如何将 MySQL 去重操作优化到极致?| CSDN 博文精选



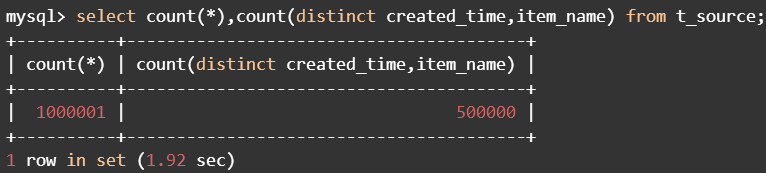
源表中有100万条数据,其中有50万created_time和item_name重复。
要把去重后的50万数据写入到目标表。
重复created_time和item_name的多条数据,可以保留任意一条,不做规则限制。
-- 建立源表
create table t_source
(
item_id
int,
created_time datetime,
modified_time datetime,
item_name varchar(
20),
other varchar(
20)
);
-- 建立目标表
create table t_target like t_source;
-- 生成
100万测试数据,其中有
50万created_time和item_name重复
delimiter
//
create procedure sp_generate_data()
begin
set
@i :=
1;
while
@i<=
500000
do
set
@created_time := date_add(
'2017-01-01',interval
@i second);
set
@modified_time :=
@created_time;
set
@item_name := concat(
'a',
@i);
insert into t_source
values (
@i,
@created_time,
@modified_time,
@item_name,
'other');
set
@i:=
@i+
1;
end
while;
commit;
set
@last_insert_id :=
500000;
insert into t_source
select item_id +
@last_insert_id,
created_time,
date_add(modified_time,interval
@last_insert_id second),
item_name,
'other'
from t_source;
commit;
end
//
delimiter ;
call sp_generate_data();
-- 源表没有主键或唯一性约束,有可能存在两条完全一样的数据,所以再插入一条记录模拟这种情况。
insert into t_source select * from t_source where item_id=
1;

truncate t_target;
insert
into t_target
select
distinct t1.*
from t_source t1
where item_id
in
(
select
min(item_id)
from t_source t2
where t1.created_time=t2.created_time
and t1.item_name=t2.item_name);
mysql> explain select distinct t1.* from t_source t1 where item_id
in
-> (select min(item_id) from t_source t2 where t1.created_time=t2.created_time
and t1.item_name=t2.item_name);
+----+--------------------+-------+------------+------+---------------+------+---------+------+--------+----------+------------------------------+
| id | select_type
| table | partitions
| type | possible_keys
| key | key_len
| ref | rows
| filtered | Extra
|
+----+--------------------+-------+------------+------+---------------+------+---------+------+--------+----------+------------------------------+
|
1
| PRIMARY | t1
| NULL | ALL
| NULL | NULL
| NULL | NULL
| 997282 |
100.00
| Using where; Using temporary |
| 2 | DEPENDENT SUBQUERY
| t2 | NULL
| ALL | NULL
| NULL | NULL
| NULL |
997282
| 1.00 | Using where
|
+----+--------------------+-------+------------+------+---------------+------+---------+------+--------+----------+------------------------------+
2 rows in set, 3 warnings (0.00 sec)
truncate t_target;
insert
into t_target
select
distinct t1.*
from t_source t1,
(
select
min(item_id) item_id,created_time,item_name
from t_source
group
by created_time,item_name) t2
where t1.item_id = t2.item_id;
mysql> explain select distinct t1.* from t_source t1, (select min(item_id) item_id,created_time,item_name from t_source group by created_time,item_name) t2 where t1.item_id = t2.item_id;
+----+-------------+------------+------------+------+---------------+-------------+---------+-----------------+--------+----------+------------------------------+
| id | select_type
| table | partitions
| type | possible_keys
| key | key_len
| ref | rows
| filtered | Extra
|
+----+-------------+------------+------------+------+---------------+-------------+---------+-----------------+--------+----------+------------------------------+
|
1
| PRIMARY | t1
| NULL | ALL
| NULL | NULL
| NULL | NULL
| 997282 |
100.00
| Using where; Using temporary |
| 1 | PRIMARY
| <derived2> | NULL
| ref | <auto_key
0>
| <auto_key0> |
5
| test.t1.item_id |
10
| 100.00 | Distinct
|
|
2
| DERIVED | t_source
| NULL | ALL
| NULL | NULL
| NULL | NULL
| 997282 |
100.00
| Using temporary |
+----+-------------+------------+------------+------+---------------+-------------+---------+-----------------+--------+----------+------------------------------+
3 rows
in set,
1 warning (
0.
00 sec)
内层查询扫描t_source表的100万行,建立临时表,找出去重后的最小item_id,生成导出表derived2,此导出表有50万行。
MySQL会在导出表derived2上自动创建一个item_id字段的索引auto_key0。
外层查询也要扫描t_source表的100万行数据,在与导出表做链接时,对t_source表每行的item_id,使用auto_key0索引查找导出表中匹配的行,并在此时优化distinct操作,在找到第一个匹配的行后即停止查找同样值的动作。
set @a:=
'1000-01-01 00:00:00';
set @b:=
' ';
set @f:=
0;
truncate t_target;
insert
into t_target
select item_id,created_time,modified_time,item_name,other
from
(
select t0.*,
if(@a=created_time
and @b=item_name,@f:=
0,@f:=
1) f, @a:=created_time,@b:=item_name
from
(
select *
from t_source
order
by created_time,item_name) t0) t1
where f=
1;
mysql> explain select item_id,created_time,modified_time,item_name,other
-> from
-> (select t
0.*,
if(@a=created_time
and @b=item_name,@f
:=
0,@f
:=
1) f, @a
:=created_time,@b
:=item_name
-> from
-> (select * from t_source order by created_time,item_name) t
0) t1 where f=
1;
+----+-------------+------------+------------+------+---------------+-------------+---------+-------+--------+----------+----------------+
| id | select_type
| table | partitions
| type | possible_keys
| key | key_len
| ref | rows
| filtered | Extra
|
+----+-------------+------------+------------+------+---------------+-------------+---------+-------+--------+----------+----------------+
|
1
| PRIMARY | <derived2>
| NULL | ref
| <auto_key0> | <auto_key
0>
| 4 | const
| 10 |
100.00
| NULL |
| 2 | DERIVED
| <derived3> | NULL
| ALL | NULL
| NULL | NULL
| NULL |
997282
| 100.00 | NULL
|
|
3
| DERIVED | t_source
| NULL | ALL
| NULL | NULL
| NULL | NULL
| 997282 |
100.00
| Using filesort |
+----+-------------+------------+------------+------+---------------+-------------+---------+-------+--------+----------+----------------+
3 rows
in set,
5 warnings (
0.
00 sec)
最内层的查询扫描t_source表的100万行,并使用文件排序,生成导出表derived3。
第二层查询要扫描derived3的100万行,生成导出表derived2,完成变量的比较和赋值,并自动创建一个导出列f上的索引auto_key0。
最外层使用auto_key0索引扫描derived2得到去重的结果行。

truncate t_target;
insert
into t_target
select
distinct t1.*
from t_source t1
where item_id
in
(
select
min(item_id)
from t_source t2
where t1.created_time=t2.created_time
and t1.item_name=t2.item_name);
mysql> explain select distinct t1.* from t_source t1 where item_id
in
-> (select min(item_id) from t_source t2 where t1.created_time=t2.created_time
and t1.item_name=t2.item_name);
+----+--------------------+-------+------------+------+---------------+----------+---------+----------------------------------------+--------+----------+------------------------------+
| id | select_type
| table | partitions
| type | possible_keys
| key | key_len
| ref | rows
| filtered | Extra
|
+----+--------------------+-------+------------+------+---------------+----------+---------+----------------------------------------+--------+----------+------------------------------+
|
1
| PRIMARY | t1
| NULL | ALL
| NULL | NULL
| NULL | NULL
| 997281 |
100.00
| Using where; Using temporary |
| 2 | DEPENDENT SUBQUERY
| t2 | NULL
| ref | idx_sort
| idx_sort |
89
| test.t1.created_time,test.t1.item_name |
2
| 100.00 | Using index
|
+----+--------------------+-------+------------+------+---------------+----------+---------+----------------------------------------+--------+----------+------------------------------+
2 rows in set, 3 warnings (0.00 sec)
外层查询的t_source表是驱动表,需要扫描100万行。
对于驱动表每行的item_id,通过idx_sort索引查询出两行数据。
truncate t_target;
insert
into t_target
select
distinct t1.*
from t_source t1,
(
select
min(item_id) item_id,created_time,item_name
from t_source
group
by created_time,item_name) t2
where t1.item_id = t2.item_id;
mysql> explain select distinct t1.* from t_source t1,
-> (select min(item_id) item_id,created_time,item_name from t_source group by created_time,item_name) t2
-> where t1.item_id = t2.item_id;
+----+-------------+------------+------------+-------+---------------+-------------+---------+-----------------+--------+----------+------------------------------+
| id | select_type
| table | partitions
| type | possible_keys
| key | key_len
| ref | rows
| filtered | Extra
|
+----+-------------+------------+------------+-------+---------------+-------------+---------+-----------------+--------+----------+------------------------------+
|
1
| PRIMARY | t1
| NULL | ALL
| NULL | NULL
| NULL | NULL
| 997281 |
100.00
| Using where; Using temporary |
| 1 | PRIMARY
| <derived2> | NULL
| ref | <auto_key
0>
| <auto_key0> |
5
| test.t1.item_id |
10
| 100.00 | Distinct
|
|
2
| DERIVED | t_source
| NULL | index
| idx_sort | idx_sort
| 94 | NULL
| 997281 |
100.00
| Using index |
+----+-------------+------------+------------+-------+---------------+-------------+---------+-----------------+--------+----------+------------------------------+
3 rows
in set,
1 warning (
0.
00 sec)
set @a:=
'1000-01-01 00:00:00';
set @b:=
' ';
set @f:=
0;
truncate t_target;
insert
into t_target
select item_id,created_time,modified_time,item_name,other
from
(
select t0.*,
if(@a=created_time
and @b=item_name,@f:=
0,@f:=
1) f, @a:=created_time,@b:=item_name
from
(
select *
from t_source
order
by created_time,item_name) t0) t1
where f=
1;
set @a:=
'1000-01-01 00:00:00';
set @b:=
' ';
truncate t_target;
insert
into t_target
select *
from t_source
force
index (idx_sort)
where (@a!=created_time
or @b!=item_name)
and (@a:=created_time)
is
not
null
and (@b:=item_name)
is
not
null
order
by created_time,item_name;
本次用时12秒,查询计划如下:
mysql> explain select * from t_source force index (idx_sort)
-> where (@a!=created_time
or @b!=item_name)
and (@a
:=created_time) is
not null
and (@b
:=item_name) is
not null
-> order by created_time,item_name;
+----+-------------+----------+------------+-------+---------------+----------+---------+------+--------+----------+-------------+
| id | select_type
| table | partitions
| type | possible_keys
| key | key_len
| ref | rows
| filtered | Extra
|
+----+-------------+----------+------------+-------+---------------+----------+---------+------+--------+----------+-------------+
|
1
| SIMPLE | t_source
| NULL | index
| NULL | idx_sort
| 94 | NULL
| 997281 |
99.00
| Using where |
+----+-------------+----------+------------+-------+---------------+----------+---------+------+--------+----------+-------------+
1 row
in set,
3 warnings (
0.
00 sec)
消除了嵌套子查询,只需要对t_source表进行一次全索引扫描,查询计划已达最优。
无需distinct二次查重。
变量判断与赋值只出现在where子句中。
利用索引消除了filesort。
执行笛卡尔乘积(交叉连接)
应用ON筛选器(连接条件)
添加外部行(outer join)
应用where筛选器
分组
应用cube或rollup
应用having筛选器
处理select列表
应用distinct子句
应用order by子句
应用limit子句

truncate t_target;
insert
into t_target
select item_id, created_time, modified_time, item_name, other
from (
select *, row_number()
over(
partition
by created_time,item_name)
as rn
from t_source) t
where rn=
1;
mysql> explain select item_id, created_time, modified_time, item_name, other
-> from (select *, row_number() over(partition by created_time,item_name) as rn
-> from t_source) t where rn=
1;
+----+-------------+------------+------------+------+---------------+-------------+---------+-------+--------+----------+----------------+
| id | select_type
| table | partitions
| type | possible_keys
| key | key_len
| ref | rows
| filtered | Extra
|
+----+-------------+------------+------------+------+---------------+-------------+---------+-------+--------+----------+----------------+
|
1
| PRIMARY | <derived2>
| NULL | ref
| <auto_key0> | <auto_key
0>
| 8 | const
| 10 |
100.00
| NULL |
| 2 | DERIVED
| t_source | NULL
| ALL | NULL
| NULL | NULL
| NULL |
997281
| 100.00 | Using filesort
|
+----+-------------+------------+------------+------+---------------+-------------+---------+-------+--------+----------+----------------+
2 rows in set, 2 warnings (0.00 sec)

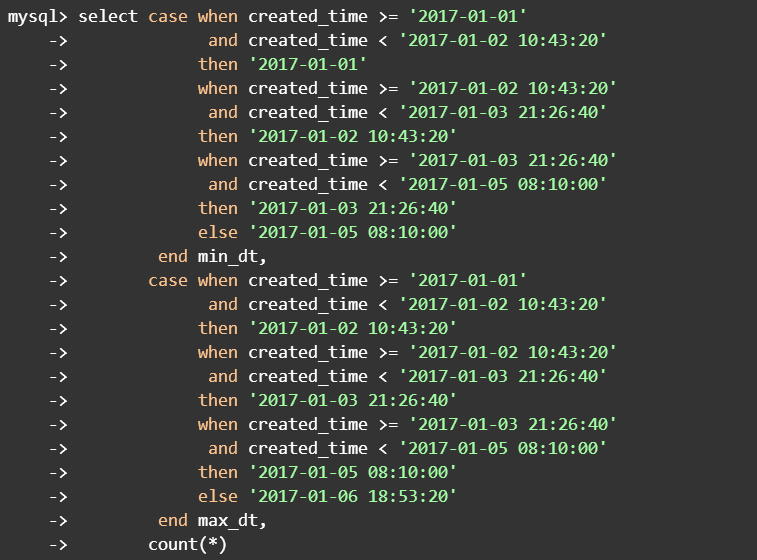
mysql> select date_add(
'2017-01-01',interval
125000 second) dt1,
-> date_add(
'2017-01-01',interval
2*
125000 second) dt2,
-> date_add(
'2017-01-01',interval
3*
125000 second) dt3,
-> max(created_time) dt4
-> from t_source;
+---------------------+---------------------+---------------------+---------------------+
| dt1 | dt2
| dt3 | dt4
|
+---------------------+---------------------+---------------------+---------------------+
|
2017-
01-
02
10:43:20
| 2017-01-03 21:26:40 |
2017-
01-
05 08
:10:00
| 2017-01-06 18:53:20 |
+---------------------+---------------------+---------------------+---------------------+
1 row
in set (
0.
00 sec)
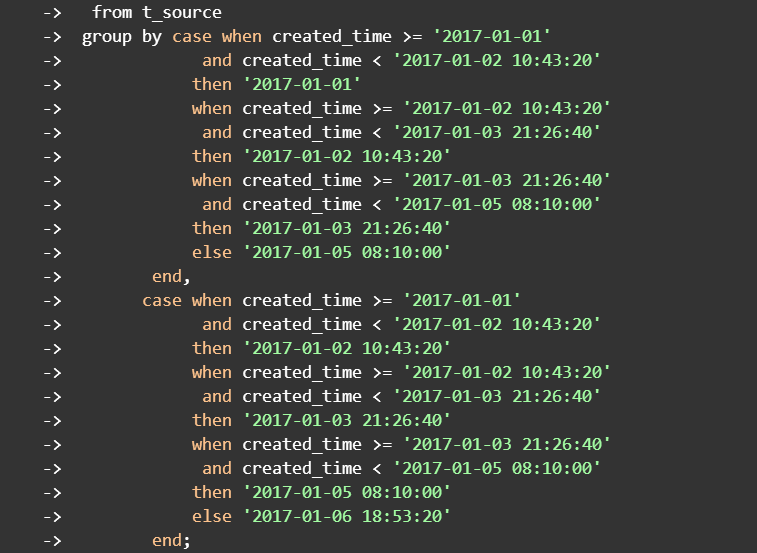
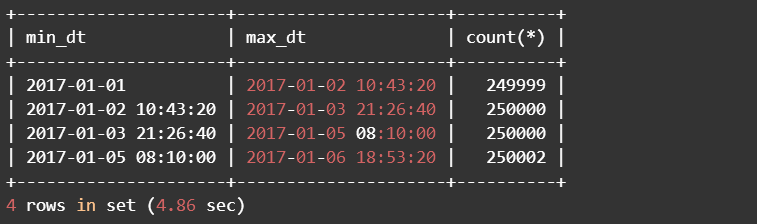
delimiter
//
create
procedure sp_unique(i smallint)
begin
set @a:=
'1000-01-01 00:00:00';
set @b:=
' ';
if (i<
4)
then
insert into t_target
select * from t_source force
index (idx_sort)
where created_time >= date_add(
'2017-01-01',interval (i-
1)*
125000 second)
and created_time < date_add(
'2017-01-01',interval i*
125000 second)
and (@a!=created_time
or @b!=item_name)
and (@a:=created_time)
is
not null
and (@b:=item_name)
is
not null
order by created_time,item_name;
else
insert into t_target
select * from t_source force
index (idx_sort)
where created_time >= date_add(
'2017-01-01',interval (i-
1)*
125000 second)
and created_time <= date_add(
'2017-01-01',interval i*
125000 second)
and (@a!=created_time
or @b!=item_name)
and (@a:=created_time)
is
not null
and (@b:=item_name)
is
not null
order by created_time,item_name;
end
if;
end
//
mysql> explain select * from t_source force index (idx_sort)
-> where created_time >= date_add(
'2017-01-01',interval (
1-
1)*
125000 second)
->
and created_time < date_add(
'2017-01-01',interval
1*
125000 second)
->
and (@a!=created_time
or @b!=item_name)
->
and (@a
:=created_time) is
not null
->
and (@b
:=item_name) is
not null
-> order by created_time,item_name;
+----+-------------+----------+------------+-------+---------------+----------+---------+------+--------+----------+-----------------------+
| id | select_type
| table | partitions
| type | possible_keys
| key | key_len
| ref | rows
| filtered | Extra
|
+----+-------------+----------+------------+-------+---------------+----------+---------+------+--------+----------+-----------------------+
|
1
| SIMPLE | t_source
| NULL | range
| idx_sort | idx_sort
| 6 | NULL
| 498640 |
100.00
| Using index condition |
+----+-------------+----------+------------+-------+---------------+----------+---------+------+--------+----------+-----------------------+
1 row
in set,
3 warnings (
0.
00 sec)

./duplicate_removal.sh
[mysql@hdp2~]$./duplicate_removal.sh
14:27:30
14:27:35
[mysql@hdp2~]$cat par_sql1_1.log | sed '/^$/d'
mysql: [Warning] Using a password on the command line interface can be insecure.
--------------
call sp_unique(
1)
--------------
Query OK,
124999
rows affected (
4.87 sec)
Bye
[mysql@hdp2~]$cat par_sql1_2.log | sed
'/^$/d'
mysql: [
Warning]
Using a
password
on the command line
interface can be insecure.
--------------
call sp_unique(
2)
--------------
Query OK,
125000
rows affected (
4.88 sec)
Bye
[mysql@hdp2~]$cat par_sql1_3.log | sed
'/^$/d'
mysql: [
Warning]
Using a
password
on the command line
interface can be insecure.
--------------
call sp_unique(
3)
--------------
Query OK,
125000
rows affected (
4.91 sec)
Bye
[mysql@hdp2~]$cat par_sql1_4.log | sed
'/^$/d'
mysql: [
Warning]
Using a
password
on the command line
interface can be insecure.
--------------
call sp_unique(
4)
--------------
Query OK,
125001
rows affected (
4.73 sec)
Bye
[mysql@hdp2~]$
建立事件历史日志表
-- 用于查看事件执行时间等信息
create
table t_event_history (
dbname
varchar(
128)
not
null
default
'',
eventname
varchar(
128)
not
null
default
'',
starttime datetime(
3)
not
null
default
'1000-01-01 00:00:00',
endtime datetime(
3)
default
null,
issuccess
int(
11)
default
null,
duration
int(
11)
default
null,
errormessage
varchar(
512)
default
null,
randno
int(
11)
default
null
);
为每个并发线程创建一个事件
delimiter //
create
event ev1
on schedule
at
current_timestamp +
interval
1
hour
on completion
preserve
disable
do
begin
declare r_code
char(
5)
default
'00000';
declare r_msg
text;
declare v_error
integer;
declare v_starttime datetime
default
now(
3);
declare v_randno
integer
default
floor(
rand()*
100001);
insert
into t_event_history (dbname,eventname,starttime,randno)
#作业名
values(
database(),
'ev1', v_starttime,v_randno);
begin
#异常处理段
declare continue
handler
for sqlexception
begin
set v_error =
1;
get diagnostics condition 1 r_code = returned_sqlstate , r_msg = message_text;
end;
#此处为实际调用的用户程序过程
call sp_unique(
1);
end;
update t_event_history
set endtime=
now(
3),issuccess=
isnull(v_error),
duration=
timestampdiff(
microsecond,starttime,
now(
3)), errormessage=
concat(
'error=',r_code,
', message=',r_msg),randno=
null
where starttime=v_starttime
and randno=v_randno;
end
//
create
event ev2
on schedule
at
current_timestamp +
interval
1
hour
on completion
preserve
disable
do
begin
declare r_code
char(
5)
default
'00000';
declare r_msg
text;
declare v_error
integer;
declare v_starttime datetime
default
now(
3);
declare v_randno
integer
default
floor(
rand()*
100001);
insert
into t_event_history (dbname,eventname,starttime,randno)
#作业名
values(
database(),
'ev2', v_starttime,v_randno);
begin
#异常处理段
declare continue
handler
for sqlexception
begin
set v_error =
1;
get diagnostics condition 1 r_code = returned_sqlstate , r_msg = message_text;
end;
#此处为实际调用的用户程序过程
call sp_unique(
2);
end;
update t_event_history
set endtime=
now(
3),issuccess=
isnull(v_error),
duration=
timestampdiff(
microsecond,starttime,
now(
3)), errormessage=
concat(
'error=',r_code,
', message=',r_msg),randno=
null
where starttime=v_starttime
and randno=v_randno;
end
//
create
event ev3
on schedule
at
current_timestamp +
interval
1
hour
on completion
preserve
disable
do
begin
declare r_code
char(
5)
default
'00000';
declare r_msg
text;
declare v_error
integer;
declare v_starttime datetime
default
now(
3);
declare v_randno
integer
default
floor(
rand()*
100001);
insert
into t_event_history (dbname,eventname,starttime,randno)
#作业名
values(
database(),
'ev3', v_starttime,v_randno);
begin
#异常处理段
declare continue
handler
for sqlexception
begin
set v_error =
1;
get diagnostics condition 1 r_code = returned_sqlstate , r_msg = message_text;
end;
#此处为实际调用的用户程序过程
call sp_unique(
3);
end;
update t_event_history
set endtime=
now(
3),issuccess=
isnull(v_error),
duration=
timestampdiff(
microsecond,starttime,
now(
3)), errormessage=
concat(
'error=',r_code,
', message=',r_msg),randno=
null
where starttime=v_starttime
and randno=v_randno;
end
//
create
event ev4
on schedule
at
current_timestamp +
interval
1
hour
on completion
preserve
disable
do
begin
declare r_code
char(
5)
default
'00000';
declare r_msg
text;
declare v_error
integer;
declare v_starttime datetime
default
now(
3);
declare v_randno
integer
default
floor(
rand()*
100001);
insert
into t_event_history (dbname,eventname,starttime,randno)
#作业名
values(
database(),
'ev4', v_starttime,v_randno);
begin
#异常处理段
declare continue
handler
for sqlexception
begin
set v_error =
1;
get diagnostics condition 1 r_code = returned_sqlstate , r_msg = message_text;
end;
#此处为实际调用的用户程序过程
call sp_unique(
4);
end;
update t_event_history
set endtime=
now(
3),issuccess=
isnull(v_error),
duration=
timestampdiff(
microsecond,starttime,
now(
3)), errormessage=
concat(
'error=',r_code,
', message=',r_msg),randno=
null
where starttime=v_starttime
and randno=v_randno;
end
//
触发事件执行
mysql -vvv -u root -p123456 test -e "
truncate t_target;
alter
event ev1
on schedule
at
current_timestamp
enable;
alter
event ev2
on schedule
at
current_timestamp
enable;
alter
event ev3
on schedule
at
current_timestamp
enable;
alter
event ev4
on schedule
at
current_timestamp
enable;"
[mysql@hdp2~]$mysql -vvv -u root -p123456 test -e "
truncate t_target;
alter
event ev1
on schedule
at
current_timestamp
enable;
alter
event ev2
on schedule
at
current_timestamp
enable;
alter
event ev3
on schedule
at
current_timestamp
enable;
alter
event ev4
on schedule
at
current_timestamp
enable;"
mysql: [Warning] Using a password on the command line interface can be insecure.
--------------
truncate t_target
--------------
Query OK,
0
rows affected (
0.06 sec)
--------------
alter
event ev1
on schedule
at
current_timestamp
enable
--------------
Query OK,
0
rows affected (
0.02 sec)
--------------
alter
event ev2
on schedule
at
current_timestamp
enable
--------------
Query OK,
0
rows affected (
0.00 sec)
--------------
alter
event ev3
on schedule
at
current_timestamp
enable
--------------
Query OK,
0
rows affected (
0.02 sec)
--------------
alter
event ev4
on schedule
at
current_timestamp
enable
--------------
Query OK,
0
rows affected (
0.00 sec)
Bye
[mysql@hdp2~]$
查看事件执行日志
mysql> select * from test.t_event_history;
+--------+-----------+-------------------------+-------------------------+-----------+----------+--------------+--------+
| dbname | eventname
| starttime | endtime
| issuccess | duration
| errormessage | randno
|
+--------+-----------+-------------------------+-------------------------+-----------+----------+--------------+--------+
| test
| ev1 |
2019-
07-
31
14:38:04.
000
| 2019-07-31 14:38:09.389 |
1
| 5389000 | NULL
| NULL |
| test | ev2
| 2019-07-31 14:38:04.000 |
2019-
07-
31
14:38:09.
344
| 1 |
5344000
| NULL | NULL
|
| test
| ev3 |
2019-
07-
31
14:38:05.
000
| 2019-07-31 14:38:09.230 |
1
| 4230000 | NULL
| NULL |
| test | ev4
| 2019-07-31 14:38:05.000 |
2019-
07-
31
14:38:09.
344
| 1 |
4344000
| NULL | NULL
|
+--------+-----------+-------------------------+-------------------------+-----------+----------+--------------+--------+
4 rows in set (0.00 sec)
【END】

☞吊打 IE、Firefox,谷歌 Chrome 十年封神记
点击阅读原文,输入关键词,即可搜索您想要的 CSDN 文章。





