gRPC 长连接在微服务业务系统中的实践

HTTP 长连接, 又称为 HTTP persistent connection, 也称作 HTTP keep-alive 或 HTTP connection reuse, 是指在一条 TCP 连接上发起多个 HTTP 请求 / 应答的一种交互模式。
那么什么是长连接, 什么是短连接? 他们和 TCP 有什么关系呢?
为了理解这个概念, 我们来看下图中 TCP 连接的三种行为。
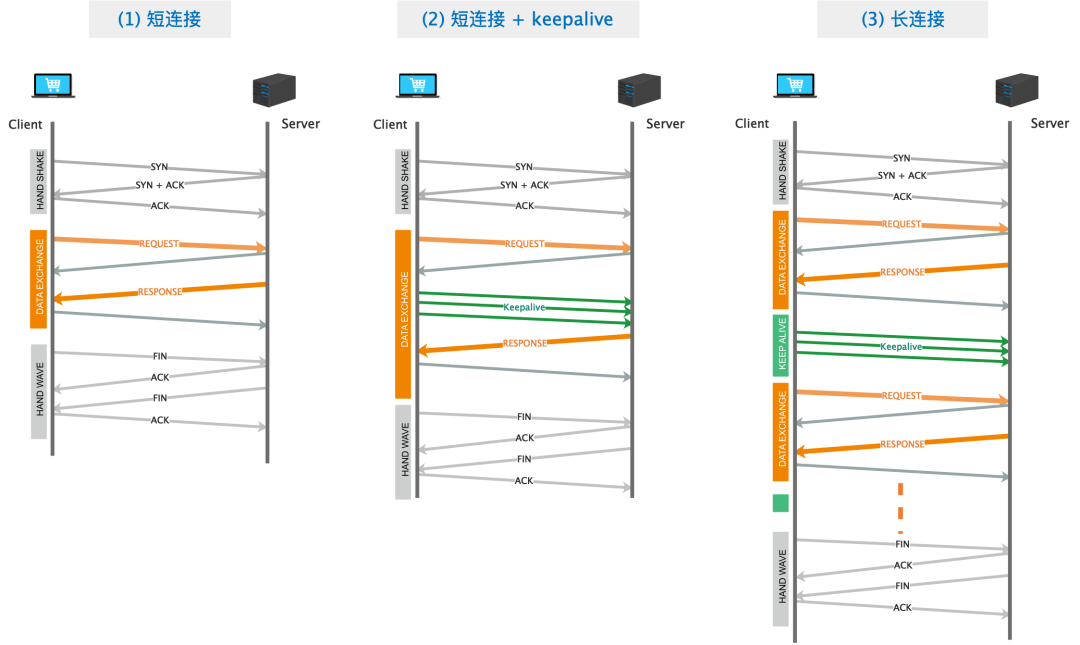
图一 展示了 client 和 server 端基于 TCP 协议的一次交互过程, 分为三个阶段: 三次握手, 数据交换和四次挥手。这个过程比较简单, 但是实际应用中存在一个问题。假如 server 处理请求过程非常耗时, 或者不幸突然宕机, 此时 client 会陷入无限等待的状态。为了解决这个问题, TCP 在具体的实现中加入了 keepalive。
图二 展示了 keepalive 的工作机制。当该机制开启之后, 系统会为每一个连接设置一个定时器, 不断地发送 ACK 包, 用来探测目标主机是否存活, 当对方主机宕机或者网络中断时, 便能及时的得到反馈并释放资源。
在图一和图二中可以看到, 虽然连接的持续时间不同, 但他们的行为类似, 都是完成了一次数据交互后便断开了连接, 如果有更多的请求要发送, 就需要重新建立连接。这种行为模式被称为短连接。
那有没有可能在完成数据交互后不断开连接, 而是复用它继续下一次请求呢?
图三 展示了这种交互的过程。在 client 和 server 端完成了一次数据交换后, client 通过 keepalive 机制保持该连接, 后面的请求会直接复用该连接, 我们称这种模式为长连接。
理解了上面的过程, 我们便可以得出下面的结论:
TCP 连接本身并没有长短的区分, 长或短只是在描述我们使用它的方式
长 / 短是指多次数据交换能否复用同一个连接, 而不是指连接的持续时间
TCP 的 keepalive 仅起到保活探测的作用, 和连接的长短并没有因果关系
需要注意的是, 在 HTTP/1.x 协议中也有 Keep-Alive 的概念。如下图, 通过在报文头部中设置 connection: Keep-Alive 字段来告知对方自己支持并期望使用长连接通信, 这和 TCP keepalive 保活探测的作用是完全不同的。

相比于短连接,长连接具有:
较低的延时。由于跳过了三次握手的过程,长连接比短连接有更低的延迟。
较低的带宽占用。由于不用为每个请求建立和关闭连接,长连接交换效率更高,网络带宽占用更少。
较少的系统资源占用。server 为了维持连接,会为每个连接创建 socket,分配文件句柄, 在内存中分配读写 buffer,设置定时器进行 keepalive。因此更少的连接数也意味着更少的资源占用。
另外, gRPC 使用 HTTP/2.0 作为传输协议, 从该协议的设计来讲, 长连接也是更推荐的使用方式, 原因如下:
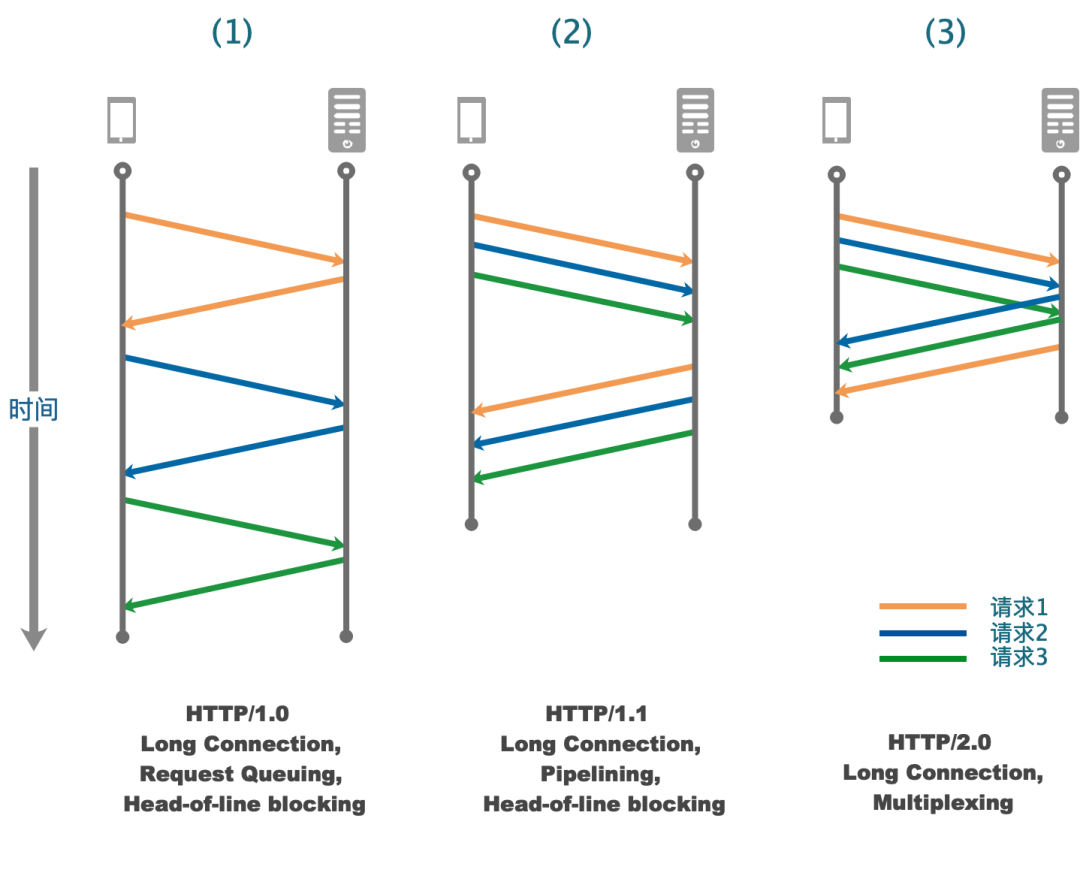
HTTP/1.0 开始支持长连接, 如下图 1, 请求会在 client 排队 (request queuing), 当响应返回之后再发送下一个请求。而这个过程中, 任何一个请求处理过慢都会阻塞整个流程, 这个问题被称为线头阻塞问题, 即 Head-of-line blocking。
HTTP/1.1 做出了改进, 允许 client 可以连续发送多个请求, 但 server 的响应必须按照请求发送的顺序依次返回, 称为 Pipelining (server 端响应排队), 如下图 2。这在一定程度上提高了复用效率, 但并没能解决线头阻塞的问题。
HTTP/2.0 引入了分帧分流的机制, 实现了多路复用 (乱序发送乱序接受), 彻底的解决了线头阻塞, 极大提高了连接复用的效率。如下图 3。
除了分帧分流之外, HTTP/2.0 还加入了诸如流控制和服务端推送等特性, 这也使得协议变得复杂, 连接的建立和维护成本升高。
下图展示了 HTTP/1.1 一次短连接交互的过程。可以看到, 握手和挥手之间, 只发生了两次数据交换, 一次请求①和一次响应②。

下图展示了 HTTP/2.0 一次短连接交互过程, 握手和挥手之间, 发生了多达 11 次的数据交换。除了 client 端请求 (header 和 body 分成了两个数据帧, 于第⑤⑥步分开传输)和 server 端响应 (⑨) 之外, 还夹杂着一些诸如协议确认 (①) , 连接配置 (②③④) , 流管理 (⑦⑩) 和探测保活 (⑧⑪) 的过程。
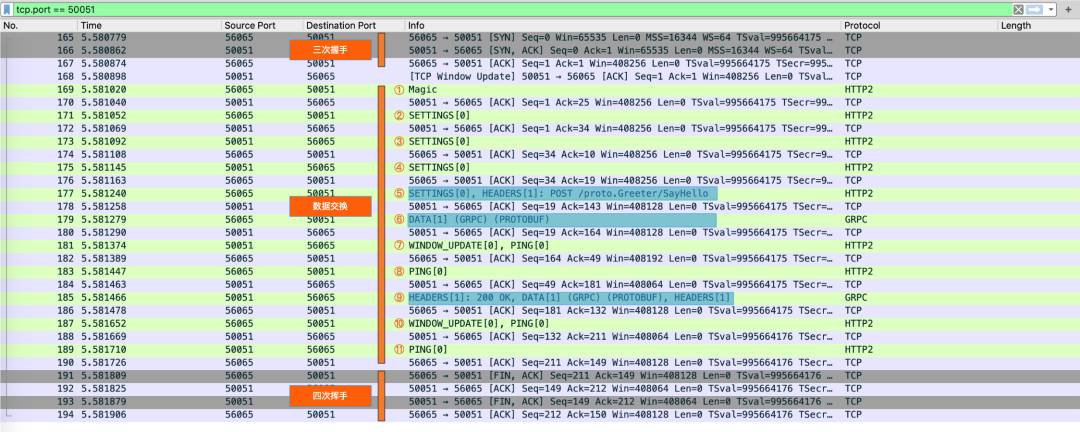
很明显可以看出, HTTP/2.0 的连接更重, 维护成本更高, 使得复用带来的收益更高。
虽然长连接有很多优势, 但并不是所有的场景都适用。在使用长连接之前, 至少有以下两个点需要考虑。
长连接模式下, server 要和每一个 client 都保持连接。如果 client 数量远远超过 server 数量, 与每个 client 都维持一个长连接, 对 server 来说会是一个极大的负担。好在这种场景中, 连接的利用率和复用率往往不高,使用简单且易于管理的短连接是更好的选择。即使用长连接, 也必须设置一个合理的超时机制, 如在空闲时间过长时断开连接, 释放 server 资源。
现代后端服务端架构中, 为了实现高可用和可伸缩, 一般都会引入单独的模块来提供负载均衡的功能, 称为负载均衡器。根据工作在 OSI 不同的层级, 不同的负载均衡器会提供不同的转发功能。接下来就最常见的 L4 (工作在 TCP 层)和 L7 (工作在应用层, 如 HTTP) 两种负载均衡器来分析。
L4 负载均衡器: 原理是将收到的 TCP 报文, 以一定的规则转发给后端的某一个 server。这个转发规则其实是
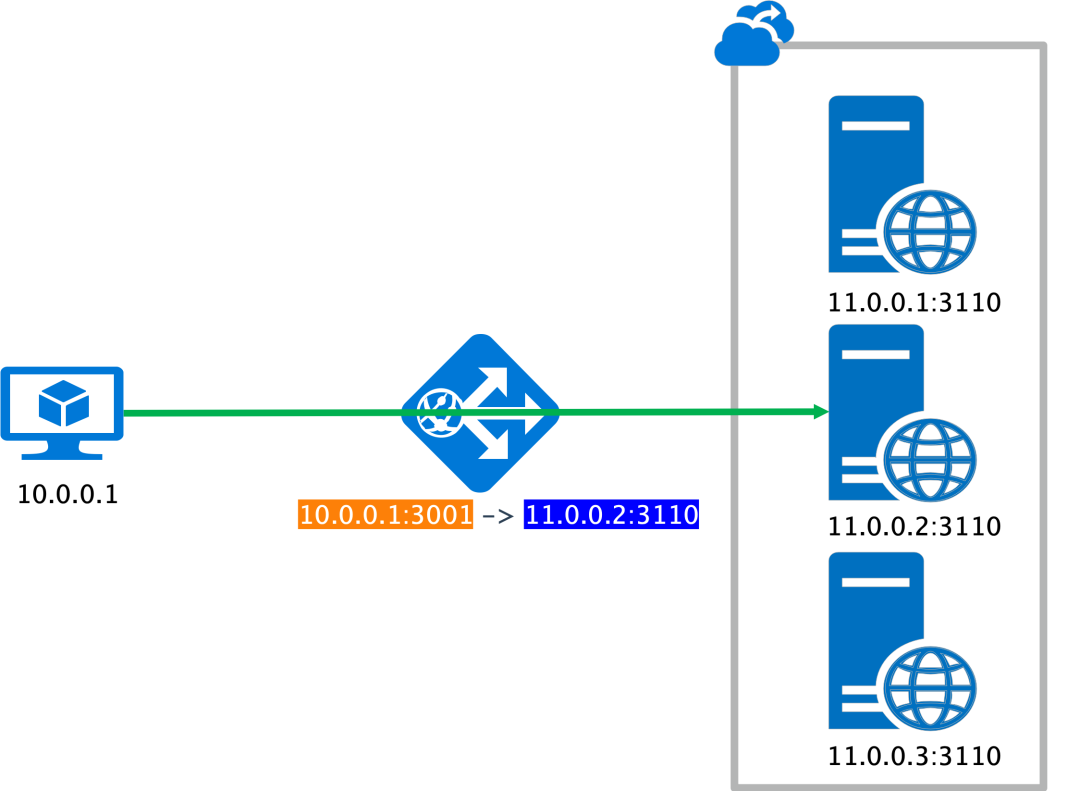
在短连接模式下, 由于连接会不断的建立和关闭, 同一个 client 的流量会被分发到不同的 server。
在长连接模式下, 由于连接一旦建立便不会断开, 就会导致流量会被分发到同一个 server。在 client 与 server 数量差距不大甚至 client 少于 server 的情况下, 就会导致流量分发不均。如下图中, 第三个 server 会一直处于空闲的状态。
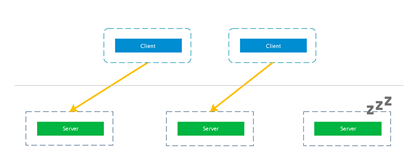
为了避免这种场景中负载均衡失效的情况, L7 负载均衡器便成了一个更好的选择。
L7 负载均衡器: 相比 L4 只能基于连接进行负载均衡, L7 可以进行 HTTP 协议的解析. 当 client 发送请求时, client 会先和 L7 握手, L7 再和后端的一个或几个 server 握手,并根据不同的策略将请求分发给这些 server,实现基于请求的负载均衡. 如下图所示,10.0.0.1 通过长连接发出的多个请求会根据 url, cookies 或 header 被 L7 分发到后端不同的 server。
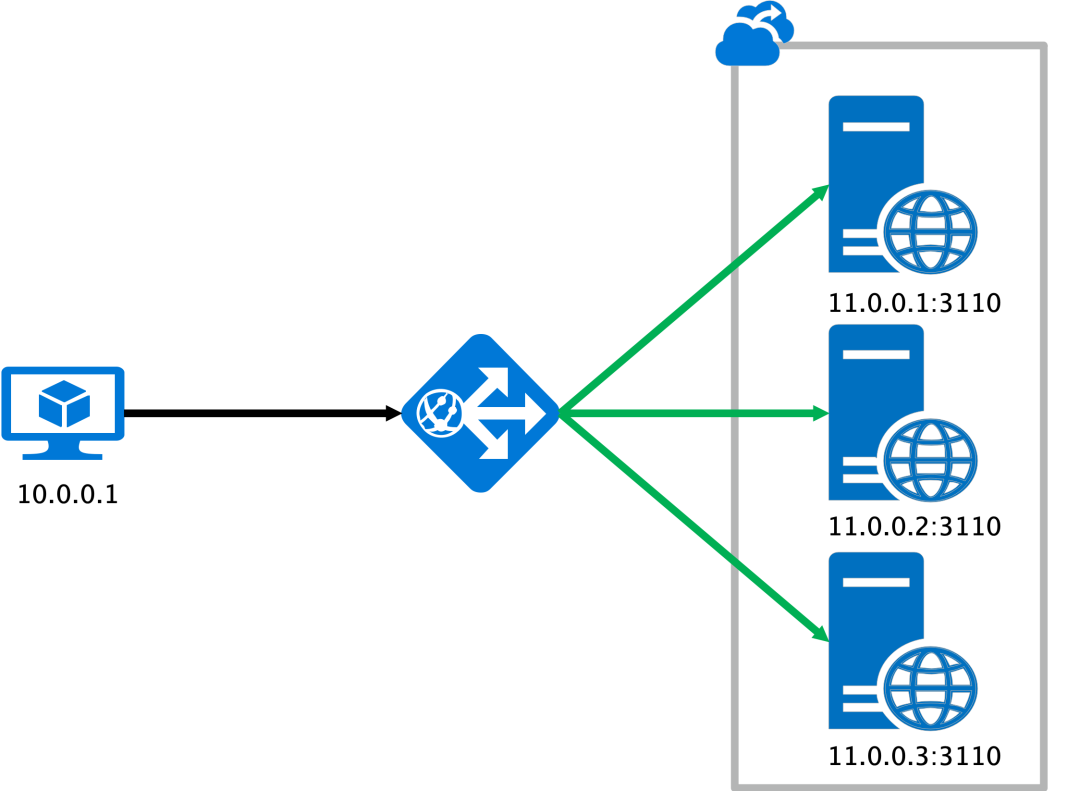
因此,必须要意识到,虽然长连接可以带来性能的提升,但如果忽略了使用场景或是选择了错误的负载均衡器,结果很可能会适得其反。实践中一定要结合实际情况, 避免因错误的使用导致性能下降或者负载均衡失效的情况发生。
Biz-UI 的业务系统采用 Kubernetes + Istio 架构来作为生产平台。Kubernetes 负责服务的部署、升级和管理等较基础的功能。Istio 负责上层的服务治理, 包括流量管理, 熔断, 限流降级和调用链治理等。在这之上,业务系统服务之间则使用 gRPC 进行远程调用。
Istio 功能的实现依赖于其使用 sidecar (默认为 Envoy)控制 Pod 的入站出站流量, 从来进行劫持和代理转发。
下图展示了 Istio 中两个 service 流量的转发过程。
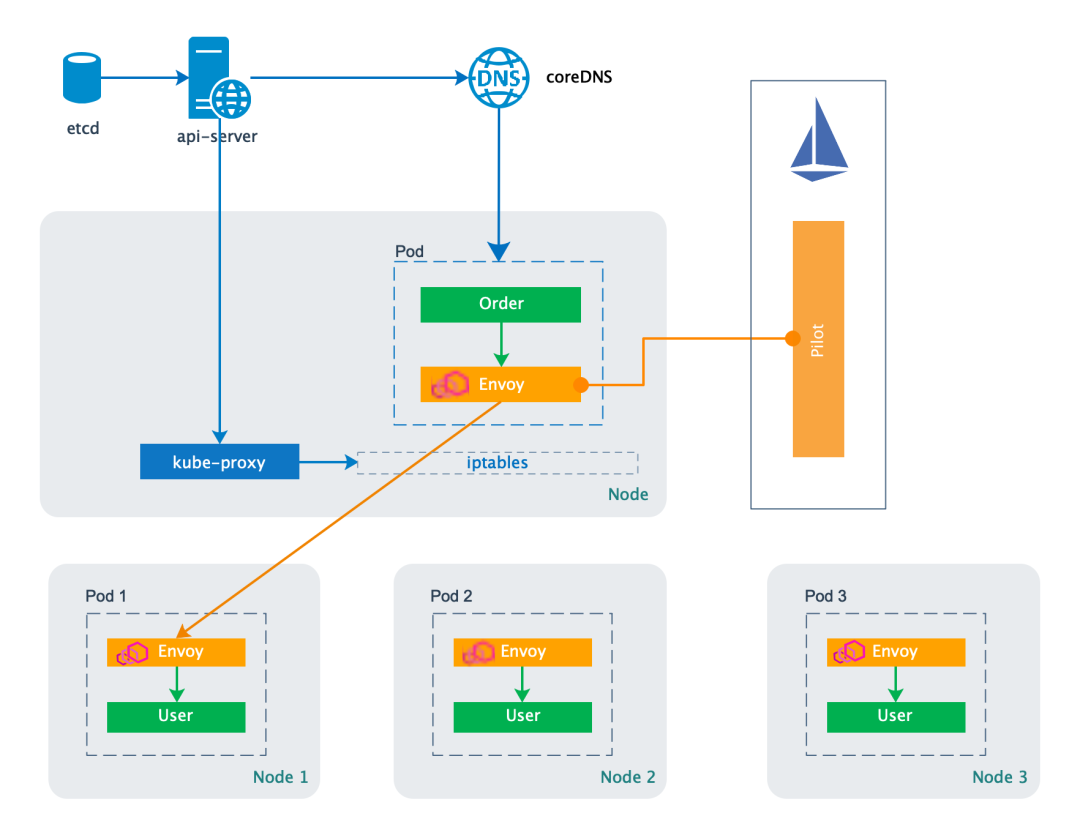
蓝色部分是 Kubernetes 的一些基本组件, 如集群元数据存储中心 etcd, 提供元数据查询和管理服务的 api-server, 服务注册中心 coreDNS, 负责流量转发的 kube-proxy 和 iptables。
黄色的部分是 Istio 引入的 Pilot 和 Envoy 组件。Pilot 通过 list/watch api-server 来为 Envoy 提供服务发现功能。Envoy 则负责接管 Pod 的出站和入站流量, 从而实现连接管理, 熔断限流等功能。和 nginx 类似, Envoy 也是工作在第七层。
绿色部分表示提供业务功能的两种服务, 订单服务 (Order) 和用户数据服务 (User)。
Order 调用 User 服务的过程为:
Order 通过 coreDNS 解析到 User 服务对应的 ClusterIP。
当 Order 向该 ClusterIP 发送请求时, 实际上是同 Envoy 代理建立连接。
Envoy 根据 Pilot 的路由规则, 从 ClusterIP 对应的多个 User Pod IP 中选择一个, 并同该 Pod 的 Envoy 代理建立连接。
最后, User 的 Envoy 代理再与 User 建立连接, 并进行请求转发。
在这个过程中, 总共有三个连接被建立:
第一个连接是 Order -> Order Envoy, 是由 Order 建立并控制。
第二和第三个连接是 Order Envoy -> User Envoy -> User, 由 Envoy 发起和建立, 不受 Order 控制。默认是工作在长连接模式, 并通过连接池进行维护。
具体实践中, Envoy 会选择建立多个连接的方式来提高可用性。如下面的图示中:
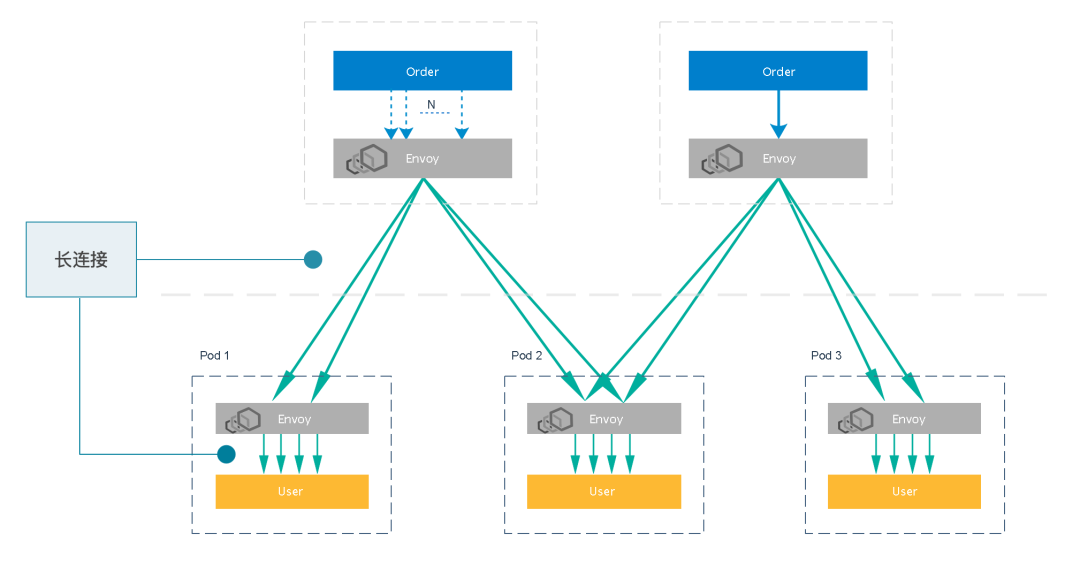
绿色的连接表示由 Envoy 管理的连接。可以看到, Order Envoy 会选择多个上游 User Envoy,并分别与每一个建立两个长连接。同时,每个 User Envoy 也会与 User 建立四条长连接。这个行为是 Envoy 的行为,不受 Order 连接 (蓝色的部分) 的影响。
蓝色的连接表示由 Order 管理的连接。可以看到,无论是建立 N 个短连接 (图左上方)还是一个长连接 (图右上方),Order 发出的多个请求都会经过两层长连接分发到不同的 User 实例上,从而实现基于请求的负载均衡。
值得注意的是, Order service 中代码的实现决定了蓝色的连接为长连接或短连接, 且不会影响绿色的部分。
我们以下面的 proto 文件为例来讲述基于 Go 语言的实现。
syntax = "proto3";package test;message HelloRequest {string message = 1;}message HelloResponse {string response = 1;}service TestService {rpc SayHello (HelloRequest) returns (HelloResponse) {}}
proto 生成对应的 client 代码如下:
type TestServiceClient interface {SayHello(ctx context.Context, in *HelloRequest, opts ...grpc.CallOption)(*HelloResponse, error)}type testServiceClient struct {cc *grpc.ClientConn}func NewTestServiceClient(cc *grpc.ClientConn) TestServiceClient {return &testServiceClient{cc}}func (c *testServiceClient) SayHello(ctx context.Context, in *HelloRequest,opts ...grpc.CallOption) (*HelloResponse, error) {out := new(HelloResponse)err := grpc.Invoke(ctx, "/test.TestService/SayHello", in, out, c.cc, opts...)if err != nil {return nil, err}return out, nil}
我们可以看到, testServiceClient (以下简称 client)中有一个成员变量 grpc.ClientConn (以下简称 con),它代表了一条 gRPC 连接,用来承担底层发送请求和接受响应的功能。client 和 con 是一对一绑定的,为了连接复用,我们可以把其中任何一个提取成共享变量,将其改写成单例模式。
假如将 con 提取成共享变量,那么每次复用的时候,还需为其新建一个 client 对象,因此我们可以直接将 client 提取成共享变量。
首先我们定义两个包级别共享变量,
// 实现了 TestServiceClient 接口, 作为共享连接的载体var internalTestServiceClientInstance proto.TestServiceClient// 互斥锁, 用来对 internalTestServiceClientInstance 提供并发访问保护var internalTestServiceClientMutex sync.Mutex
然后我们构建一个 client 的代理,对外暴露方法调用,对内提供
internalTestServiceClientInstance 的封装。然后按照如下的方式实现 SayHellotype internalTestServiceClient struct {dialOptions []grpc.DialOption}func (i *internalTestServiceClient) SayHello(ctx context.Context, req*proto.HelloRequest, opts ...grpc.CallOption) (*proto.HelloResponse, error) {// 通过配置⽂件来控制是否启⽤⻓连接useLongConnection := grpcClient.UseLongConnection() && len(i.dialOptions) ==0// 如果启⽤了⻓连接, 且 client 已被初始化, 直接进⾏⽅法调⽤if useLongConnection && internalTestServiceClientInstance != nil {return internalTestServiceClientInstance.SayHello(ctx, req, opts...)}// 当启⽤了⻓连接, 但 client 还未被初始化时, 进⾏初始化c, conn, err := getTestServiceClient(i.dialOptions...)if err != nil {return nil, err}if useLongConnection {internalTestServiceClientMutex.Lock()defer internalTestServiceClientMutex.Unlock()// DCL 双重检查, 确保实例只会被初始化⼀次if internalTestServiceClientInstance == nil {internalTestServiceClientInstance = clog.Info("long connection established for internalTestServiceClient")} else {// 当未通过双重检查时, 关闭当前连接, 避免连接泄露defer grpcClient.CloseCon(conn)log.Info("long connection for internalTestServiceClient has beenestablished, going to close current connection")}} else {// 当⻓连接未开启, 则在⽅法调⽤后关闭连接defer grpcClient.CloseCon(conn)}return c.SayHello(ctx, req, opts...)}
这里需要注意的几个点:
client 的共享而不是 con 层的共享
懒加载
DCL 双检查避免连接泄露
当使用自定义的 dialOptions 时, 切换到短连接模式
我们在 Istio 平台下, 对同一个接口在长连接和短连接两种模式下的响应时间和吞吐量进行了压力测试。
首先是对响应时间的测试, 结果如下图所示。
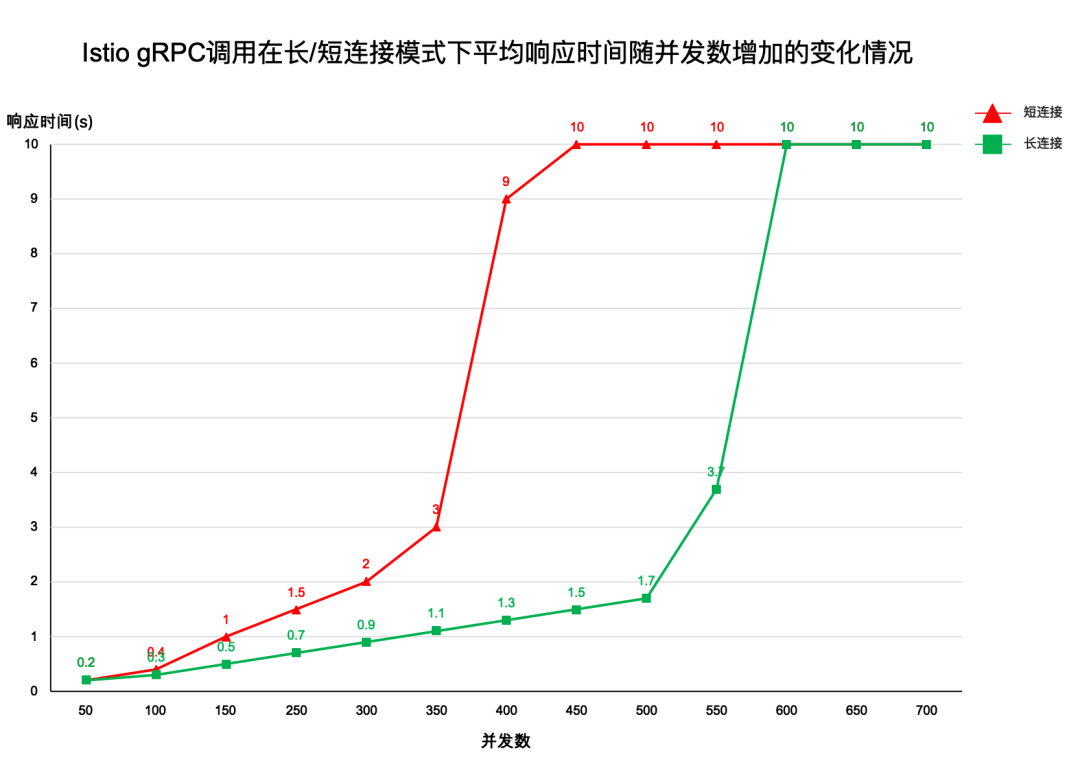
对短连接来说, 当并发数 <350 的, 响应时间呈线性增长, 当并发数超过 350 时, 响应时间陡增, 很快达到了 10s 并引发了超时。
对长连接来说, 当并发数 <500 时, 响应时间虽然也呈线性增长, 但比短连接要小。当并发数超过 500 时, 响应时间陡增并很快超时。
接下来是吞吐量的测试, 结果如下图所示。
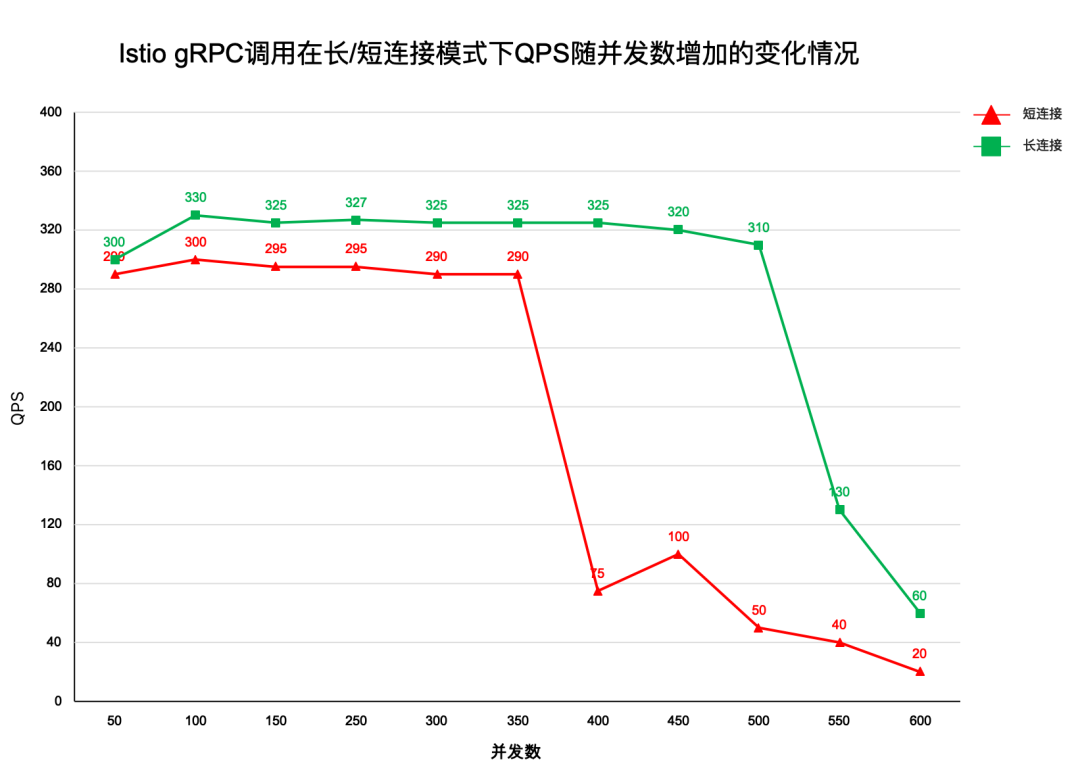
对短连接来说, 当并发数 <350 时, 吞吐量基本维持在 290, 超过 350 便开始骤减。
对长连接来说, 当并发数 <500 时, 吞吐量基本维持在 325, 超过 500 便开始骤减。
从测试结果来看, 长连接和短连接都存在明显的性能拐点 (长连接为 500, 短连接为 350), 在到达拐点之前, 性能变化较为平稳,一旦超过便急剧下降。但无论是从响应时间,QPS, 或是拐点值大小来看, 长连接都明显要优于短连接。
本文深入解释了长连接和短连接概念, 并阐述了长连接的优势及使用时应考虑的问题。结合 Biz-UI 的业务系统, 分析了 Istio 平台中 gRPC 连接的管理方式和长连接基于 Go 语言的实现, 并通过性能测试展示了长连接带来的响应时间和吞吐量上的提升, 为 gRPC 框架中使用长连接提供了有力的理论依据和数据支持。
希望此文会对你有所帮助!
参考链接:
【1】[HTTP/2.0 - RFC7540]
https:// httpwg.org/specs/rfc7540.html
【2】[TCP keepalive]
https://www.freesoft.org/CIE/RFC/1122/71.htm
【3】[HTTP Keep-Alive]
https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Keep-Alive
【4】[gRPC]
https://grpc.io/
【5】[Istio]
https://istio.io/
【6】[Kubernetes]
https://kubernetes.io/
【7】[Envoy Doc]
https://www.envoyproxy.io/docs/envoy/latest/
【8】[NGINX Layer 7 Load Balancing]
https://www.nginx.com/resources/glossary/layer-7-load-balancing/
作者简介:
张琦,FreeWheel Biz-UI 团队高级研发工程师, 热衷于新技术的研究与分享,擅长发现与解决后端开发痛点,目前致力于 Go,容器化和无服务化相关的实践。





