如何用TensorFlow预测时间序列:TFTS库详细教程

作者 | 何之源
前言
如何用TensorFlow结合LSTM来做时间序列预测其实是一个很老的话题,然而却一直没有得到比较好的解决。如果在Github上搜索“tensorflow time series”,会发现star数最高的tgjeon/TensorFlow-Tutorials-for-Time-Series已经和TF 1.0版本不兼容了,并且其他的项目使用的方法也各有不同,比较混乱。
在刚刚发布的TensorFlow 1.3版本中,引入了一个TensorFlow Time Series模块(源码地址为:tensorflow/tensorflow,以下简称为TFTS)。TFTS专门设计了一套针对时间序列预测问题的API,目前提供AR、Anomaly Mixture AR、LSTM三种预测模型。
由于是刚刚发布的库,文档还是比较缺乏的,我通过研究源码,大体搞清楚了这个库的设计逻辑和使用方法,这篇文章是一篇教程帖,会详细的介绍TFTS库的以下几个功能:
读入时间序列数据(分为从numpy数组和csv文件两种方式)
用AR模型对时间序列进行预测
用LSTM模型对时间序列进行预测(包含单变量和多变量)
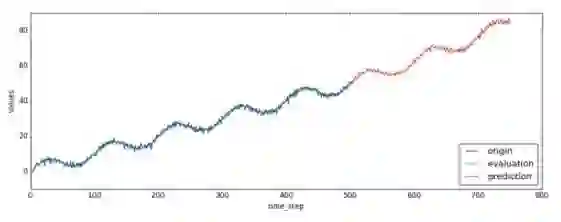
先上效果图,使用AR模型预测的效果如下图所示,蓝色线是训练数据,绿色为模型拟合数据,红色线为预测值:
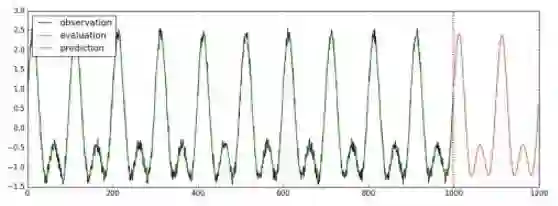
使用LSTM进行单变量时间序列预测:
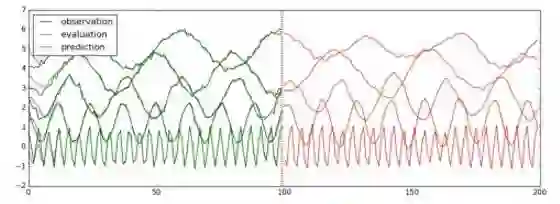
使用LSTM进行多变量时间序列预测(每一条线代表一个变量):
文中涉及的所有代码已经保存在Github上了,地址是:hzy46/TensorFlow-Time-Series-Examples,以下提到的所有代码和文件都是相对于这个项目的根目录来说的。
时间序列问题的一般形式
一般地,时间序列数据可以看做由两部分组成:观察的时间点和观察到的值。以商品价格为例,某年一月的价格为120元,二月的价格为130元,三月的价格为135元,四月的价格为132元。那么观察的时间点可以看做是1,2,3,4,而在各时间点上观察到的数据的值为120,130,135,132。
从Numpy数组中读入时间序列数据
如何将这样的时间序列数据读入进来?TFTS库中提供了两个方便的读取器NumpyReader和CSVReader。前者用于从Numpy数组中读入数据,后者则可以从CSV文件中读取数据。
我们利用np.sin,生成一个实验用的时间序列数据,这个时间序列数据实际上就是在正弦曲线上加上了上升的趋势和一些随机的噪声:
# coding: utf-8
from __future__ import print_function
import numpy as np
import matplotlib
matplotlib.use('agg')
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.contrib.timeseries.python.timeseries import NumpyReader
x = np.array(range(1000))
noise = np.random.uniform(-0.2, 0.2, 1000)
y = np.sin(np.pi * x / 100) + x / 200. + noise
plt.plot(x, y)
plt.savefig('timeseries_y.jpg')
如图:
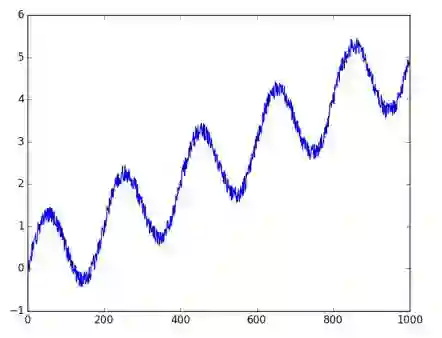
横坐标对应变量“x”,纵坐标对应变量“y”,它们就是我们之前提到过的“观察的时间点”以及“观察到的值”。TFTS读入x和y的方式非常简单,请看下面的代码:
data = {
tf.contrib.timeseries.TrainEvalFeatures.TIMES: x,
tf.contrib.timeseries.TrainEvalFeatures.VALUES: y,
}
reader = NumpyReader(data)
我们首先把x和y变成python中的词典(变量data)。变量data中的键值tf.contrib.timeseries.TrainEvalFeatures.TIMES实际就是一个字符串“times”,而tf.contrib.timeseries.TrainEvalFeatures.VALUES就是字符串”values”。所以上面的定义直接写成“data = {‘times’:x, ‘values’:y}”也是可以的。写成比较复杂的形式是为了和源码中的写法保持一致。
得到的reader有一个read_full()方法,它的返回值就是时间序列对应的Tensor,我们可以用下面的代码试验一下:
with tf.Session() as sess:
full_data = reader.read_full()
# 调用read_full方法会生成读取队列
# 要用tf.train.start_queue_runners启动队列才能正常进行读取
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
print(sess.run(full_data))
coord.request_stop()
不能直接使用sess.run(reader.read_full())来从reader中取出所有数据。原因在于read_full()方法会产生读取队列,而队列的线程此时还没启动,我们需要使用tf.train.start_queue_runners启动队列,才能使用sess.run()来获取值。
我们在训练时,通常不会使用整个数据集进行训练,而是采用batch的形式。从reader出发,建立batch数据的方法也很简单:
train_input_fn = tf.contrib.timeseries.RandomWindowInputFn(
reader, batch_size=2, window_size=10)
tf.contrib.timeseries.RandomWindowInputFn会在reader的所有数据中,随机选取窗口长度为window_size的序列,并包装成batch_size大小的batch数据。换句话说,一个batch内共有batch_size个序列,每个序列的长度为window_size。
以batch_size=2, window_size=10为例,我们可以打出一个batch内的数据:
with tf.Session() as sess:
batch_data = train_input_fn.create_batch()
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
one_batch = sess.run(batch_data[0])
coord.request_stop()
print('one_batch_data:', one_batch)
这部分读入代码的地址在https://github.com/hzy46/TensorFlow-Time-Series-Examples/blob/master/test_input_array.py。
从CSV文件中读入时间序列数据
有的时候,时间序列数据是存在CSV文件中的。我们当然可以将其先读入为Numpy数组,再使用之前的方法处理。更方便的做法是使用tf.contrib.timeseries.CSVReader读入。项目中提供了一个test_input_csv.py代码,示例如何将文件./data/period_trend.csv中的时间序列读入进来。
假设CSV文件的时间序列数据形式为:
1,-0.6656603714
2,-0.1164380359
3,0.7398626488
4,0.7368633029
5,0.2289480898
6,2.257073255
7,3.023457405
8,2.481161007
9,3.773638612
10,5.059257738
11,3.553186083
CSV文件的第一列为时间点,第二列为该时间点上观察到的值。将其读入的方法为:
# coding: utf-8
from __future__ import print_function
import tensorflow as tf
csv_file_name = './data/period_trend.csv'
reader = tf.contrib.timeseries.CSVReader(csv_file_name)
从reader建立batch数据形成train_input_fn的方法和之前完全一样。下面我们就利用这个train_input_fn来训练模型。
使用AR模型预测时间序列
自回归模型(Autoregressive model,可以简称为AR模型)是统计学上处理时间序列模型的基本方法之一。在TFTS中,已经实现了一个自回归模型。使用AR模型训练、验证并进行时间序列预测的示例程序为train_array.py。
先建立一个train_input_fn:
x = np.array(range(1000))
noise = np.random.uniform(-0.2, 0.2, 1000)
y = np.sin(np.pi * x / 100) + x / 200. + noise
plt.plot(x, y)
plt.savefig('timeseries_y.jpg')
data = {
tf.contrib.timeseries.TrainEvalFeatures.TIMES: x,
tf.contrib.timeseries.TrainEvalFeatures.VALUES: y,
}
reader = NumpyReader(data)
train_input_fn = tf.contrib.timeseries.RandomWindowInputFn(
reader, batch_size=16, window_size=40)
针对这个序列,对应的AR模型的定义就是:
ar = tf.contrib.timeseries.ARRegressor(
periodicities=200, input_window_size=30, output_window_size=10,
num_features=1,
loss=tf.contrib.timeseries.ARModel.NORMAL_LIKELIHOOD_LOSS)
这里的几个参数比较重要,分别给出解释。第一个参数periodicities表示序列的规律性周期。我们在定义数据时使用的语句是:“y = np.sin(np.pi * x / 100) + x / 200. + noise”,因此周期为200。input_window_size表示模型每次输入的值,output_window_size表示模型每次输出的值。input_window_size和output_window_size加起来必须等于train_input_fn中总的window_size。在这里,我们总的window_size为40,input_window_size为30,output_window_size为10,也就是说,一个batch内每个序列的长度为40,其中前30个数被当作模型的输入值,后面10个数为这些输入对应的目标输出值。最后一个参数loss指定采取哪一种损失,一共有两种损失可以选择,分别是NORMAL_LIKELIHOOD_LOSS和SQUARED_LOSS。
num_features参数表示在一个时间点上观察到的数的维度。我们这里每一步都是一个单独的值,所以num_features=1。
除了程序中出现的几个参数外,还有一个比较重要的参数是model_dir。它表示模型训练好后保存的地址,如果不指定的话,就会随机分配一个临时地址。
使用变量ar的train方法可以直接进行训练:
ar.train(input_fn=train_input_fn, steps=6000)
TFTS中验证(evaluation)的含义是:使用训练好的模型在原先的训练集上进行计算,由此我们可以观察到模型的拟合效果,对应的程序段是:
evaluation_input_fn = tf.contrib.timeseries.WholeDatasetInputFn(reader)
evaluation = ar.evaluate(input_fn=evaluation_input_fn, steps=1)
如果要理解这里的逻辑,首先要理解之前定义的AR模型:它每次都接收一个长度为30的输入观测序列,并输出长度为10的预测序列。整个训练集是一个长度为1000的序列,前30个数首先被当作“初始观测序列”输入到模型中,由此就可以计算出下面10步的预测值。接着又会取30个数进行预测,这30个数中有10个数就是前一步的预测值,新得到的预测值又会变成下一步的输入,以此类推。
最终我们得到970个预测值(970=1000-30,因为前30个数是没办法进行预测的)。这970个预测值就被记录在evaluation[‘mean’]中。evaluation还有其他几个键值,如evaluation[‘loss’]表示总的损失,evaluation[‘times’]表示evaluation[‘mean’]对应的时间点等等。
evaluation[‘start_tuple’]会被用于之后的预测中,它相当于最后30步的输出值和对应的时间点。以此为起点,我们可以对1000步以后的值进行预测,对应的代码为:
(predictions,) = tuple(ar.predict(
input_fn=tf.contrib.timeseries.predict_continuation_input_fn(
evaluation, steps=250)))
这里的代码在1000步之后又像后预测了250个时间点。对应的值就保存在predictions[‘mean’]中。我们可以把观测到的值、模型拟合的值、预测值用下面的代码画出来:
plt.figure(figsize=(15, 5))
plt.plot(data['times'].reshape(-1), data['values'].reshape(-1), label='origin')
plt.plot(evaluation['times'].reshape(-1), evaluation['mean'].reshape(-1), label='evaluation')
plt.plot(predictions['times'].reshape(-1), predictions['mean'].reshape(-1), label='prediction')
plt.xlabel('time_step')
plt.ylabel('values')
plt.legend(loc=4)
plt.savefig('predict_result.jpg')
画好的图片会被保存为“predict_result.jpg”
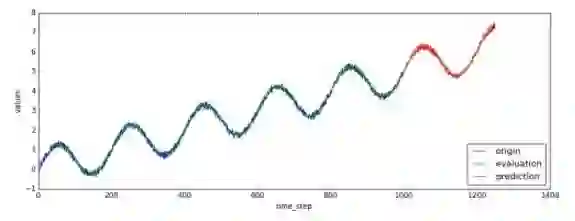
使用LSTM预测单变量时间序列
注意:以下LSTM模型的例子必须使用TensorFlow最新的开发版的源码。具体来说,要保证“from tensorflow.contrib.timeseries.python.timeseries.estimators import TimeSeriesRegressor”可以成功执行。
给出两个用LSTM预测时间序列模型的例子,分别是train_lstm.py和train_lstm_multivariate.py。前者是在LSTM中进行单变量的时间序列预测,后者是使用LSTM进行多变量时间序列预测。为了使用LSTM模型,我们需要先使用TFTS库对其进行定义,定义模型的代码来源于TFTS的示例源码,在train_lstm.py和train_lstm_multivariate.py中分别拷贝了一份。
我们同样用函数加噪声的方法生成一个模拟的时间序列数据:
x = np.array(range(1000))
noise = np.random.uniform(-0.2, 0.2, 1000)
y = np.sin(np.pi * x / 50 ) + np.cos(np.pi * x / 50) + np.sin(np.pi * x / 25) + noise
data = {
tf.contrib.timeseries.TrainEvalFeatures.TIMES: x,
tf.contrib.timeseries.TrainEvalFeatures.VALUES: y,
}
reader = NumpyReader(data)
train_input_fn = tf.contrib.timeseries.RandomWindowInputFn(
reader, batch_size=4, window_size=100)
此处y对x的函数关系比之前复杂,因此更适合用LSTM这样的模型找出其中的规律。得到y和x后,使用NumpyReader读入为Tensor形式,接着用tf.contrib.timeseries.RandomWindowInputFn将其变为batch训练数据。一个batch中有4个随机选取的序列,每个序列的长度为100。
接下来我们定义一个LSTM模型:
estimator = ts_estimators.TimeSeriesRegressor(
model=_LSTMModel(num_features=1, num_units=128),
optimizer=tf.train.AdamOptimizer(0.001))
num_features = 1表示单变量时间序列,即每个时间点上观察到的量只是一个单独的数值。num_units=128表示使用隐层为128大小的LSTM模型。
训练、验证和预测的方法都和之前类似。在训练时,我们在已有的1000步的观察量的基础上向后预测200步:
estimator.train(input_fn=train_input_fn, steps=2000)
evaluation_input_fn = tf.contrib.timeseries.WholeDatasetInputFn(reader)
evaluation = estimator.evaluate(input_fn=evaluation_input_fn, steps=1)
# Predict starting after the evaluation
(predictions,) = tuple(estimator.predict(
input_fn=tf.contrib.timeseries.predict_continuation_input_fn(
evaluation, steps=200)))
将验证、预测的结果取出并画成示意图,画出的图像会保存成“predict_result.jpg”文件:
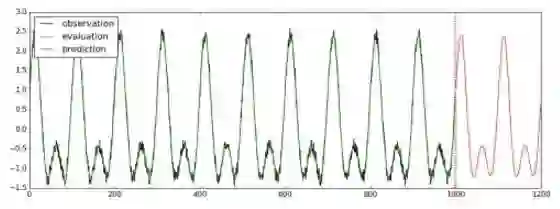
使用LSTM预测多变量时间序列
所谓多变量时间序列,就是指在每个时间点上的观测量有多个值。在data/multivariate_periods.csv文件中,保存了一个多变量时间序列的数据:
0,0.926906299771,1.99107237682,2.56546245685,3.07914768197,4.04839057867
1,0.108010001864,1.41645361423,2.1686839775,2.94963962176,4.1263503303
2,-0.800567600028,1.0172132907,1.96434754116,2.99885333086,4.04300485864
3,0.0607042871898,0.719540073421,1.9765012584,2.89265588817,4.0951014426
4,0.933712200629,0.28052120776,1.41018552514,2.69232603996,4.06481164223
5,-0.171730652974,0.260054421028,1.48770816369,2.62199129293,4.44572807842
6,-1.00180162933,0.333045158863,1.50006392277,2.88888309683,4.24755865606
7,0.0580061875336,0.688929398826,1.56543458772,2.99840358953,4.52726873347
这个CSV文件的第一列是观察时间点,除此之外,每一行还有5个数,表示在这个时间点上的观察到的数据。换句话说,时间序列上每一步都是一个5维的向量。
使用TFTS读入该CSV文件的方法为:
csv_file_name = path.join("./data/multivariate_periods.csv")
reader = tf.contrib.timeseries.CSVReader(
csv_file_name,
column_names=((tf.contrib.timeseries.TrainEvalFeatures.TIMES,)
+ (tf.contrib.timeseries.TrainEvalFeatures.VALUES,) * 5))
train_input_fn = tf.contrib.timeseries.RandomWindowInputFn(
reader, batch_size=4, window_size=32)
与之前的读入相比,唯一的区别就是column_names参数。它告诉TFTS在CSV文件中,哪些列表示时间,哪些列表示观测量。
接下来定义LSTM模型:
estimator = ts_estimators.TimeSeriesRegressor(
model=_LSTMModel(num_features=5, num_units=128),
optimizer=tf.train.AdamOptimizer(0.001))
区别在于使用num_features=5而不是1,原因在于我们在每个时间点上的观测量是一个5维向量。
训练、验证、预测以及画图的代码与之前比较类似,可以参考代码train_lstm_multivariate.py,此处直接给出最后的运行结果:
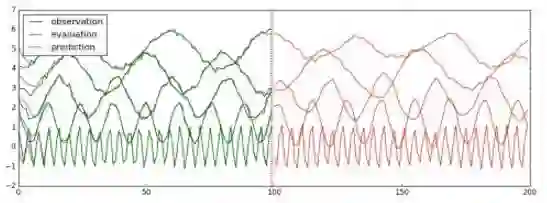
图中前100步是训练数据,一条线就代表观测量在一个维度上的取值。100步之后为预测值。
总结
这篇文章详细介绍了TensorFlow Time Series(TFTS)库的使用方法。主要包含三个部分:数据读入、AR模型的训练、LSTM模型的训练。文章里使用的所有代码都保存在Github上了,地址是:hzy46/TensorFlow-Time-Series-Examples。如果觉得有帮助,欢迎点赞或star~~~
作者:何之源,复旦大学计算机科学硕士在读,研究方向为人工智能以及机器学习的应用。
欢迎人工智能领域技术投稿、约稿、给文章纠错,请发送邮件至heyc@csdn.net

CSDN AI热衷分享 欢迎扫码关注



