©PaperWeekly 原创 · 作者 | 宁金忠
单位 | 大连理工大学
研究方向 | 信息抽取
都 2222 年了,信息抽取领域早已经是诸神黄昏。然而,多模态方法的兴起给这个卷成麻花的领域带来的新的希望。就像阳光穿过黑夜,黎明悄悄划过天边,既然新的多模态风暴已经出现,我们怎能停滞不前?
让我们通过本文了解一下信息抽取领域中多模态方法的最新进展。本文分为两大主要章节,第一章介绍多模态关系抽取任务(Multimodal Neural Relation Extraction, MNRE),第二章介绍多模态命名实体识别任务(Multimodal Named Entity Recognition MNER)。
多模态关系抽取
任务介绍:多模态关系抽取任务的一个例子如下图所示。和基于文本的关系抽取方法相比,其他模态数据(例如图片)中的提示信息有利于性能的提升。
1.1 MNRE
论文标题:
MNRE: A Challenge Multimodal Dataset for Neural Relation Extraction with Visual Evidence in Social Media Posts
收录会议:
论文链接:
https://ieeexplore.ieee.org/document/9428274
代码链接:
https://github.com/thecharm/MNRE
Motivation:关系抽取模型在面对社交媒体领域中长度偏短且缺少有效内容的文本时表现乏善可陈。同样,远程监督方法面对这种情景也显得力不从心。于是,寻找文本之外的内容来补充文本信息势在必行。
作者选择 Glove+CNN,BERTNRE,BERT+CNN 为本文的对比实验。在三个对比实验的基础上分别增加 Image Labels、Visual Objects、Visual Attention 做为多模态关系抽取的基准模型。
1.2 Mega
Multimodal Relation Extraction with Efficient Graph Alignment
ACM MM 2021
https://dl.acm.org/doi/abs/10.1145/3474085.3476968
https://github.com/thecharm/Mega
Motivation:使用 image-related information 对纯 text-based 信息中的缺失内容进行补充,从而提升社交媒体领域的关系抽取任务的性能。
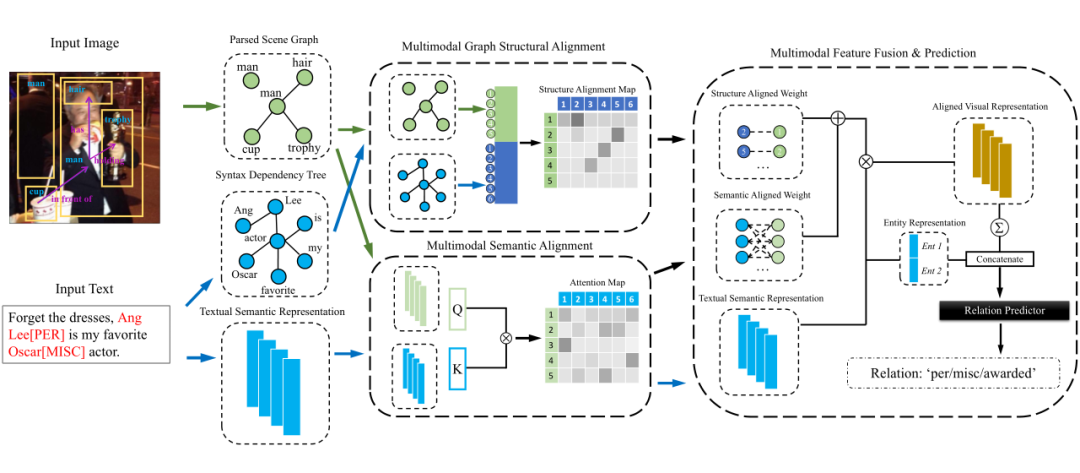
对于输入文本,作者使用 BERT 作为语义特征编码器。除此之外,作者使用句法解析工具提取了文本的句法解析树。对于输入图片,作者提取出其中目标的 scene graph。作者使用双流模型结构分别从图关系结构和语义两个方面来对齐文本和图像两个模态的信息。在模态特征融合阶段,作者把包含双模态的图结构对齐信息和语义表示对齐信息融合成一个向量,然后将其与头尾实体的表示向量进行拼接,最终得出关系的预测。
多模态命名实体识别
相比于多模态关系抽取任务,多模态多模态命名实体(MNER)任务由于起步较早已经涌现出了较多的工作。本章节中,我们把多模态命名实体识别任务按照使用的模态划分为:(1)基于语音-文本的 MNER(2)基于汉字结构特征 MNER(3)基于图片-文本的 MNER。
2.1 基于语音-文本的MNER
A Large-Scale Chinese Multimodal NER Dataset with Speech Clues
ACL 2021
https://aclanthology.org/2021.acl-long.218
https://github.com/dianbowork/cnerta
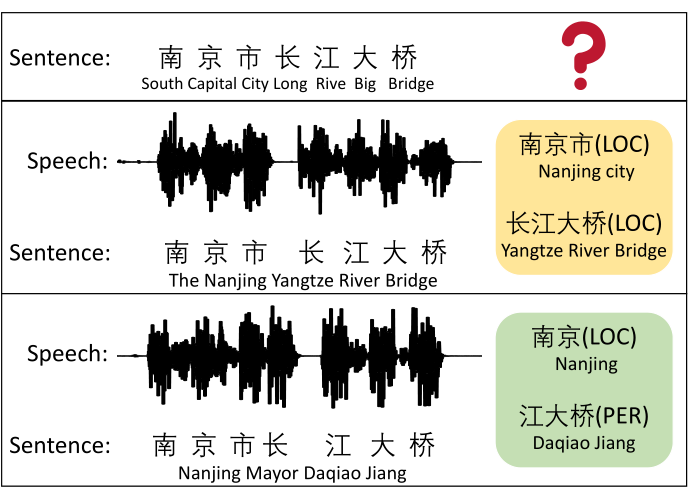
由于中文缺少天然的分词间隔,中文 NER 任务面临着比较大的挑战。语音中包含的停顿信息对于确定中文的分词边界具有很大的潜在的价值。例如上图所示的“南京市长江大桥”这个例子。
作者构建了一个包含语音和文本数据的中文 MNER 数据集,其中包含 34102 条训练样本,测试集数量为 4445,开发集容量为 4440。
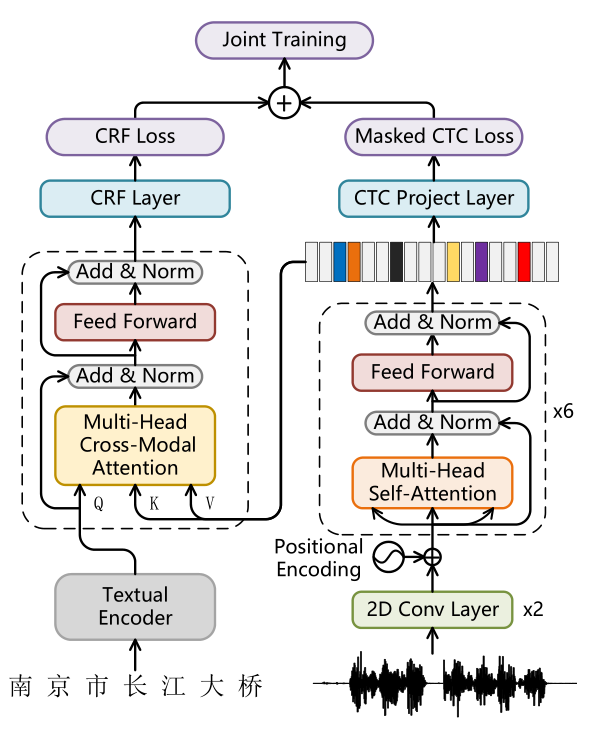
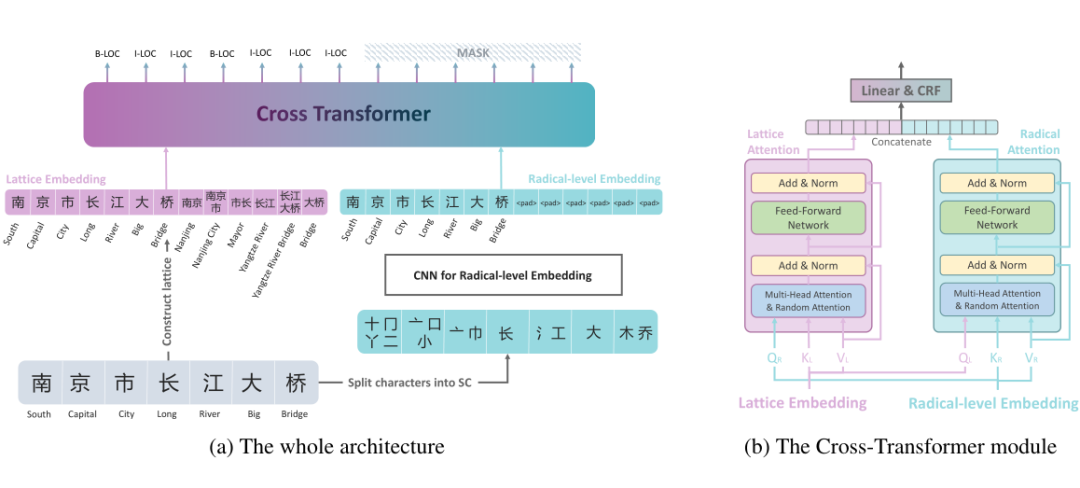
作者使用 BERT 作为文本特征编码器,使用 CNN 下采样的梅尔滤波器组特征作为语音特征表示。文中提出的模型使用多任务学习的方法来对齐和融合模型特征。模型包含 CRF loss 和 masked CTC loss 两部分。对于 masked CTC loss 的获得,首先把语音特征表示会输入到一个 Transformer 模块进行编码,然后使用语音识别领域中常用的 CTC loss 进行语音和文本的对齐。
由于模型重点关注于同一条数据中语音和文本的对齐,作者提出了 masked CTC loss,将 CTC 对齐结果里没有在文本中出现的字的概率置为负无穷。这样操作将 CTC 的对齐结果限制到了文本的词汇之内。对于 CRF loss 的获取,作者使用多模态领域常用的 Cross-Transformer 将 masked CTC loss 约束的语音表示和文本表示进行交叉融合,得到语音信息辅助的文本表示,然后经过 CRF 层得到 CRF loss。最终,CRF loss 和 masked CTC loss 相加进行联合训练。
2.2 使用汉字结构信息的MNER
汉字属于象形文字,汉字的结构中具有语义相关的信息。例如包含部首“疒”的汉字,例如,“病”,“痉”等汉字可能代表某些疾病。因此,利用汉字的结构信息具有提升命名实体识别性能的潜力。
2.2.1 Glyce
Glyce: Glyph-vectors for Chinese Character Representations
NeurlPS 2019
https://arxiv.org/abs/1901.10125
https://github.com/ShannonAI/glyce
Motivation:将汉字图片的视觉特征融合进模型以提升 NLP 任务。
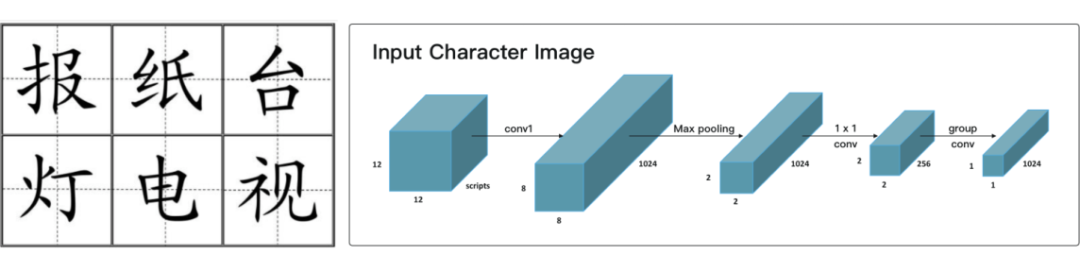
由于简体字经过了简化,其结构体现出的语义信息变少,作者使用隶属,繁体字等古汉字的文字图片来编码汉字结构信息。
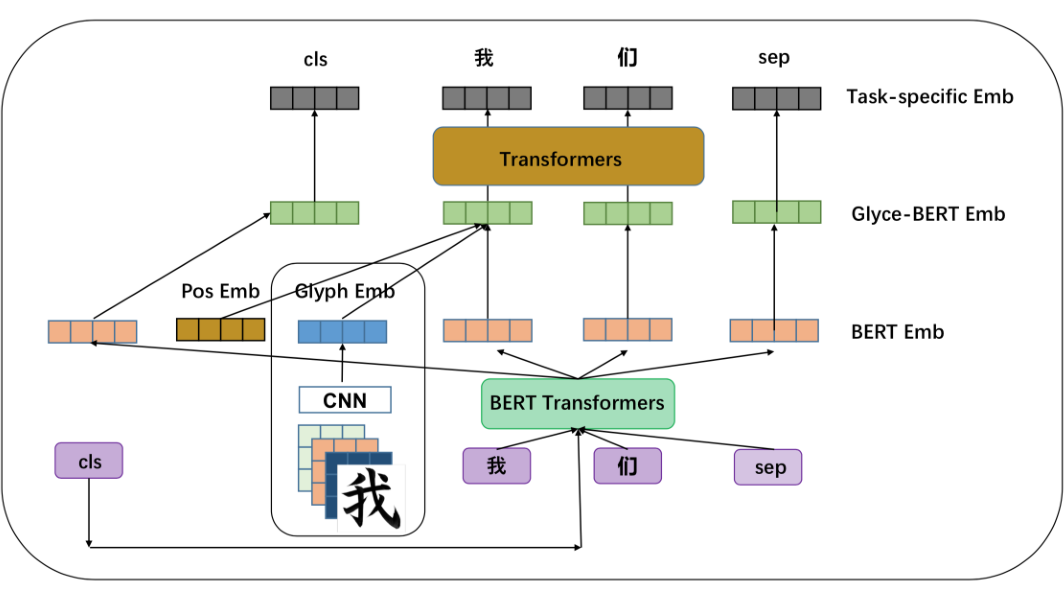
作者设计了一种名叫“田字格 CNN”的 CNN 结构进行汉字图片的特征提取。输入的汉字图像以此经过上图所示的卷积层,max-pooling 层,卷积层。最后经过一个 group convolutions 得到最终的输出——Glyph Embedding。作者在文中解释到,使用尺寸较小的 group convolutions 可以防止过拟合,并且在全体汉字上具有较好的泛化性能。
关于 Glyph Emb 和 BERT 输出向量的融合,作者把 Glyph Emb 和其对应的位置编码向量进行相加,然后与 BERT 拼接到一起。
使用汉字图片的分类任务作为一个 auxiliary 任务和下游的 nlp 任务联合训练。以 NER 任务为例,模型的损失函数由汉字图片分类任务和 CRF loss 加权相加得到。
2.2.2 MECT
MECT: Multi-Metadata Embedding based Cross-Transformer for Chinese Named Entity Recognition
ACL 2021
https://arxiv.org/abs/2107.05418
https://github.com/CoderMusou/MECT4CNER
Motivation:使用汉字的部首特征来提升命名实体识别模型的性能。
Method:作者把文本中的每个汉字拆解成部首,然后使用 CNN 提取汉字的部首特征。把汉字和文本中匹配上的词汇,作为文本的一个特征。作者把汉字的部首特征看做文本的另外一个模态。对于两个模态的特征,作者使用多模态领域中常用的 two-stream Cross-Transformer 来进行特征的融合。作者在 Cross-Transformer 中引入相对位置信息和 Random Attention 增强模型的表达能力。
2.2.3 ChineseBERT
ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information
ACL 2021
https://arxiv.org/abs/2106.16038
https://github.com/ShannonAI/ChineseBert
motivation:使用汉字的 Glyph embedding 来提升命名实体识别模型的性能。
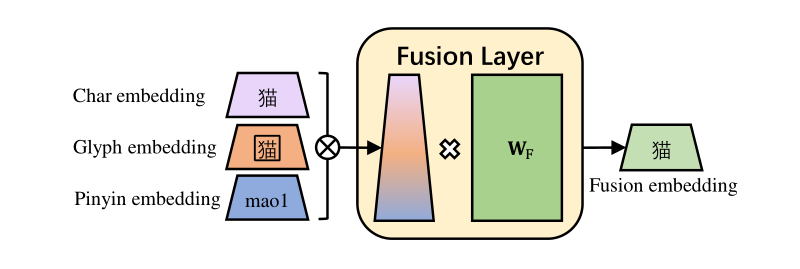
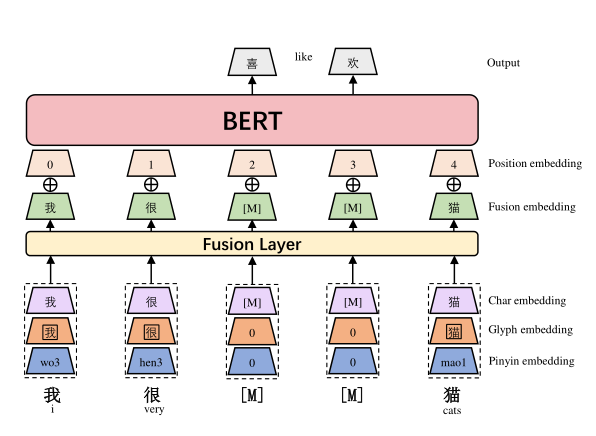
对于同一个汉字,作者使用汉字的词向量,汉字图片的特征表示和拼音的特征表示这三个模态的特征得到一个汉字的融合特征。作者将三个模态的特征向量拼接,然后经过线性层进行特征的融合表示。
作者将汉字的多模态融合特征输入到一个 BERT 当中,然后使用大规模语料从头进行预训练。作者在预训练的过程中,使用了 Whole WordMasking(WWM) and Char Masking(CM)策略。
2.3 使用图片-文本的MNER
社交媒体用户产生的文本具有噪音大,长度短等特点。因此社交媒体的命名实体识别面临着很大挑战。然而,社交媒体上的配图可以作为文字的补充可以结合文字中的信息共同提升多模态 NER 任务。
2.3.1 MNER
Multimodal Named Entity Recognition for Short Social Media Posts
NAACL 2018
https://arxiv.org/abs/1802.07862
作者首次提出了多模态命名实体识别(MNER)任务,并且发布了一个 MNER 数据集 SnapCaption。
作者将词汇的词向量,词汇的字符信息以及 Inception 提取的目标特征融合到三个模态的通过一个注意力机制融合到一起,当做词汇的多模态融合特征,然后使用 Bilstm+CRF 来编码出 NER 标签。
2.3.2 NERmultimodal
Adaptive co-attention network for named entity recognition in tweets
AAAI 2018
https://ojs.aaai.org/index.php/AAAI/article/view/11962
https://github.com/jlfu/NERmultimodal
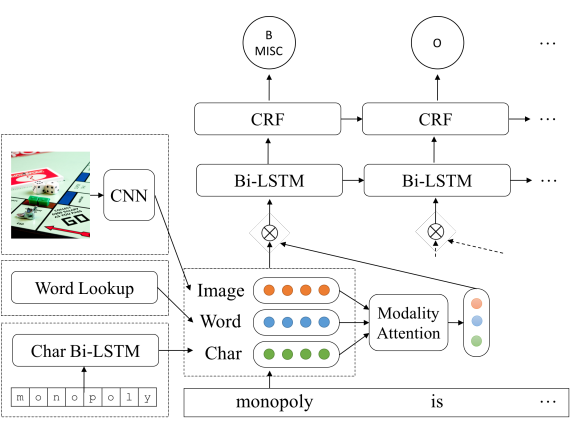
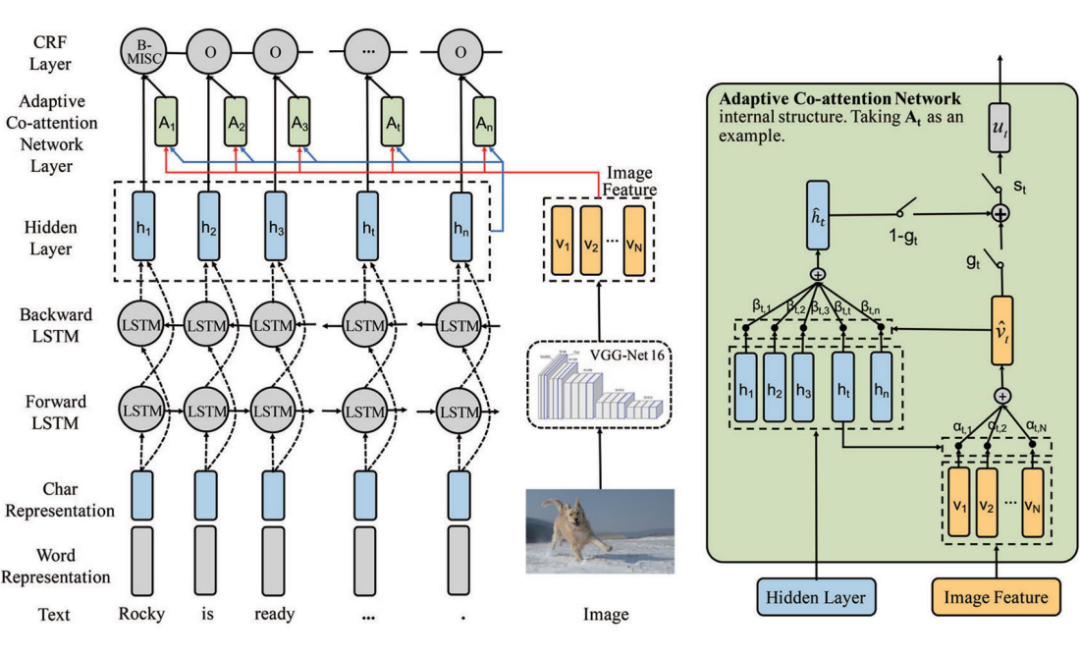
method:作者首次提出字 MNER 任务上使用 co-attention 进行融合视觉和文本两个模态的特征,启发了日后使用 Cross-Transformer 来进行信息抽取领域中视觉-文本特征的融合的工作。作者使用 Char 表示和 word 表示进行拼接,作为文本的语义特征表示。然后使用双向 LSTM 进行序列编码。
对于图像,作者使用 VGG-NET16 进行图像特征编码。之后,作者提出了 Co-attention 得到 Word-Guided Visual Attention 和 Image-Guided Textual Attention,然后使用注意力机制融合两个 attention。这是初代的 two-stream 多模态模型。
2.3.3 UMT
Improving Multimodal Named Entity Recognition via Entity Span Detection with Unified Multimodal Transformer
ACL 2020
https://aclanthology.org/2020.acl-main.306
https://github.com/jefferyYu/UMT
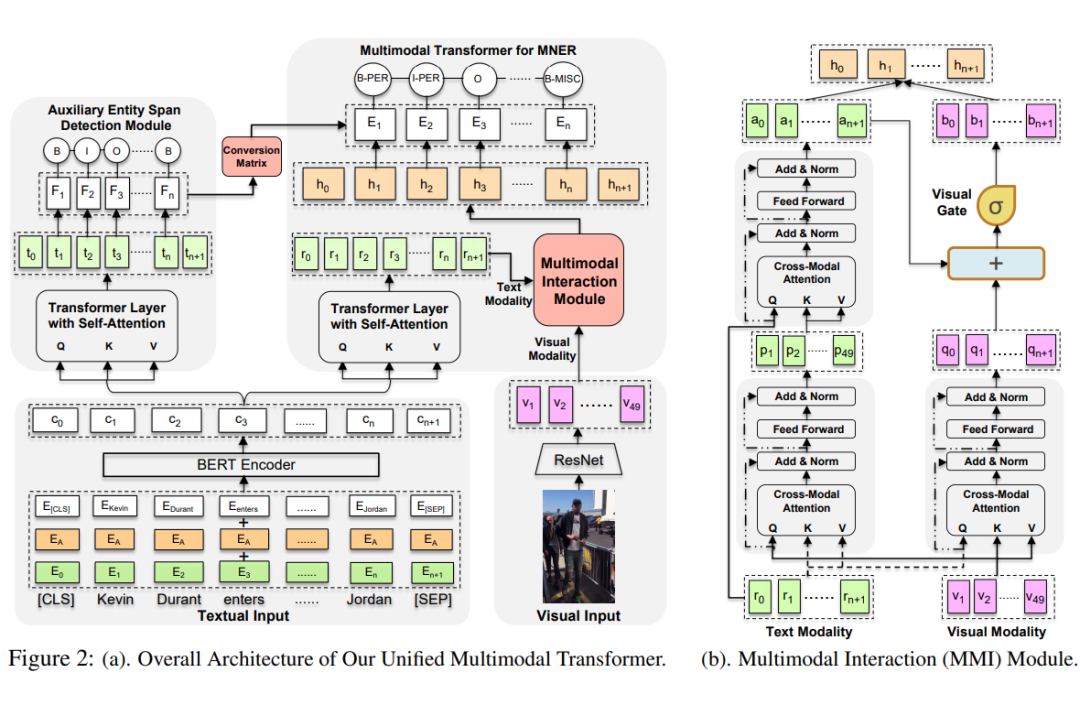
Method:作者提出使用统一的 Transformer 结构来进行多模态信息的交互。作者使用三个 cross transformer 分别获得图像指导的文本表示、文本指导的图像表示以及文本模态内部的交互表示。作者在两个模态信息交互的过程中通过一个 Visual Gate 动态控制两个模态之间的交互。除此之外,作者还附加了一个实体范围识别的任务作为 auxiliary 任务,通过多任务的方式训练模型。
2.3.4 RIVA
RIVA: A Pre-trained Tweet Multimodal Model Based on Text-image Relation for Multimodal NER
COLING 2020
https://aclanthology.org/2020.coling-main.168
Motivation:在模型中引入判断图像-文本关系的部分来应对社交媒体数据存在“图文无关”现象。
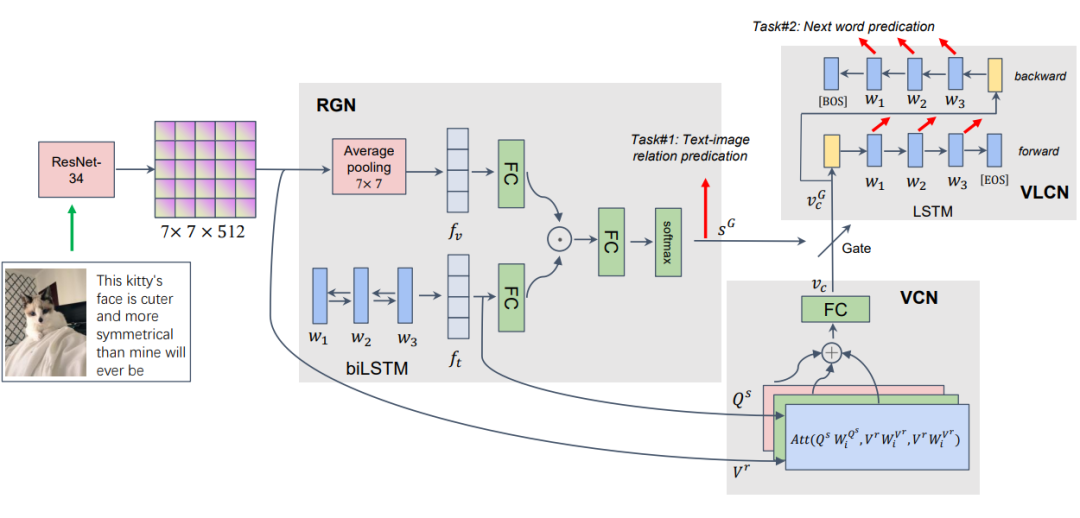
作者的总体思路为:搭建模型,利用文本和图像两种模态的信息,得到一个融合双模态的文本表示。然后作者利用双模态的文本表示在数据集上使用自监督的方式预训练出一个语言模型。具体来看,作者使用 Bilstm 编码文字的表示,使用 resnet 编码图像的表示。RGN 是用来判断图文关系的模块,作者使用在 Bloomberg 图文匹配数据集上训练的一个模型当做 teacher 模型,RGN 模块当做teacher模型来得到预训练的图文关系判断能力。
VCN 和 Transformer 中的多头注意力部分类似,使用文本信息当做 query,图像信息当做 key 和 value,得到的是视觉信息指导的文本表示序列,然后通过一个线性层得到
。
和图文关系调节因数
相乘得到视觉向量
。
在前向 lstm 中当做头向量,在后向 lstm 中当做尾向量,最终的输出为文本的最终表示。然后使用 Next word prediction 方式对模型进行预训练。
预训练完成后,模型在 MNER 任务上进行微调,使用最终的文本图像融合表示和词向量,拼接,输入到 LSTM 中。
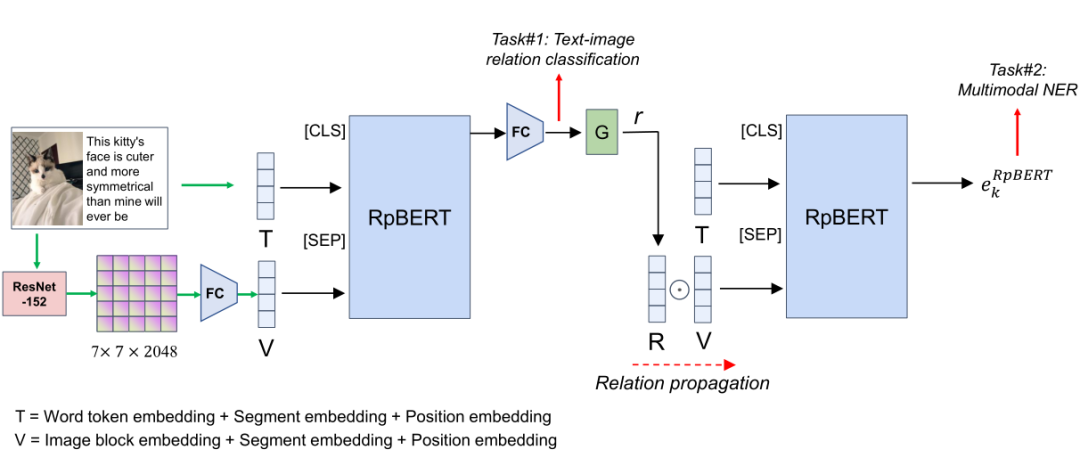
2.3.5 RpBERT
RpBERT: A Text-image Relation Propagation-based BERT Model for Multimodal NER
AAAI 2021
https://arxiv.org/abs/2102.02967
https://github.com/Multimodal-NER/RpBERT
method:作者使用了一个共享参数的多模态 BERT 结构——RpBERT,来同时完成图像-文本关系判断以及图像文本特征的融合。词特征和 resnet 编码的图特征,通过 [SEP] 符号相连,输入到 rpBERT 中,输出的 [CLS] 表示向量用来图像文本分类。和上一篇论文相同,作者同样使用一个外部的数据集上训练了图像文本关系分类器。之后作者根据图文关系的置信度乘以视觉表示,连同词向量一同输入到 RpBERT 进行 NER 任务的训练。
2.3.6 UMGF
Multi-modal Graph Fusion for Named Entity Recognition with Targeted Visual Guidance
AAAI 2021
https://ojs.aaai.org/index.php/AAAI/article/view/17687
https://github.com/TransformersWsz/UMGF
Motivation:使用图像中检测出来的 objects 和文本模态进行交互和融合。
Method:和之前的 MNER 任务使用的图像划分方案不同,本文的作者使用图像目标检测器检测出的 objects 作为图像模态的交互单元。作者使用图神经网络来实现多模态的交互。在构图过程中,每个图像目标作为一个图像节点,每个词当做一个文本节点。除此之外,作者使用了句法解析器来辅助构图。使用图神经网络交互过的两个模态的单元再使用一个双流的 cross-transformer 级联一层交叉的门控机制,然后再经过一个线性层和 CRF,得到最终输出。
总结与展望
本章节为开放环节,欢迎各位小伙伴把自己的想法发到评论区,供大家讨论交流。
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学术热点剖析 、科研心得 或竞赛经验讲解 等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品 ,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬 ,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱: hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02 )快速投稿,备注:姓名-投稿
△长按添加PaperWeekly小编
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧