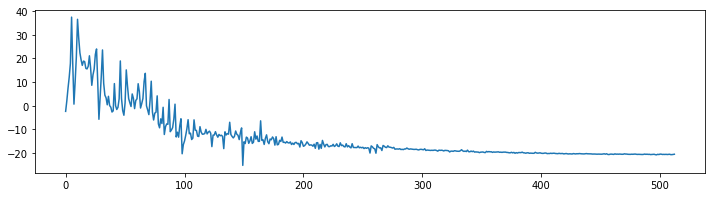
以1024为长度计算FFT,我们得到一个以1024为频点的频谱。谱的第二部分是多余的,因而实际处理我们只用前(N/2)+1个频点,在本例中也就是513。
我们用一个采样窗口长度为1024的FFT计算获取整个文件的频谱信息,每次计算向前滑动512个样本(hop length),这样采样窗口就会互相重叠。第二个文件将产生步长为259的频谱,可以看作是一张二维图像。我们把这些操作称为短时傅里叶变化(STFT),它可以提供一段时间内频率变化的信息。
stft = librosa.stft(clip, n_fft=n_fft, hop_length=hop_length)stft_magnitude, stft_phase = librosa.magphase(stft)stft_magnitude_db = librosa.amplitude_to_db(stft_magnitude)
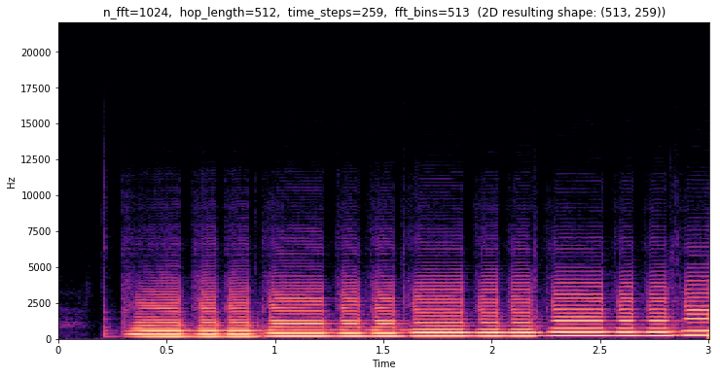
本例中我们可以看到那些有趣的频率,所有低于12500 Hz的数据。另外可以看到有相当多的无用的频点,这些信息并没有准确反映人类是如何感知频率的。事实上人类是以对数尺度的频率结合声音强弱来进行感知的。我们可以分辨对数尺度上相同‘距离’的频率,比如50Hz到100Hz,这感受如同400Hz到800Hz的变化。
这就是为什么许多人会用 melspectrogram 表示频谱的原因,该操作即将频点转换为梅尔刻度(mel scale)。用Librosa库,可以方便的把常规的谱数据转换为melspectrogram格式,我们需要定义有多少“点” ,并给出需要划分的最大最小频率范围。
mel_spec = librosa.feature.melspectrogram(clip, n_fft=n_fft, hop_length=hop_length, n_mels=n_mels, sr=sample_rate, power=1.0, fmin=fmin, fmax=fmax)mel_spec_db = librosa.amplitude_to_db(mel_spec, ref=np.max)
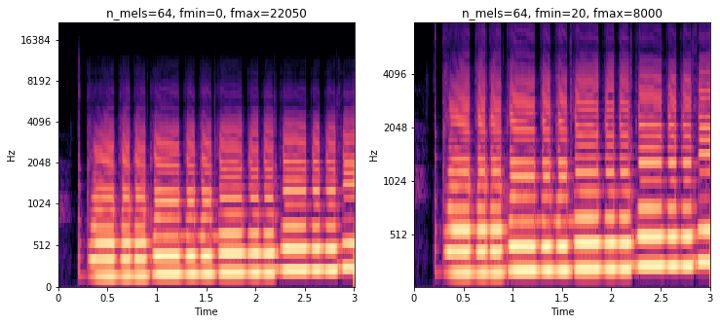
上面的melspectrogram我采用的频点数为64(n_mels)。不同点在于,右侧图像里只关注20Hz到8000Hz的频率范围。 这样显著减少了从最初513点每时点进行转换的规模。
用fastai分类声音频谱
虽然我们可以分类原始声音波形数据,但目前更流行用melspectrogram分类音频,这种方法相当好用。那么我们需要将整个数据集用上述方法转换为频谱图。在GCP实例上用了所有CPU,我大约花了10分钟处理完这些数据。以下是我生成melspectrogram用到的参数:
n_fft = 1024hop_length = 256n_mels = 40f_min = 20f_max = 8000sample_rate = 16000
本文从此处往下,我采用的都是NSynth数据集,该数据集由Google Magenta团队提供。该数据集非常有趣,是由305979个音符组成,每段长4秒。我裁剪了这个数据集,只保留用声学方法生成的音符,这样管理起来相对简单。分类目标是从10种乐器家族中分辨出音符是由哪个乐器家族产生的。
用fastai最新的data_block API,大大简化了构建DataBunch对象的过程,数据集包括所有频谱图像机器对应的标签—— 本例中用正则表达式通过解析文件名获得所有分类标签。
NSYNTH_IMAGES = 'data/nsynth_acoustic_images'instrument_family_pattern = r'(\w+)_\w+_\d+-\d+-\d+.png$'data = (ImageItemList.from_folder(NSYNTH_IMAGES).split_by_folder().label_from_re(instrument_family_pattern).databunch())
数据一旦加载完成实例化预训练卷积神经网络 (CNN) ,这里用的是 resnet18,然后在频谱上做fine-tune。
learn = create_cnn(data, models.resnet18, metrics=accuracy)learn.fit_one_cycle(3)
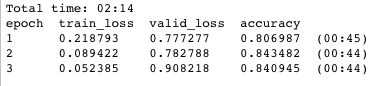
2分14秒后,模型在验证集(与训练集完全分离的数据集)上准确度达到了84% 。当然数据一定有一些过拟合,这里没有做数据增强或类似正则化的优化,不过这是一个很不错的开始!
利用fastai提供的ClassificationInterpretation类,可以快速查看错误是从哪来的,如下:
interp = ClassificationInterpretation.from_learner(learn)interp.plot_confusion_matrix(figsize=(10, 10), dpi=60)
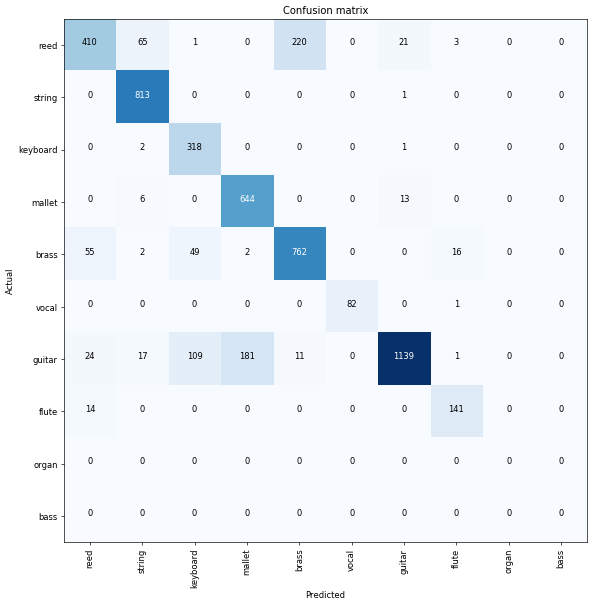
看起来木槌跟吉他有点混了,另外簧片声音月铜管乐器分不清。有了这些信息,我们可以更进一步查看这些乐器的频谱数据,看看是否可以调整参数,从而更好的分辨它们。
为什么在训练过程中生成频谱?
如果用图像分类音频效果这么好,你也许会问在训练过程中生成频谱图有什么好处(相对于之前的方法)。可能有这么几个原因:
生成图像的时间
前例中,我们花了10分钟产生所有图像的频谱图。我经常会尝试不同的参数设置,或把melspectrogram换成简单的STFT,这样就需要重新生成所有图片,这样就很难快速测试不同的参数配置。磁盘空间
同样的每次生成数据集后,数据集就会占用大量磁盘空间,大小依赖于数据集以及变换。本例中,生成的数据占了1G空间。数据增强
提升图像分类器性能的一个最有效的策略是采用数据增强。常规图像变换诸如(rotating, flipping, cropping等) 在谱分类算法中可能不怎么用得上。但是我们可以处理基于时域的音频文件,然后再转换为频谱,最后进行分类。GPU 与 CPU
过去我一直用 librosa 进行转换,主要用CPU。但我们可以用 PyTorch提供的stft方法,该方法可直接使用GPU处理,这样就会快很多,并且可以进行批处理 (而不是一次处理一张图)。
如何在训练过程中生成频谱?
前几天我一直在试验创建一个新的基于fastai的声音处理模块。后来参考great new fastai documentation,写出一个简单类用于加载原始音频文件,然后用PyTorch提供的方法使用GPU以批处理方式生成频谱。我也创建了一个 create_cnn 函数,裁剪预训练模型用以预测单通道数据(频谱) ,此前模型是使用3通道。让我惊喜的是,代码和图像分类器运行的速度差不多,不需要额外创建实际的图像。现在建立数据集的代码如下:
tfms = get_frequency_batch_transforms(n_fft=n_fft,n_hop=n_hop,n_mels=n_mels,sample_rate=sample_rate)data = (AudioItemList.from_folder(NSYNTH_AUDIO).split_by_folder().label_from_re(instrument_family_pattern)=batch_size, tfms=tfms))
fastai库支持预览批次中的数据:
data.show_batch(3)
在预训练模型上进行fine tuning跟之前步骤一样,这里不同的是需要把卷积的第一层修改为只接收单通道数据 (感谢fastai论坛的David Gutman).
learn = create_cnn(data, models.resnet18, metrics=accuracy)learn.fit_one_cycle(3)

这一次训练多花了30秒,执行了3个epoch后在验证集上的精度为80%! 之前在CPU上创建整个数据集大约需要10分钟。这样就可以进行快速试验,可以微调频谱的参数,同时也可以对谱计算进行各种增强。
未来的工作
现在的方法已经可以通过不落地的方法直接生成不同谱的表示,我对如何通过数据增强改进原始音频文件非常感兴趣。在librosa库中有很多方法,从pitch shifting到time stretching,随机选出音频的一段,可以做很多实验。
同时比较感兴趣的地方是,如果预训练模型是基于声音图像(而不是基于图像的),能否达到更好的精度。
最后感谢阅读本文! 如果有任何评论或改进请告诉我。你可以在以下地址找到所有代码和完整的笔记本:
https://github.com/sevenfx/fastai_audio.
资源
FastAI docs
PyTorch v1.0 docs
torchaudio: 汲取很多灵感
傅里叶变换入门教程: https://jackschaedler.github.io/circles-sines-signals/dft_introduction.html
Speech Processing for Machine Learning: Filter banks, Mel-Frequency Cepstral Coefficients (MFCCs) and What’s In Between
强烈推荐这篇Python声音信号处理教程: Audio Signal Processing for Musical Applications
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】即可访问:
https://ai.yanxishe.com/page/TextTranslation/1416
AI求职百题斩 · 每日一题






