AIDL专栏|基于HTM/RDMA的可扩展内存事务处理系统
AIDL简介
“人工智能前沿讲习班”(AIDL)由中国人工智能学会主办,旨在短时间内集中学习某一领域的基础理论、最新进展和落地方向,并促进产、学、研相关从业人员的相互交流,对于硕士、博士、青年教师、企事业单位相关从业者、预期转行AI领域的爱好者均具有重要的意义。2018年AIDL活动正在筹备,敬请关注获取最新消息。
导读
在第三届“人工智能前沿讲习班”上,上海交通大学的陈海波教授做了题为《基于HTM/RDMA的可扩展内存事务处理系统》的报告,报告介绍了如何利用诸如HTM和RDMA之类的新型硬件特性来提供更好的单节点和分布式内存交易,如何改进操作系统和处理器架构以进一步简化和改进内存中事务处理,以及如何根据需要调整并发控制协议。本文根据陈海波教授当日报告内容整理发布,对于相关领域的研究工作具有长期价值。
关注本公众号,回复“陈海波”,获取完整版PPT。
分享PPT仅供学习交流,请勿外传
讲师简介
陈海波,上海交通大学教授、博士生导师,CCF杰出会员、杰出演讲者,ACM/IEEE高级会员。主要研究方向为系统软件与系统结构。入选2014年国家“万人计划”青年拔尖人才计划,获得2011年全国优秀博士学位论文奖、2015年CCF青年科学家奖。目前担任ACM SOSP 2017年大会主席、ACM APSys指导委员会主席、《软件学报》责任编辑、《ACM Transactions onStorage》编委等。多次担任SOSP、ISCA、Oakland、PPoPP、EuroSys、Usenix ATC、FAST等国际著名学术会议程序委员会委员。在SOSP、OSDI、EuroSys、Usenix ATC、ISCA、MICRO、HPCA、FAST、PPoPP、CCS、Usenix Security等著名学术会议与IEEE TC、TSE与TPDS等著名学术期刊等共发表60余篇学术论文,获得ACM EuroSys 2015、ACMAPSys 2013与IEEE ICPP 2007的最佳论文奖与IEEE HPCA 2014的最佳论文提名奖。研究工作也获得GoogleFaculty Research Award、IBM X10 Innovation Award、NetAPP Faculty Fellowship与华为创新价值成果奖等企业奖励。

1. 事务处理系统发展简介
2006年,Jim Gray预测磁带会消亡,备份存储将主要使用磁盘,固态硬盘会替代磁盘,提高内存访问局部性是关键。

图1 Jim Gray预测
2017年英特尔美光发布了新型非易失性内存器件3D XPoint,时延接近DRAM。3D XPoint等能够随机读写的内存价格相对便宜,容量大,访问速度快,未来可能在存储层替代SSD。对数据的访问速度将比原来提高数十甚至成百上千倍,导致缓存局部性成为系统性能的关键。
另外一方面,并行性也很关键。现在的电子商务,例如亚马逊和淘宝购物、12306购票、支付宝和PayPal交易等,都涉及很多事务处理工作。2013年图灵奖获得者Michael Stonebraker分析指出:传统的数据库事务处理系统只有4%的时间做有用的数据处理,很多时间用于系统本身框架上的工作(缓存数据、加锁、做分布式锁、做恢复等),硬件带来的性能提升被数据库系统本身浪费了。
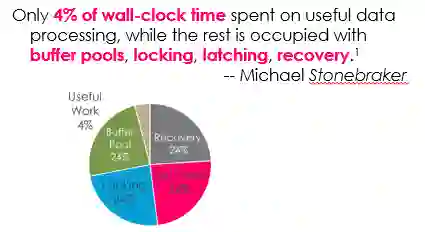
图2 传统数据库事务处理系统的工作时间分配
内存计算时代有两方面的主要挑战。第一,高吞吐量。每个人都会用提交事务的终端发送请求,比如用手机发订单,这样的请求会越来越多,要求系统设计能够考虑高吞吐,比如每秒处理百万量级的事务;第二,低时延,信息社会中时间就是金钱,数据分析时间对于决策非常关键。
图3 内存计算的挑战
TPC-C是事务处理业界最标准的测试集,每年都有企业发布TPC-C的世界纪录。Oracle发布的记录是504161事务/秒,靠非常大的机器集群(价格3000万美元)。排名第二的是IBM的机器,172770事务/秒(价格1400多万美元)。传统大型机或者高端集群系统是非常昂贵的。
阿里巴巴或其他互联网公司,更多采用MySQL Cluster,用大量集群替代昂贵的机器,成本降低10到20倍,效果也较好。每年“双11”购物体验比较流畅,但购物高峰时段可以感受到时延。
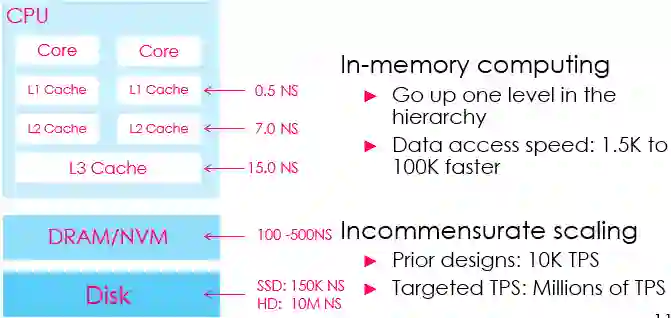
图4 计算机存储数据的访问速度。内存计算使数据的访问速度显著提升。
内存计算时代遇到的问题可总结为”incommensurate scaling” (不成比例的拓展)。
问题1:原来的系统设计主要围绕磁盘任务,目标可能是每秒1万个事务,但如果数据访问速度提升1万倍,事务处理吞吐量能否相应提升上百或上千倍?简单将数据放到内存中是无法做到的,需要对基础框架进行革新。
图5 Linux网络处理流程
问题2:时延。以太网传输很快,但经过这一系列处理,时延可能放大几十倍甚至上百倍。
问题3:存储。之前提到非易失内存,能够提供接近DRAM的时延,并且每一个byte都可以访问,这就改变了非易失的界限,需要对文件系统进行重构。
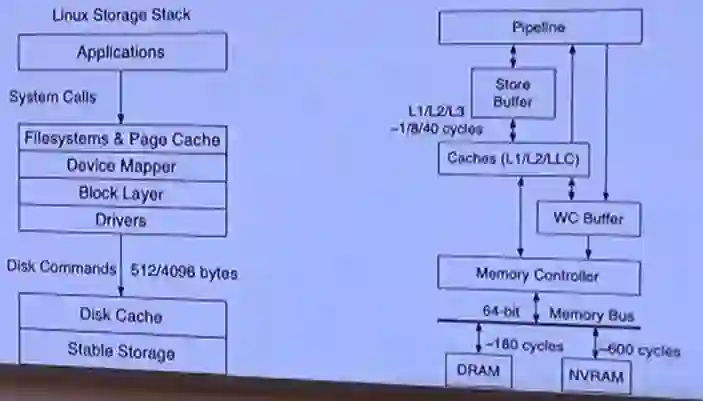
图6 左侧是传统的存储栈结构,右侧是采用NVRAM(非易失性RAM)的结构
将NVRAM绑定到内存总线上,可以通过内存控制器直接访问DRAM,传统结构中的Page Cache、Device Mapper和Block Layer都可以去掉。如果还要提供文件系统(Filesystem),则需要对传统文件系统进行显著的改造,避免因为一系列的层次浪费时间。

图7 长尾效应
问题4:大型数据中心还需要考虑 “长尾效应”。Google的JeffreyDean在CACM2013上发表的一篇文章中提到如果100台机器里有1台机器时延超过1s,其余99台时延都是1ms,整个集群系统的时延也有63%的概率超过1s。所以做系统优化不仅要考虑快速路径的速度,也要考虑最坏时的系统性能。
我们的工作主要是充分利用已有硬件特性,采用非常快速的网络设备(比如具有RDMA的InfiniBand),结合NVM和事务内存,在很小的集群中构造快速的事务处理系统,可以做到每秒百万量级事务。

图 8 硬件设备
2. HTM and RDMA
2.1 HTM
HTM(Hardware Transactional Memory)最早在1993年的ISCA会议上由Herlihy和Moss提出,但直到2013年Intel Haswell才将HTM正式发布。

图 9 HTM发展时间线
Intel发布的是RTM(Restricted Transactional Memory),即受限的HTM,主要限制包括limited working set以及system events aborttransaction。
事务内存最早来源于数据库事务,数据库事务比较重要的特性是ACID,即Atomicity、Consistency、Isolation和Durability。通过把一系列操作定义成事务,容易知道操作的语义。
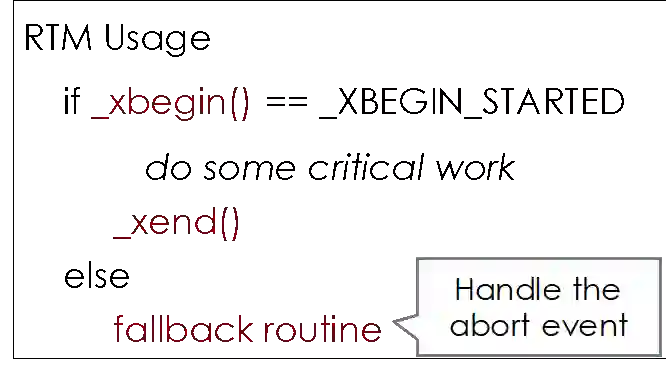
图10 RTM指令
在RTM中进行操作,可以用xbegin,像数据库事务一样开始一个事务,在里面做一些工作,再结束事务。如果事务无法使用RTM执行,还提供fallback routine进行处理。RTM提供xbegin、xend、xabort等指令,传统的move、add等指令也可以在代码中直接使用。
RTM的事务类型有三个方面特性:
第一,RTM偏好于读操作而不是写操作。它可以将大概4M的数据放到事务里,但只能将64K的数据放到写的working set内,所以对“读多写少”的操作比较友好。
第二,RTM偏好于“先读后写”,适用于需要先读大量数据再写数据的操作,比如修改查找树或B树的节点。
第三,如果事务执行时间比较长,timer interrupt会无条件中止该事务。
2.2 RDMA
RDMA(Remote Direct Memory Access)是一种网络特性,可以支持直接访问远端机器的内存。因为RDMA专门的协议绕过了操作系统内核,所以访问速度非常快,并且RDMA单边操作(one-sided)可以不经过CPU将数据拖回,时延和处理器开销都很低。RDMA单边操作支持READ、WRITE、CAS(compare-and-swap)等操作。
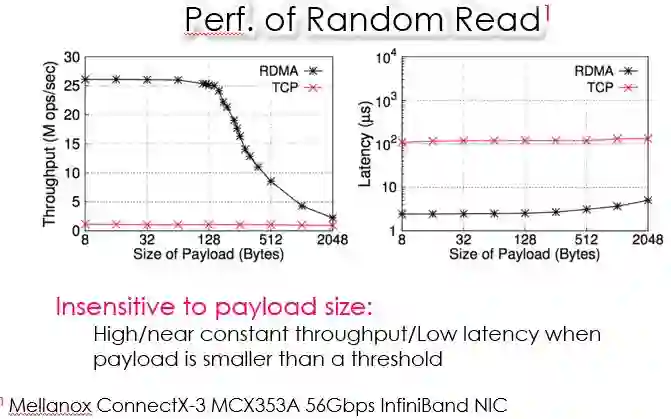
图 11 RDMA和TCP/IP性能对比
如图,横坐标表示每个RDMA请求夹杂多少用户数据,纵坐标分别是吞吐量和时延。吞吐量方面,传统的TCP/IP一直非常低,而RDMA在payload size小于某个阈值时吞吐量比较高且变化不大,高于某个阈值时吞吐量明显下降;时延方面,RDMA对payload size变化不敏感。
3. Combining Advanced Hardware Features for In-memoryTransactions
3.1 Opportunitieswith HTM & RDMA
HTM具有Strong Atomicity特性,非事务性代码如果和事务产生访问冲突,可以无条件中止该事务;RDMA具有Strong Consistency特性,单边RDMA操作和本地访问是缓存一致的(cache-coherent)。结合这两点,如果RDMA请求访问远端机器,远端机器正在处于事务执行,就会将远端事务中止。基于该方式可实现分布式事务内存,进一步实现分布式事务处理系统。

图 12特性结合
3.2 Overall Idea
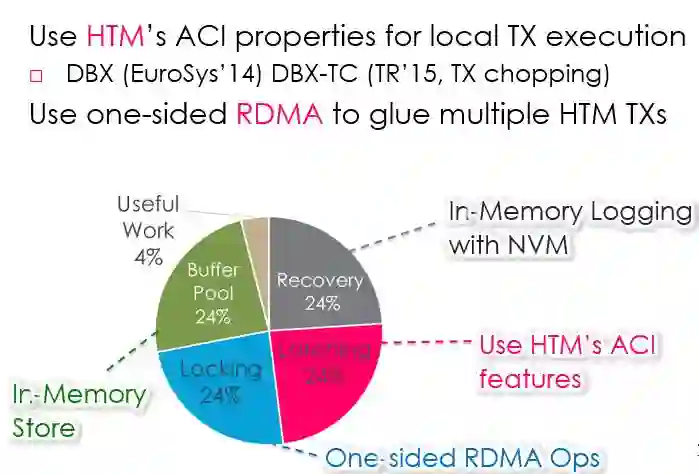
图 13如何减少系统框架开销
用HTM的ACI特性支持单机硬件事务,并通过软件方式扩展Durability(持久化)的支持。复用HTM实现并发控制,提升事务处理效率。单机实现后,用one-sided RDMA将多台机器上基于HTM的事务联系起来,组成分布式事务处理系统。
减少系统框架开销的方法:采用In-Memory Computing后去掉BufferPool; HTM的ACI特性替换Latching;Locking用单边RDMA操作实现;对于Recovery,用NVRAM实现日志的持久化,极大降低恢复需要。
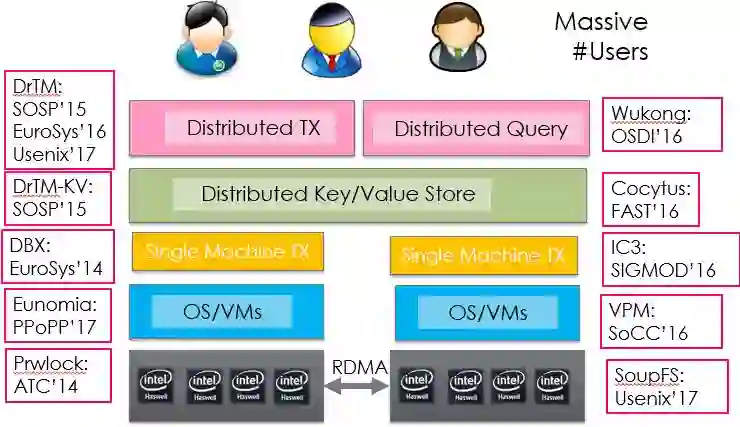
图 14 Recent Work on In-memory TXs
4. Building Fast In-memory Transactions using RDMA andHTM
4.1 DrTM: Distributed TX with HTM & RDMA
l系统框架
基于RDMA和HTM构建快速内存事务。针对OLTP workloads,比如支付或生成新订单、发报价等事务,构建DrTM系统。通过层次化方法,一方面实现transaction layer,做并发控制等工作;另一方面实现基于键值存储的系统DrTM-KV,支持快速查询。基于这两个层次实现了可扩展且高性能的分布式事务,6台机器搭建的网络可以达到500万事务/秒的性能,相对之前有几十倍的提升。
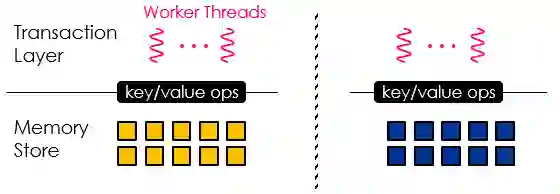
图 15 DrTM系统框架
DrTM系统将HTM和传统的2PL(two-phase locking)结合。传统分布式事务处理将事务发送到数据存在的位置,通过two-phase commit方式提交事务。DrTM不是把事务发出去,而是把数据拖回来,因为RDMA访问速度很快。通过把分布式事务变成本地事务,避免two-phase commit的开销。
并发控制方面,本地事务之间可以复用HTM,分布式事务之间可以用基于RDMA的2PL,本地事务和分布式事务之间直接中止本地事务就可以。
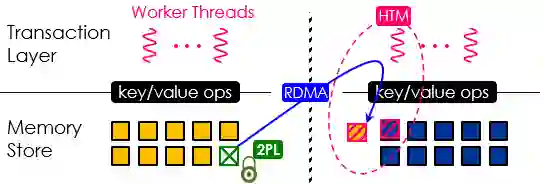
图 16系统总体思想
如图16,RDMA请求把数据拖过来锁住,然后通过HTM来执行,对数据进行计算和处理,再释放远端版本,同步回去。
l2PL中的独占锁(exclusive lock)和共享锁(sharedlock)
RDMA的语义有限制,单边RDMA只有读、写、CAS、XADD等操作,可以用RDMA的CAS操作实现独占锁,通过RDMA CAS把远端内存锁上,将数据取回。
很多数据是读共享的,无法用CAS锁住。因此我们实现了基于lease的共享锁,如果读到一个锁,给一段时间让大家都以读方式访问,但不能写,即可共享数据而无需加锁。过了这段时间后,其他人才可以进行写操作。这里需要同步时钟,用PTP(Precision Time Protocol)实现。
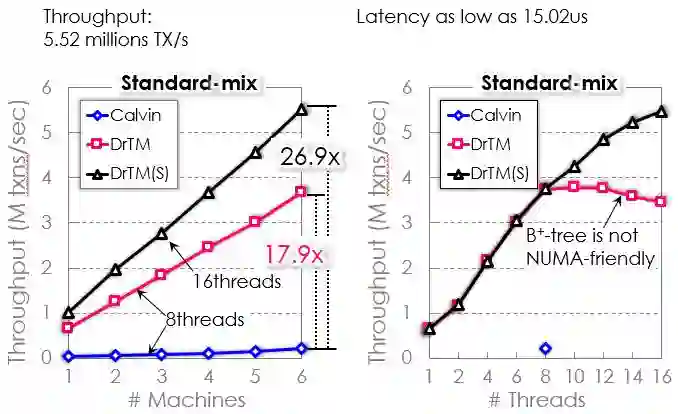
图 17 Performance on TPC-C
将DrTM和之前最好的Calvin系统进行对比,性能可以达到Calving的18倍。再对DrTM的限制进行扩展和优化,性能可以达到Calvin的27倍。
lDrTM的局限
要把远端的数据拖到本地执行,需要提前知道一个事务要读和写哪些数据。另外这个系统只实现了持久性,没有实现高可用性(Availability),可以保证事务提交后数据一直在,但不保证有一台机器挂掉事务还能继续执行。
4.2 DrTM+R
DrTM+R克服了DrTM的局限,采用Hybrid OCC方式探测读写集合,就不需要事先知道读写集合;采用Optimistic Replication机制确保高可用性。DrTM+R采用三副本方式,事务提交时会把日志复制到其他几台机器,如果有一台机器挂掉可以保证事务正常提交。
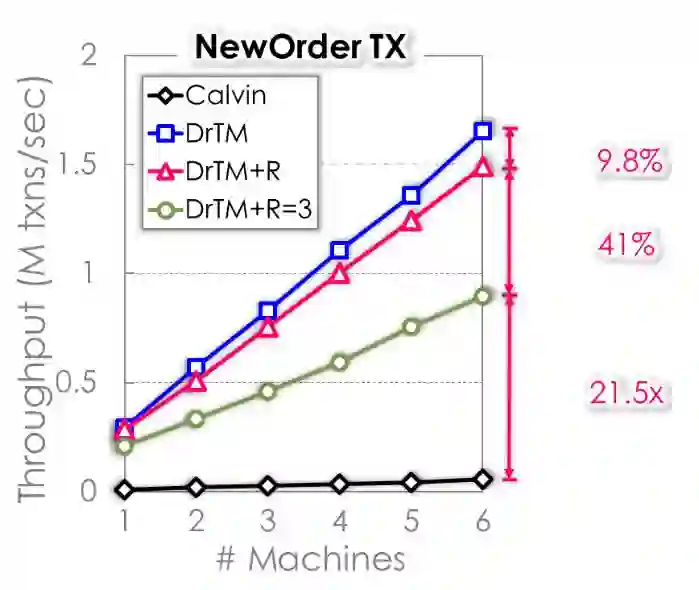
图 18 DrTM+R性能
DrTM+R相对于DrTM只增加了9.8%的性能开销,做三副本也只多了41%的性能开销。
4.3 DrTM+B: Replication-driven Reconfiguration
淘宝“双11”时热点一直在变化,某个店铺、某个商品促销时大家会集中访问这个workload,很容易把系统冲垮。所以数据库需要reconfiguration以支持负载均衡。
我们想做online reconfiguration,DrTM+R系统为支持高可用至少提供了3个副本的复制,可以用副本进行reconfiguration,这样不需要搬运数据。只要一台backup机器,根据它的负载选择将一部分工作交到它的replica,做到只在非常小的元数据集上重新划分,而不需要做真正数据上的划分。如果所有replica都很忙,就重新构造一个replica,开销也很小。

图 19 DrTM+B性能
如图是DrTM+B系统和传统方法性能的对比。吞吐量方面,传统方法甚至出现了停滞状态,但DrTM+B没有停滞状态。经过负载均衡,系统性能可以达到两倍的提升,时延也下降到原来的1/3。
4.4 IC3: Refined Concurrency Control
传统并发控制一般采用OCC或2PL,但还有很多并行性没有释放出来。我们的做法是将每个事务切小,之后对每个piece之间进行track,实现非常细粒度的并行工作,显著提升性能。
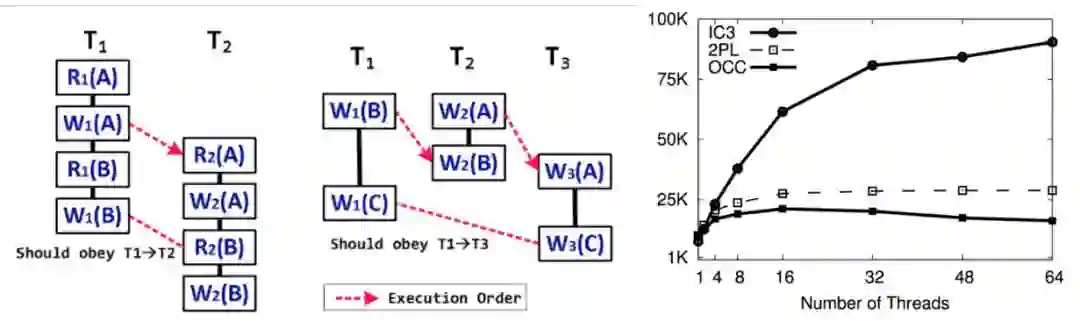
图20 IC3和OCC和2PL比较,在64个线程时性能还很高(纵坐标为吞吐量)
4.5 Cocytus: Reducing Memory Usage
实现高可用性需要三个副本,即每份数据要占3个内存,在大规模使用时成本较高,所以我们的另一个工作是减少内存使用。
一个思路是将磁盘存储常用的erasure coding方式应用到内存事务中。但直接应用会有很长的重构时间,对于内存事务在线恢复不可接受。而replication方式的内存利用率很低。所以我们的系统把erasure coding和replication结合用于Key/Value Store层,Key一般很小,Value比较大。所以Key用三副本方式做,Value用erasure coding方式做。两者结合可以做到primary-backup多副本快速恢复效果,且内存也非常节省。
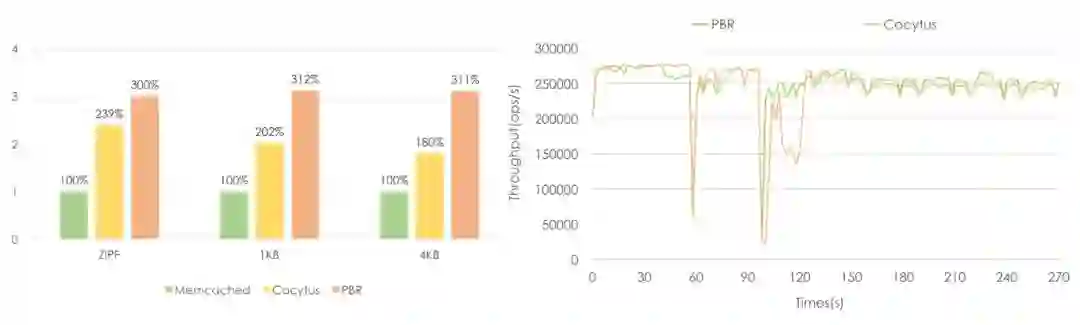
图21 Cocytus性能
可以看到相比PBR(primary-backup replication)方法内存使用降低1倍左右,且恢复时间也没有什么影响。
4.6 Eunomia: Scaling Up B+Tree using HTM
可以用基于HTM的方法构建B+树。B+树是数据库中非常基础的数据结构,但它在多核上的可扩展性目前尚未解决。基于HTM的B+树实际上是乐观控制的同步机制,没有竞争时性能很好,但竞争多时会持续中止事务,性能基本崩溃。
我们提出的scalable HTM-B+Tree,将大的HTM事务分成几个小事务。为避免违反Isolation特性,用opportunistic consistency validation方式使得事务切分后语义不改变。之后再主动检测true conflicts并对其进行一些限制。还采用了自适应争用控制策略,根据负载选择不同的方式,使低争用和高争用时性能都较好。
4.7 Distributed Query Processing
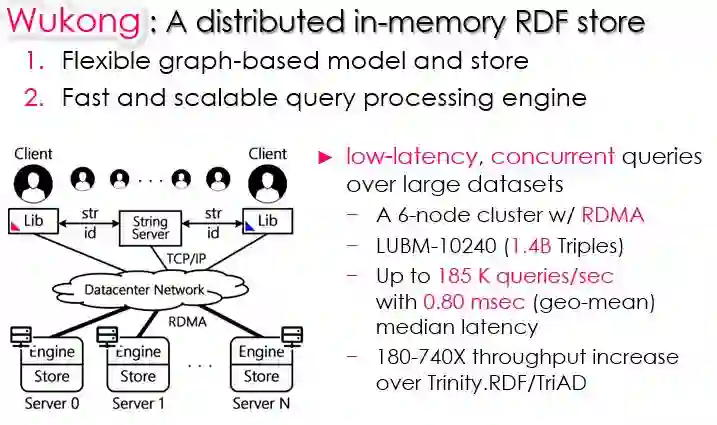
图22 分布式查询系统Wukong
另一个工作是基于图的分布式查询系统Wukong。神话中悟空筋斗云速度和RDMA速度差不多,所以取这个名。系统对于大量的并发请求,可以用很多线程同时处理这些查询,比之前最好的RDF查询系统吞吐量大180~740倍,时延达到0.8ms,比原来快一个数量级以上。
在此基础上结合Streaming Processing我们提出了Wukong-S系统,吞吐量达到百万量级的提升,且每个查询小于1毫秒。
Summary
内存事务需要高吞吐和低时延。RDMA和HTM为访问速度加快后解决其他系统设计的问题提供了非常好的支撑。通过一系列系统设计,能比传统系统在时延和吞吐量上有数量级的提升。
感谢AIDL志愿者顾一凡协助整理!
志愿者持续招募中,有意者联系微信号“AIDL小助手(ID:must-tech)”

历史文章推荐:
AI综述专栏| 大数据近似最近邻搜索哈希方法综述(下)(附PDF下载)
2018CCAI丨不忘初心,方得始终——我国人工智能发展如何务实推进
AI综述专栏| 大数据近似最近邻搜索哈希方法综述(上)(附PDF下载)





